Streaming IoT Data into Object Storage with Streaming service

Introduction
In the previous post High Frequency Inserts into Oracle Database I demonstrated how you can quickly insert events coming from Internet of Things (IoT) devices into Oracle Database, such as Autonomous Data Warehouse, for operational analytics and data services.
But what if you need to stream data into a Data Lake instead of Oracle Database? What if you need to load IoT events into a Bronze layer in an Object Storage based Data Lake, so that the events may be processed, curated, aggregated, and archived, prior the analytics and publishing? And what if you need to decouple event producers from the Data Lake?
The typical pattern for ingesting large number of concurrent events into a Data Lake is to decouple the event acquisition from the write to the Data Lake. The events are published by many parallel producers into an Event Store with minimal latency, while the write to the Data Lake is batched and delayed, to avoid fragmentation and optimize the storage.
In this post I will show how to use Streaming service to store and manage events produced by multiple parallel producers. I will also demonstrate how to configure Connector Hub to write the events from Streaming into Object Storage bucket for further processing. And finally, I will address the performance of producing messages to Streaming and the Connector Hub write latency.
The usual disclaimer applies. This post is not a benchmark. Your performance will differ, depending on your data model, data distribution, data sizes, configuration, and other parameters. I highly recommend testing performance on your data.
Summary
Provisioning and configuration of both Streaming and Connector Hub is extremely simple. Both services are easy to setup with only few configuration parameters and simple access policies. You can have a fully functional environment in few minutes. Producing and consuming messages with Streaming API/SDK is also simple, with the exception of retry logic, that must be added on top of the API call.
Performance of writing data into a stream in the Streaming service is determined by the number of partitions allocated to the stream and the distribution of data across partitions. A single partition supports write throughput of 1 MB/sec. With data evenly distributed across partitions, the write throughput scales linearly with the number of partitions.
In the use case I tested, I observed a write throughput of about 7.5 MB/sec for the stream with 8 partitions, or about 94% of the theoretical maximum of 8 MB/sec. The events were grouped into batches of 60-100 messages, with the key having the same value for the whole batch. The key was generated randomly across batches.
The important learning is that clients producing messages to Streaming must handle throttling and retry the call in case of failure. You cannot rely on the retry logic in SDK (I used Python SDK), because the rate limiting is applied on the partition and not on the stream level. So, it is entirely possible that some messages in a single API call succeed while others do not.
I did not observe any performance or latency issues with Connector Hub. I used default setting with batch size of 100 MB and batch duration of 7 minutes. With this setup, the Connector Hub generated one file per partition every 7 minutes, as it did not reach the size limit. To lower the latency, you can shorten the batch duration.
Design
Concept
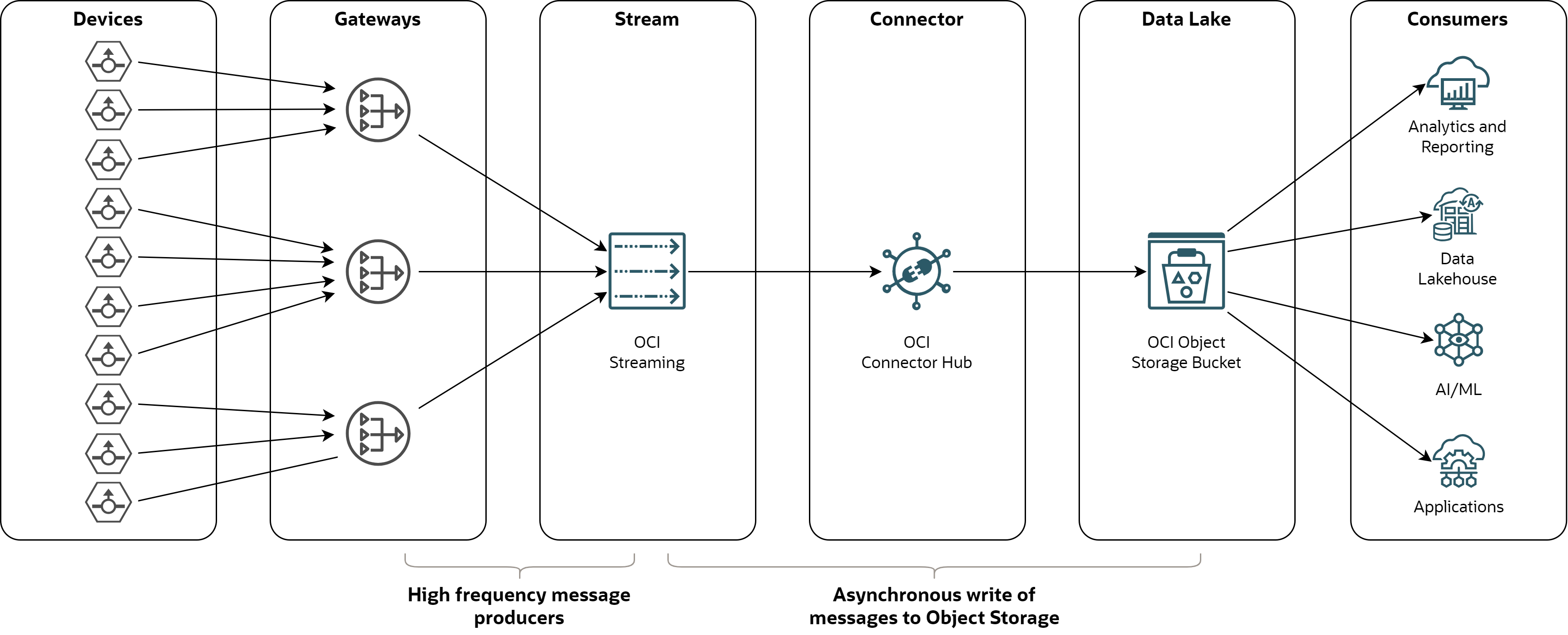
The hypothetical use case I tested is depicted below:
-
Devices - sensors, equipments, machines and other devices that produce events.
