High Frequency Inserts into Oracle Database

Introduction
To bulk load large amount of data into Oracle Database, you typically use Direct Path Load. This approach uses optimized, direct path API, which bypasses conventional INSERT path, and formats and writes database blocks directly to the database. For example, Direct Path Load may be used to load large data sets from Object Storage into Autonomous Data Warehouse via external tables or DBMS_CLOUD.COPY_DATA utility.
But there are cases when the Direct Path Load is not appropriate. Consider an Internet of Things (IoT) workload, with devices generating huge amount of events. These events have to be inserted to Oracle Database with minimal latency, to support operational analytics and data services. If we use Direct Path Load, we would need to batch the events before loading, and the latency would suffer.
In this blog post I compare 4 methods of inserting data into Oracle Database. 3 standard methods that use a conventional INSERT path, and a “Fast Ingest” method which was introduced in Oracle Database 19c. I am interested in the insert performance and scalability of these methods, whether these methods support compression, and for which use cases they are suitable.
Note this post is not a benchmark. My objective is a comparison of methods with out-of-the-box setup; not finding the fastest insert performance on a tuned system. Your performance will differ, depending on your data model, data distribution, data sizes, configuration, and other parameters. I highly recommend you test performance on your data.
Summary
With out-of-the-box configuration of Autonomous Data Warehouse (ADW), with data model and loading program not specifically tuned and optimized for the high-frequency load, and with real-life data model with JSON payload I observed
- Insert throughput of 173k records per second with Fast Ingest and 16 parallel threads.
- Insert throughput of 118k records per second with Array Interface and 24 parallel threads.
This throughput was achieved with the following configuration:
- Autonomous Data Warehouse Serverless, with 16 ECPUs, Autoscaling disabled, and public access.
- Compute VM with 16 OCPUs, running Oracle Linux and the load load generator client.
- Python3 based load generator, using python-oracledb package and LOW service.
- Single non-partitioned and not indexed target table with JSON payload in VARCHAR2(4000) column.