-
Gateways - gateways on the edge or in the cloud, which collect events from devices, optionally apply transformations or filtering, and put events into the event store.
-
Stream - event store implemented as append-only log. Messages are distributed across partitions in a stream for scalability. Stream is implemented with Streaming service.
-
Connector - an integration component which consumes messages from a stream, batches them and writes them to files in a data lake. Connector is realized with Connector Hub service.
-
Data Lake - scalable and durable data repository of historical structured and non-structured data. Data Lake is realized as a bucket in Object Storage service.
-
Consumers - various applications using device data, such as analytical tools, data lakehouse, data sharing tools, AI/ML platforms, or other downstream applications.
Simulation
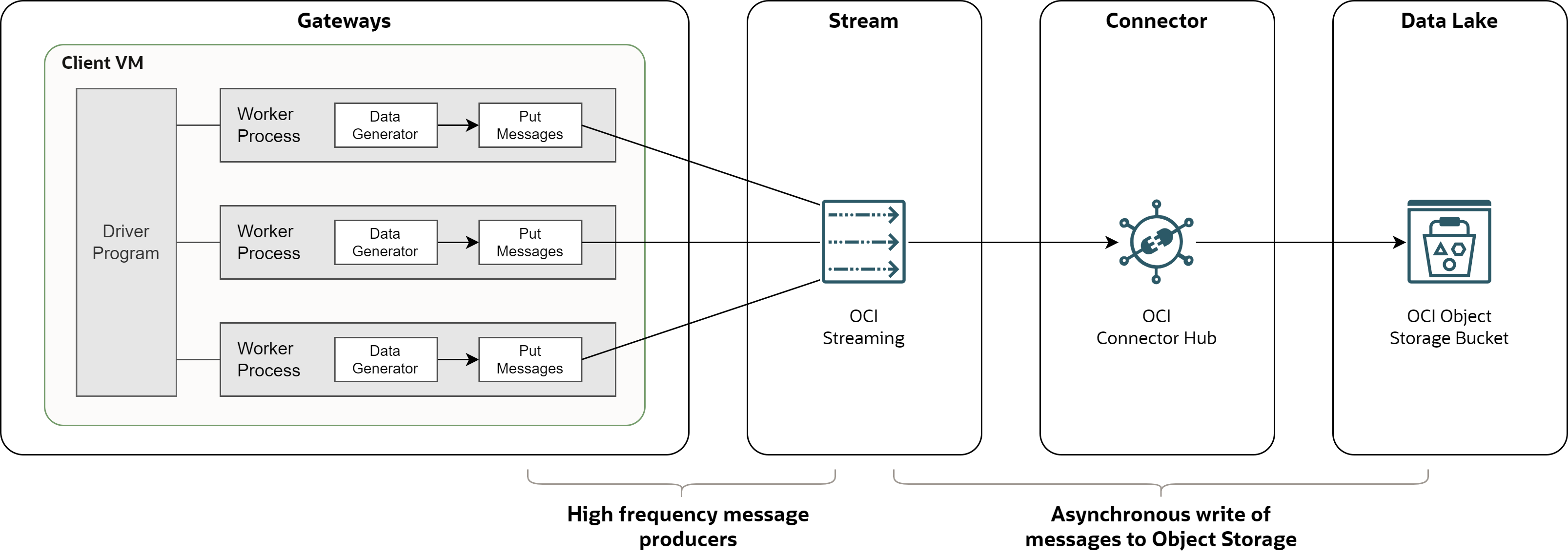
To test the use case, I simulated gateways with Python based load-generator available on Github.
-
Driver - program that initializes the environment, creates and runs requested number of workers, and produces output statistics after all workers finish.
-
Worker - process that generates data and pushes them to Streaming. Every worker works independently. It initializes Streaming client, generates data in a loop, pushes messages to the stream, and applies the retry logic. Number of workers (threads) defines the parallelism of the load.
-
Client VM - single compute instance with with the load-generator and OCI Python SDK.
In the latest version of load-generator, both driver and worker processes are implemented
in the same Python program, using from concurrent.futures import ProcessPoolExecutor for
parallel execution of workers.
Source Data
The generated messages use JSON format which mimics General Ledger transactions, with randomly generated data. The JSON structure is simple, without arrays and nested structures. Example of the payload looks like this:
{
"uuid": "6951e1c8-dfd8-4015-b6fc-477ff4e05e80",
"run_id": "20240628_082841_9009",
"scenario": "stream",
"timestamp": "2024-06-28T08:28:42.253667",
"data": {
"journal_header_source_code": "XTA",
"journal_external_reference": "PNHS3U2WI9772Y0YYRCT",
"journal_header_description": "kqzhnqdijueqpckogsnxoppphwj",
"period_code": "202406",
"period_date": "2024-06-30T00:00:00",
"currency_code": "EUR",
"journal_category_code": "CYN",
"journal_posted_date": "2024-06-28T00:00:00",
"journal_created_date": "2024-06-28T00:00:00",
"journal_created_timestamp": "2024-06-28T08:28:42.252957",
"journal_actual_flag": "Y",
"journal_status": "HEC",
"journal_header_name": "dxuaehgbhlmsfm",
"reversal_flag": "N",
"reversal_journal_header_source_code": "",
"journal_line_number": 1,
"account_code": "A107",
"organization_code": "R776",
"project_code": "P293",
"journal_line_type": "CR",
"entered_debit_amount": 0,
"entered_credit_amount": 5412.339808983113,
"accounted_debit_amount": 0,
"accounted_credit_amount": 5412.339808983113,
"journal_line_description": "jgdbliehmmaqvoqhvfplvptvpfmc"
}
}
When producing messages for Streaming, the above JSON document is provided as the value,
while the field journal_external_reference is provided as the key. Note that
journal_external_reference is the same for all messages (journal lines) in the same
batch (journal). This guarantees that all journal lines in a journal are placed into the
same stream partition and can be later consumed together.
Writing to Streaming
Producing messages into Streaming service is implemented in the
load-generator as the stream scenario.
Prepare Messages
The load-generator uses OCI Python SDK procedure StreamClient.put_messages() to emit messages to the stream.
A single call to the procedure writes multiple messages to the stream. Both payload
(value) and key must be Base64 encoded and converted into
oci.streaming.models.PutMessagesDetailsEntry object. The array of messages is then
converted to oci.streaming.models.PutMessagesDetails object, which is passed to the
put_messages() procedure. The encoding logic is demonstrated in the code below.
def run_streaming(p_params, p_context, p_scenario_name, p_run_id):
# Generate data
try:
v_data_array = get_journals(p_params["iterations"], p_params["minrec"], p_params["maxrec"])
except Exception as e:
g_logger.warning ('Data generator failed with exception; {0}'.format(e))
raise
v_data_count = 0
v_failure_count = 0
v_timestamp = datetime.datetime.today()
v_data = []
v_data_size = 0
v_encoded_size = 0
# Create array of messages for streaming
for v_data_line in v_data_array:
v_value = {
'uuid': str(uuid.uuid4()),
'run_id': p_run_id,
'scenario': p_params['scenario'],
'timestamp': v_timestamp.isoformat(),
'data': v_data_line
}
v_value_string = json.dumps(v_value)
v_key_string = v_data_line['journal_external_reference']
v_value_encoded = b64encode(v_value_string.encode()).decode()
v_key_encoded = b64encode(v_key_string.encode()).decode()
v_data_size = v_data_size + (len(v_value_string)+len(v_key_string))
v_encoded_size = v_encoded_size + (len(v_value_encoded)+len(v_key_encoded))
v_data.append(oci.streaming.models.PutMessagesDetailsEntry(key=v_key_encoded, value=v_value_encoded))
v_data_count = v_data_count+1
v_messages = oci.streaming.models.PutMessagesDetails(messages=v_data)
# Put messages to the stream
(v_retry_count, v_data_count, v_success_count, v_failure_count) = put_messages_with_retry(
p_streamclient=p_context['streamclient'],
p_stream_id=p_params['topic'],
p_messages=v_messages,
p_data=v_data,
p_max_retries=8
)
return v_success_count, v_failure_count, v_data_size, v_encoded_size
Retry Strategy
Although the procedure put_messages() has, like most of OCI procedures, retry_strategy
parameter to handle retries, it is necessary to implement custom retry process. The reason
is that the procedure writes multiple messages into the stream in a single call, and each
message could be mapped to a different partition. And since API rate limiting is
implemented on the partition level, it is possible that some messages are successfully
written into the stream, while the others are throttled.
The retry procedure applies exponential backoff approach, which retries the OCI put_messages()
procedure for messages which were not written to the stream. The maximum number of retries
is 8 and maximum sleep time is 3 seconds. The implementation is below.
def put_messages_with_retry(p_streamclient, p_stream_id, p_messages, p_data, p_max_retries):
# Put messages to the stream
v_retry_count = 0
v_sleep_base_time_sec = 30/1000
v_sleep_max_time_sec = 3
v_sleep_total_sec = 0
try:
v_put_message_result = p_streamclient.put_messages(
stream_id=p_stream_id,
put_messages_details=p_messages,
retry_strategy=oci.retry.DEFAULT_RETRY_STRATEGY
)
v_data_total_count = len(v_put_message_result.data.entries)
v_data_failure_count = v_put_message_result.data.failures
v_data_success_count = v_data_total_count - v_data_failure_count
except Exception as e:
g_logger.error ('Put messages failed with exception: {0}'.format(e))
raise