- Average record size of 1360 bytes with randomly generated data.
- No other workloads were running on both the ADW and Compute instances.
With Array Interface, data was compressed with HCC, achieving compression ratio of 5-6x. Fast Ingest does not support compression in 19c - it is coming with Oracle Database 23c.
Based on the observations described in the post, I recommend
-
Using Fast Ingest method in case your workload does not require durability guarantee. Fast Ingest provides the best insert throughput, but there is a chance of data loss if for example the instance crashes before newly inserted data is written from the large pool to the target table.
-
Using Array Interface if you require standard durability guarantee and transaction handling. Inserting data with Array Interface has lower throughput than Fast Ingest, but there are no limitations regarding the transaction behaviour, structure of the target table, or the insert statement.
-
Do not use single row insert (Single and Batch scenarios), as this method has by far the lowest throughput and it does not provide any other benefits compared to Array Interface. (The reason I included it in the comparison is mostly to show the difference in throughput.)
Design
Concept
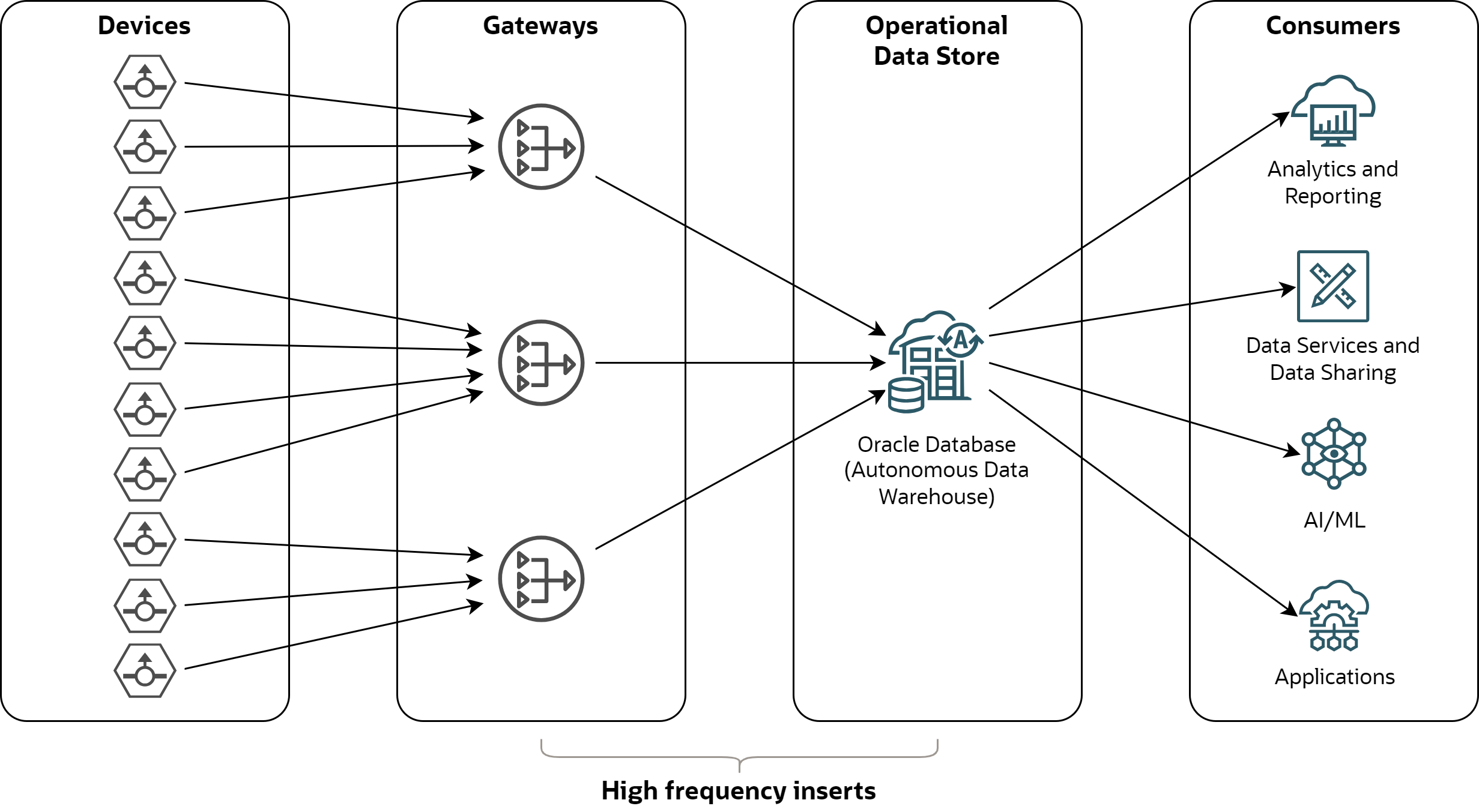
The hypothetical use case I tested is depicted below:
-
Devices - sensors, equipments, machines and other devices that produce events.
-
Gateways - gateways on the edge or in the cloud, which collect events from devices, optionally apply transformations or filtering, and insert events into the data store.
-
Operational Data Store - database storing history of events; querying, analyzing, and serving the events to analytical tools or data services.
-
Consumers - various applications using device data, such as analytical tools, data services, data sharing tools, AI/ML platforms, or other downstream applications.
This post focuses on the methods for high frequency inserts from gateways to the Operational Data Store. It assumes the Operational Data Store is implemented with Oracle Database, particularly with Autonomous Data Warehouse Serverless.
Simulation
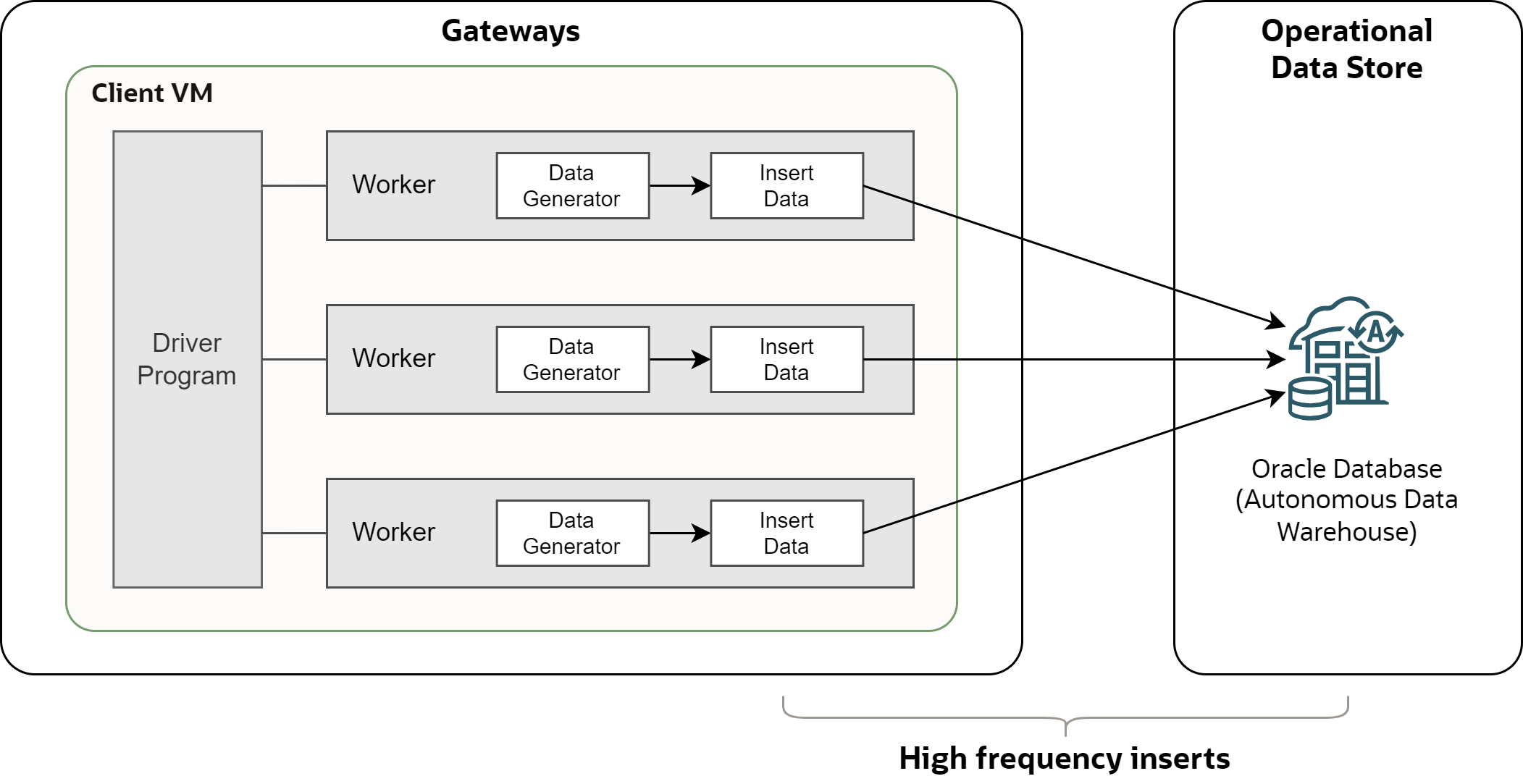
To test the high frequency inserts, I simulated gateways with Python based load-generator available on Github.
-