# Retry for the failed messages
while v_data_failure_count > 0 and v_retry_count <= p_max_retries:
v_exponential_backoff_sleep_base = min(v_sleep_base_time_sec * (2 ** v_retry_count), v_sleep_max_time_sec)
v_sleep_time = (v_exponential_backoff_sleep_base / 2.0) + random.uniform(0, v_exponential_backoff_sleep_base / 2.0)
time.sleep(v_sleep_time)
v_retry_data = []
v_retry_count = v_retry_count+1
v_sleep_total_sec = v_sleep_total_sec + v_sleep_time
for v_entry_index in range(len(v_put_message_result.data.entries)):
v_entry = v_put_message_result.data.entries[v_entry_index]
if v_entry.error:
v_retry_data.append(p_data[v_entry_index])
v_retry_messages = oci.streaming.models.PutMessagesDetails(messages=v_retry_data)
try:
v_put_message_result = p_streamclient.put_messages(
stream_id=p_stream_id,
put_messages_details=v_retry_messages,
retry_strategy=oci.retry.DEFAULT_RETRY_STRATEGY
)
v_data_retry_count = len(v_put_message_result.data.entries)
v_data_failure_count = v_put_message_result.data.failures
v_data_success_count = v_data_success_count + (v_data_retry_count - v_data_failure_count)
except Exception as e:
g_logger.error ('Put messages failed with exception: {0}'.format(e))
raise
return v_retry_count, v_data_total_count, v_data_success_count, v_data_failure_count
Configuration
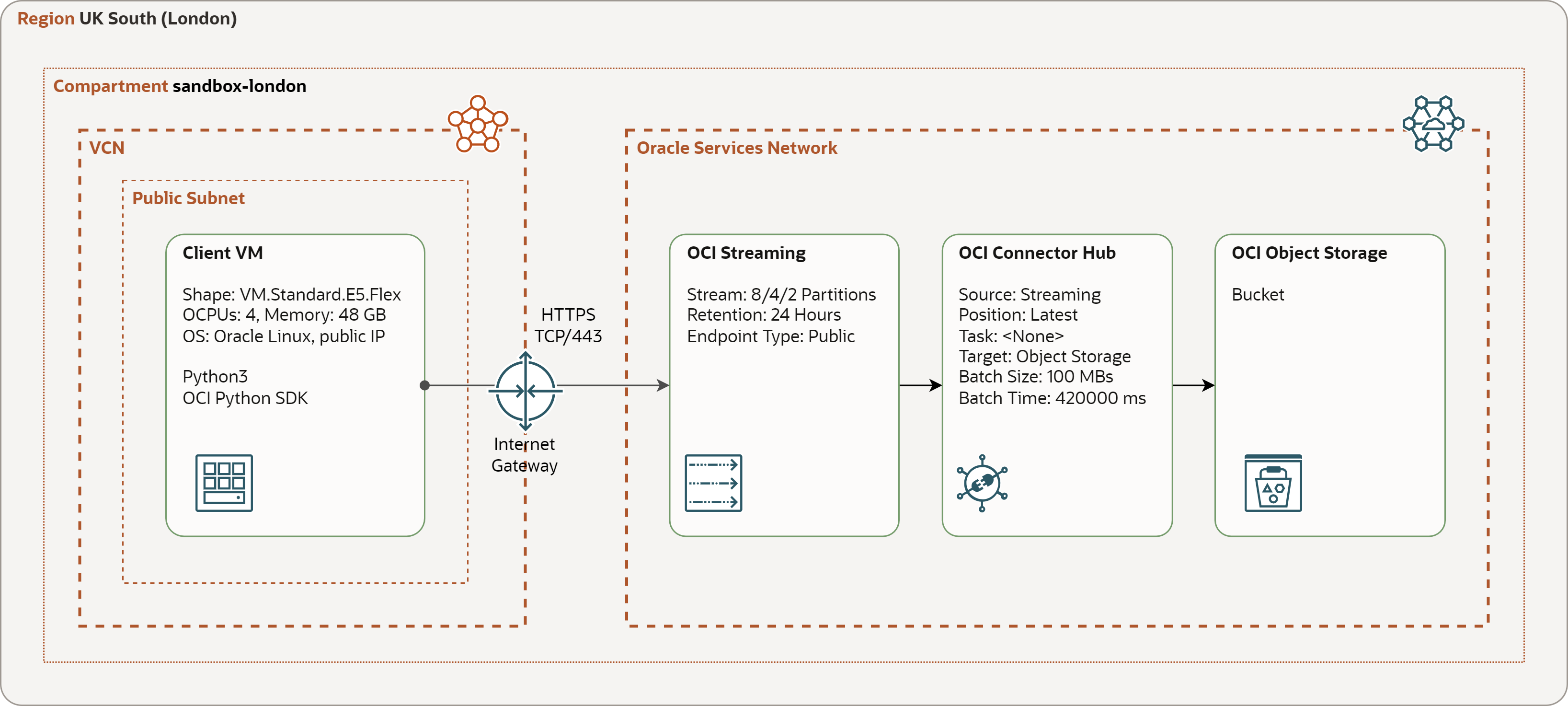
The test configuration consists of Compute VM with the load generator program, Streaming instance (stream), Connector Hub instance (connector), and Object Storage bucket. All components are deployed in the OCI region UK South (London).
-
Compute VM - VM.Standard.E5.Flex shape with 4 OCPUs and 48 GB of memory, running Oracle Linux 8, Python 3.9 and OCI Python SDK. The VM is placed in a public subnet.
-
Streaming - streams with 2/4/8 partitions, maximum write throughput of 2/4/8 MB/sec, maximum read throughput of 4/8/16 MB/sec, public endpoint, and retention of 24 hours.
-
Connector Hub - separate instances for every stream, with stream as the source, Object Storage bucket as the target, and default rollover parameters of 100 MB and 42000 ms (7 minutes).
-
Object Storage Bucket - single bucket for all the streams. Every instance of Connector hub places files into separate folders in the bucket.
-
Connectivity - Compute VM accesses Streaming API over HTTPS. The traffic is routed over Internet Gateway.
Policies
There are two sets of policy statements required for the above setup to work. The first statement allows the load generator to write messages to the stream. Note the load generator authenticates as user principal, using API key. Alternatively, it could be modified to use instance principal.
allow group <group> to use stream-push in compartment id <compartment_OCID>
where target.stream.id = '<stream_OCID>'
The second set of statements allow Connector Hub to read messages from the stream and write files into Object Storage bucket.
allow any-user to {STREAM_READ, STREAM_CONSUME} in compartment id <compartment_OCID>
where all {request.principal.type='serviceconnector', target.stream.id='<stream_OCID>',
request.principal.compartment.id='<compartment_OCID>'}
allow any-user to manage objects in compartment id <compartment_OCID>
where all {request.principal.type='serviceconnector', target.bucket.name='streaming-ingestion-bucket',
request.principal.compartment.id='<compartment_OCID>'}
Observations
Writing to Streaming
Execution Parameters
I tested the throughput for combination of 2, 4, and 8 partitions and 1, 2, 4, and 8
workers (threads). The test duration was 10 minutes for every combination of partitions
and workers. There was no think time between put_messages() calls.
Write Throughput
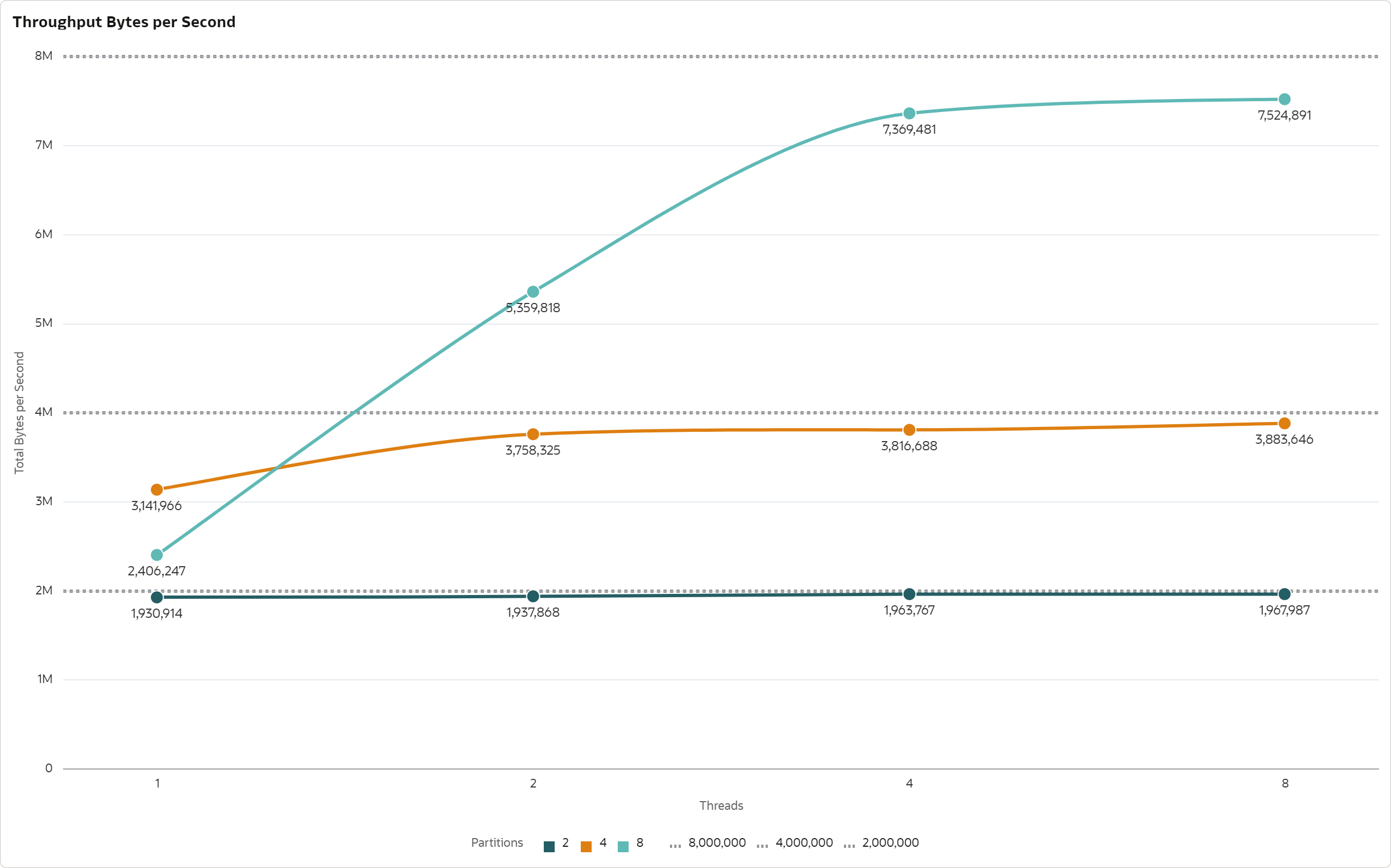
The write throughput is defined as number of bytes written successfully to the stream in 1 second. I calculated this metric as total size of successfully written messages divided by the test duration in seconds. Size of a message is given by the size of the value plus the key, before the Base64 encoding.
-
The write throughput for 2 partitions was over 1.9 MB/sec, for 4 partitions the throughput was over 3.7 MB/sec, and for 8 partitions over 7.3 MB/sec.
-
The write throughput scales linearly with the number of partitions, although it reaches only 94-96% of the theoretical maximum of 1 MB/sec per partition.
-
The reason why the throughput does not reach 100% of theoretical maximum is the imperfect distribution of messages across partitions and the fact that rate limiting is applied on partition and not on stream level.
-
A single client thread is able to fully saturate 2 partitions. More than 1 thread per 2 partitions leads to throttling, not to higher throughput.