Worker - program that generates data and inserts them into the database. Every worker opens a single connection to the database and it inserts data sequentially according to the selected scenario. Number of workers (threads) defines the parallelism of the load.
-
Driver - program that initializes the environment, creates and runs requested number of workers, and produces output statistics after all workers finish.
-
Client VM - single compute instance with driver and workers. Note the load-generator does not support distributing workers across multiple compute instances.
Scenarios
I tested the following insert methods:
- Single - Records are inserted into the database one-by-one and immediately committed.
- Batch - Records are inserted into the database one-by-one and committed after a batch of records is inserted.
- Array - Records are inserted into the database in arrays and committed after every array insert.
- Fast - Records are inserted into the database in arrays using the Fast Ingest available in Oracle Database 19c.
Single
This is the “transactional” approach, which inserts data using a single row INSERT statement and immediately commits after the insert. The simplified Python code looks like this:
start_ts = datetime.datetime.today()
while (datetime.datetime.today()-start_ts).total_seconds() <= 600:
data_array = data_generator()
for data_record in data_array:
data_record_js = json.dumps(data_record)
cursor.execute('insert into target_table (ts, payload) values (:ts, :payload)', ts=datetime.datetime.today(), payload=data_record_js)
connection.commit()
Batch
This approach also inserts data using a single row INSERT statement, but it commits the transaction after all records (i.e., batch) returned by the generator are inserted. Compared to the previous option, this method significantly reduces the frequency of COMMITs.
start_ts = datetime.datetime.today()
while (datetime.datetime.today()-start_ts).total_seconds() <= 600:
data_array = data_generator()
for data_record in data_array:
data_record_js = json.dumps(data_record)
cursor.execute('insert into target_table (ts, payload) values (:ts, :payload)', ts=datetime.datetime.today(), payload=data_record_js)
connection.commit()
Array
This approach inserts the whole array of rows in a single call, using the Oracle Database array interface. Data is committed after the array insert. Compared to the previous option, this method significantly reduces generated redo and the network round-trips between the client and Oracle Database.