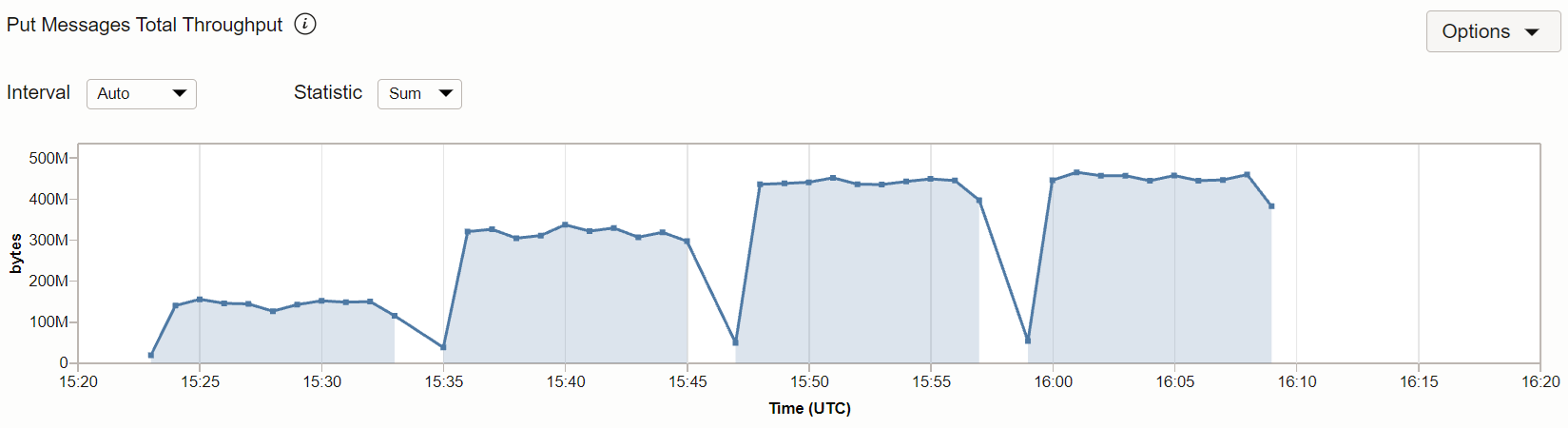
The measured throughput corresponds to the Streaming metric
PutMessagesThroughput.Bytes[1m]{resourceId = "<stream_OCID>"}.sum()
as you can see for the test with 8 partitions. The metric is in minutes; to get the average throughput in seconds it has to be divided by 60.
Write Throttling
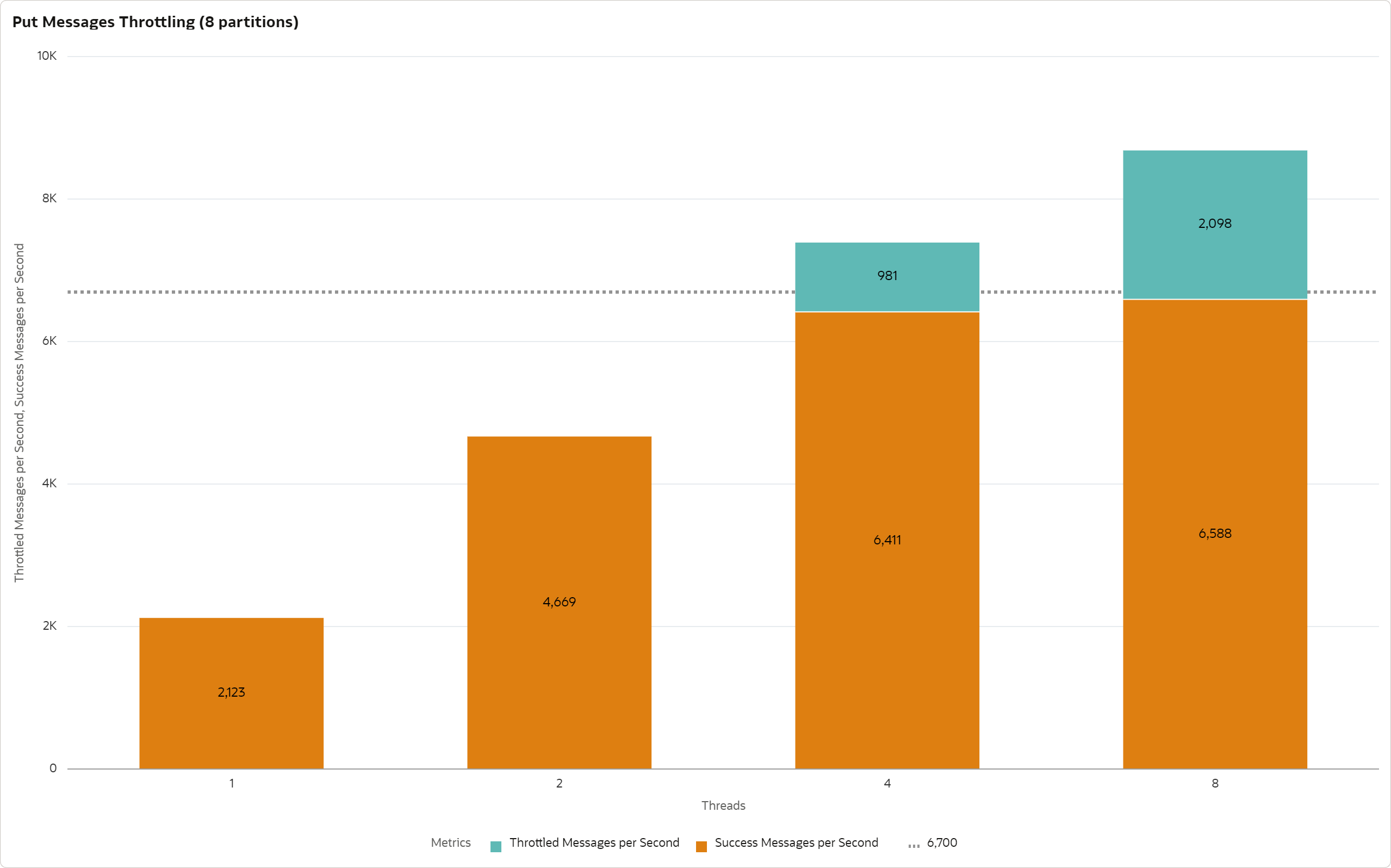
Write throttling happens when the load generator attempts to write with higher rate than what is
supported for the given stream. In this case some messages are throttled with status 429
Too Many Requests and it is necessary to retry the put_messages() call for them.
-
For the stream with 8 partitions the throttling can be observed when the number of threads is 4 or more. For 1 and 2 threads there is no throttling, as we did not reach the throughput limit. This is aligned with the observation that single thread can saturate 2 partitions.
-
Number of throttled messages does not grow linearly. The reason is that throttled messages are retried and the retry logic applies exponential backoff approach. In other words, the more throttled messages there are, the more time the load generator spends sleeping between retries.
-
If we increase number of threads to 8 and more, some messages will be lost as 8 retries is not enough to keep the rate below the stream limit. We would need to increase the stream limit (or increase the number or duration of retries) to prevent this happening.
Storing Messages in Object Storage
Connector Hub Latency
Connector Hub produces Data Freshness metric to measure the age of the oldest processed record in the most recently read data set. For connectors continuously reading and writing messages this metric shows the latency between the availability of data in the source and the target.
DataFreshness[1m]{connectorId = "<connector_hub_OCID>"}.mean()
Unfortunately, in the case of Streaming to Object Storage connector, the messages are written to the target in batches and the Data Freshness metric is meaningless, as a single batch consists of multiple data sets.
Latency is therefore given by the rollover configuration paramaters - batch size (default is 100 MB) and batch duration (default is 420000 ms or 7 minutes) - that define how frequenty are files written to the Object Storage.
In our case, you can see that the latency was about 7 minutes, as the message rate and size did not reach the batch size limit.
+------------------------------------------------------------------------------------------------------------------+
| name | size | time-created |
+------------------------------------------------------------------------------------------------------------------+
| <connector_hub_OCID>/0/20240628T082842Z_20240628T083550Z.0.data.gz | 51505308 | 2024-06-28T08:35:52.264000+00:00 |
| <connector_hub_OCID>/0/20240628T083550Z_20240628T084259Z.0.data.gz | 37801993 | 2024-06-28T08:43:01.213000+00:00 |
| <connector_hub_OCID>/0/20240628T084300Z_20240628T085002Z.0.data.gz | 52240781 | 2024-06-28T08:50:04.936000+00:00 |
| <connector_hub_OCID>/0/20240628T085002Z_20240628T085706Z.0.data.gz | 37548676 | 2024-06-28T08:57:08.280000+00:00 |
| <connector_hub_OCID>/0/20240628T085707Z_20240628T090242Z.0.data.gz | 42410294 | 2024-06-28T09:04:15.746000+00:00 |
| <connector_hub_OCID>/0/20240628T090442Z_20240628T091147Z.0.data.gz | 53608638 | 2024-06-28T09:12:01.921000+00:00 |
| <connector_hub_OCID>/0/20240628T091147Z_20240628T091442Z.0.data.gz | 21981862 | 2024-06-28T09:19:10.819000+00:00 |
| <connector_hub_OCID>/1/20240628T082842Z_20240628T083550Z.0.data.gz | 51067001 | 2024-06-28T08:35:54.395000+00:00 |
| <connector_hub_OCID>/1/20240628T083550Z_20240628T084302Z.0.data.gz | 37652032 | 2024-06-28T08:43:03.594000+00:00 |
| <connector_hub_OCID>/1/20240628T084302Z_20240628T085009Z.0.data.gz | 52175689 | 2024-06-28T08:50:12.127000+00:00 |
| <connector_hub_OCID>/1/20240628T085010Z_20240628T085727Z.0.data.gz | 39018021 | 2024-06-28T08:57:32.821000+00:00 |
| <connector_hub_OCID>/1/20240628T085728Z_20240628T090443Z.0.data.gz | 38847097 | 2024-06-28T09:04:47.664000+00:00 |
| <connector_hub_OCID>/1/20240628T090446Z_20240628T091147Z.0.data.gz | 53488698 | 2024-06-28T09:11:56.386000+00:00 |
| <connector_hub_OCID>/1/20240628T091147Z_20240628T091443Z.0.data.gz | 22346226 | 2024-06-28T09:19:11.531000+00:00 |
+------------------------------------------------------------------------------------------------------------------+
Structure of Target Files
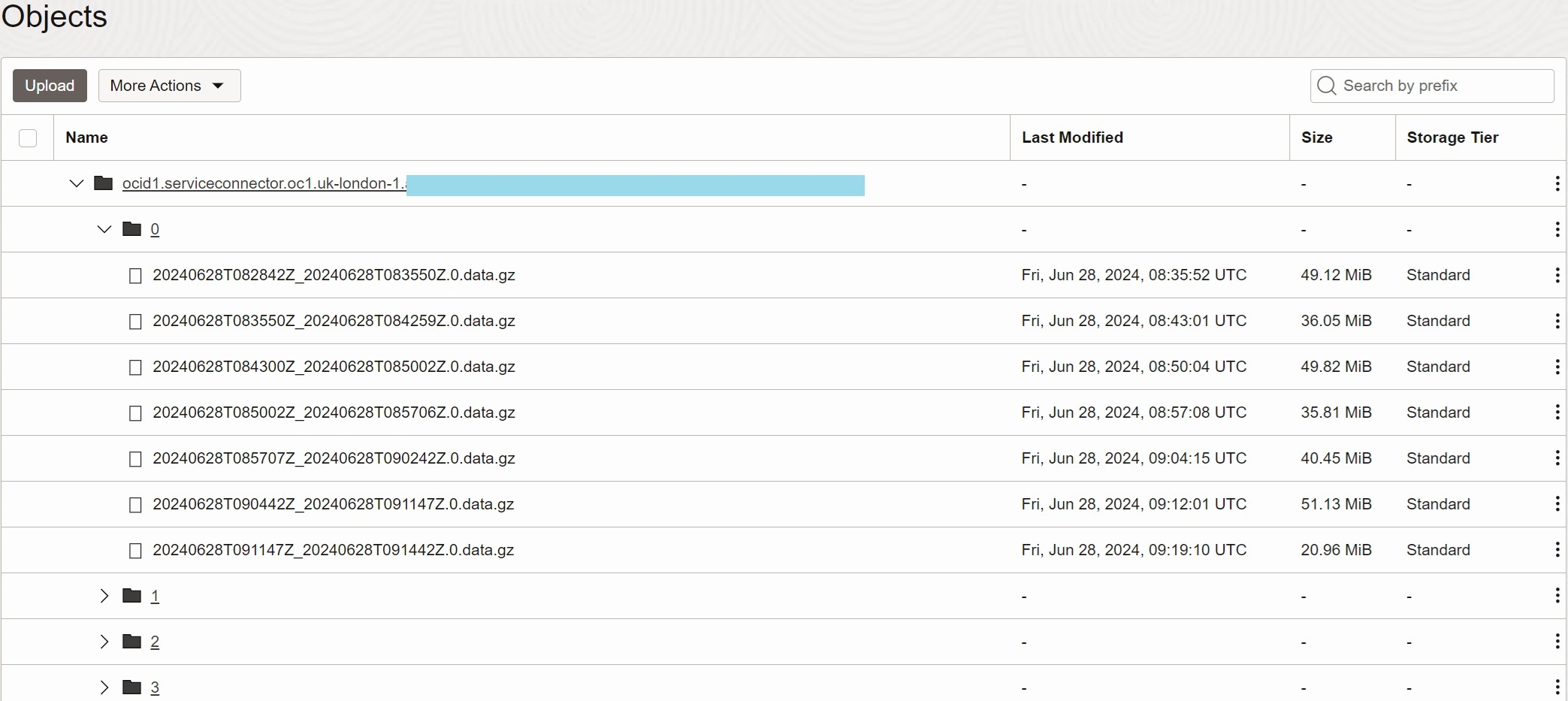
When configuring Connector Hub for writing to Object Storage target, you must provide the bucket for generated objects and optionally the file prefix. Connector Hub will produce objects into the selected bucket with the following structure:
-
Connector Hub - The top folder is OCID of the Connector Hub instance.
-
Partition - The next sub-folder is the partition number. The Connector Hub will create sub-folder for every Stream partition, starting with 0, 1, etc.
-
Object Name - generated files are stored in partition sub-folders. The name contains optional prefix (not shown), start timestamp, end timestamp, and
data.gzsuffix. -
Compression - files are compressed using Gzip compression.
Structure of Target Messages
Once decompressed, the files contain messages in JSON Lines format, with every line having the following structure.
{
"stream": "jakub-stream-london-4",
"partition": "3",
"key": "UE5IUzNVMldJOTc3MlkwWVlSQ1Q=",
"value": "eyJ1dWlkIjog...R2cGZtYyJ9fQ==",
"offset": 1919522,
"timestamp": 1719563322261
}
- stream - name of the source Stream.
- partition - number of the Partition the message was placed in.
- key - Base64 encoded key.
- value - Base64 encoded value, i.e., payload of the message. The example is shortened.
- offset - offset of the message in the Partition.
- timestamp - timestamp of the message in the Unix Epoch format.
As you can see, before analyzing and processing the payload, it is necessary to postprocess the files, by applying decompression and decoding the key and value into the original format. This could be done automatically using Events and Functions, however it is not part of this post.
Considerations
Changes in Streaming Configuration
For your workload, you might want to consider the following changes in the configuration of Streaming. You must test the throughput with your data to get realistic figures.
-
Select a key that will guarantee even distribution of messages across partitions and which is aligned with the way how messages will be consumed.
-
If you do not require to consume messages with the same key together, you do not need to provide a key. Streaming will detect the null key and it will generate random key per message, providing perfect distribution of messages.
-
Create Stream with number of partitions corresponding to the amount of data you need to process. Size for peak utilization and add contingency to avoid throttling during unexpected loads.
-
If the amount of data grows beyond the capacity given by the number of partitions, you will have to provision a new stream with higher number of partitions and redirect producers and consumers to this stream. Streaming does not support scaling number of partitions currently.
-
Instead of using OCI Streaming API or SDK for publishing messages, you can use Kafka APIs instead. Please refer to Using Streaming with Apache Kafka for more information.
Changes in Connector Hub Configuration
You might also want to change the configuration of Connector Hub for writing data into the Object Storage.
-
Modify the default parameters specifying how often Connector Hub writes to Object Storage. Default batch size is 100 MB and default batch duration is 7 minutes (420000 ms). If either the size or the time exceed the limit, Connector Hub will produce new file.
-
You may optionally add a Function task to process or filter source messages before they are written to the target.
-
You cannot specify the capacity of the Connector Hub currently. If you exceed the capacity of the connector hub (I did not reach the capacity during the testing), you may need to use an alternative technology (such as Oracle GoldenGate, Oracle Integration, or Kafka Connect) for higher throughput.
Resources
- OCI Streaming: Streaming Documentation.
- OCI Streaming Python SDK: Streaming Python API Reference Documentation.
- OCI Connector Hub: Connector Hub Documentation.
- Program to test high frequency writes: load-generator.