Note that to use the array interface in Python, it is necessary to use executemany()
instead of execute().
start_ts = datetime.datetime.today()
while (datetime.datetime.today()-start_ts).total_seconds() <= 600:
data_array = data_generator()
insert_array = []
for data_record in data_array:
data_record_js = json.dumps(data_record)
insert_array.append((datetime.datetime.today(),data_record_js))
cursor.executemany('insert into target_table (ts, payload) values (:ts, :payload)', insert_array)
connection.commit()
Fast
This approach uses Fast Ingest, available since Oracle Database 19c. Fast Ingest does not use the conventional path. It buffers data into a special area in the large pool memory and writes them to the target table asynchronously by background processes. This should allow the Fast Ingest to support higher data insertion bandwidth than the other methods.
There is no commit and no rollback with the Fast Ingest. Data is also not durable until written from large pool to the table by background processes, hence this approach is not suitable if you need durability guarantee. See Using the Fast Ingest for more details.
To use Fast Ingest, table must be created or altered with MEMOPTIMIZE FOR WRITE clause.
Also, you need to use hint /*+MEMOPTIMIZE_WRITE*/ in the INSERT statement. Note that in
the Autonomous Database hints are implicitly disabled. Therefore, you must enable hints
with alter session set optimizer_ignore_hints = false prior to using the Fast Ingest.
start_ts = datetime.datetime.today()
while (datetime.datetime.today()-start_ts).total_seconds() <= 600:
data_array = data_generator()
insert_array = []
for data_record in data_array:
data_record_js = json.dumps(data_record)
insert_array.append((datetime.datetime.today(),data_record_js))
cursor.executemany('insert /*+ MEMOPTIMIZE_WRITE */ into target_table (ts, payload) values (:ts, :payload)', insert_array)
Data Model
Target Table
For the test I used single table with few metadata columns and JSON payload. Note the
payload is relatively small, allowing to use VARCHAR2(4000) data type, which is stored
inline in the table and which supports HCC compression of JSON columns.
create table target_table (
id varchar2(40) not null,
run_id varchar2(40) not null,
scenario varchar2(20) not null,
ts timestamp not null,
payload varchar2(4000),
constraint gl_stream_single_is_json check (payload is json)
)
/
- id - unique identifier of the record.
- run_id - identifier of the testing run.
- scenario - scenario being tested in the testing run.
- ts - timestamp when the record was inserted.
- payload - JSON payload.
As I used Autonomous Data Warehouse (ADW) instance for the test, the table supports HCC
compression out of the box. When you check table DDL, you can see it is implicitly created
with COMPRESS FOR QUERY HIGH ROW LEVEL LOCKING clause.
However, as compression is not supported with Fast Ingest, to test the Fast Ingest method
I had to create the target table with NOCOMPRESS MEMOPTIMIZE FOR WRITE clause instead.
Payload
The JSON paylod mimics General Ledger transactions, with randomly generated data. The JSON structure is simple, without arrays and nested structures. Example of the payload looks like this:
{
"journal_header_source_code": "NWJ",
"journal_external_reference": "I9GD11AQ6SGZCIPPV52J",
"journal_header_description": "easdtoqyoldrilnkdupgozmsulhgtmvckddihewacjtxvovvz",
"period_code": "202404",
"period_date": "2024-04-30T00:00:00",
"currency_code": "EUR",
"journal_category_code": "LFD",
"journal_posted_date": "2024-04-12T00:00:00",
"journal_created_date": "2024-04-12T00:00:00",
"journal_created_timestamp": "2024-04-12T14:10:54.918070",
"journal_actual_flag": "Y",
"journal_status": "DXO",
"journal_header_name": "emsvrgdockdeesyltygsx",
"reversal_flag": "N",
"reversal_journal_header_source_code": "",
"journal_line_number": 60,
"account_code": "A766",
"organization_code": "R714",
"project_code": "P595",
"journal_line_type": "CR",
"entered_debit_amount": 0,
"entered_credit_amount": 8286.994542015054,
"accounted_debit_amount": 0,
"accounted_credit_amount": 8286.994542015054,
"journal_line_description": "ydhyvsakqhhldvpzlhtufnbtchnubwngmadavupxtmgjwpzegai"
}
Configuration
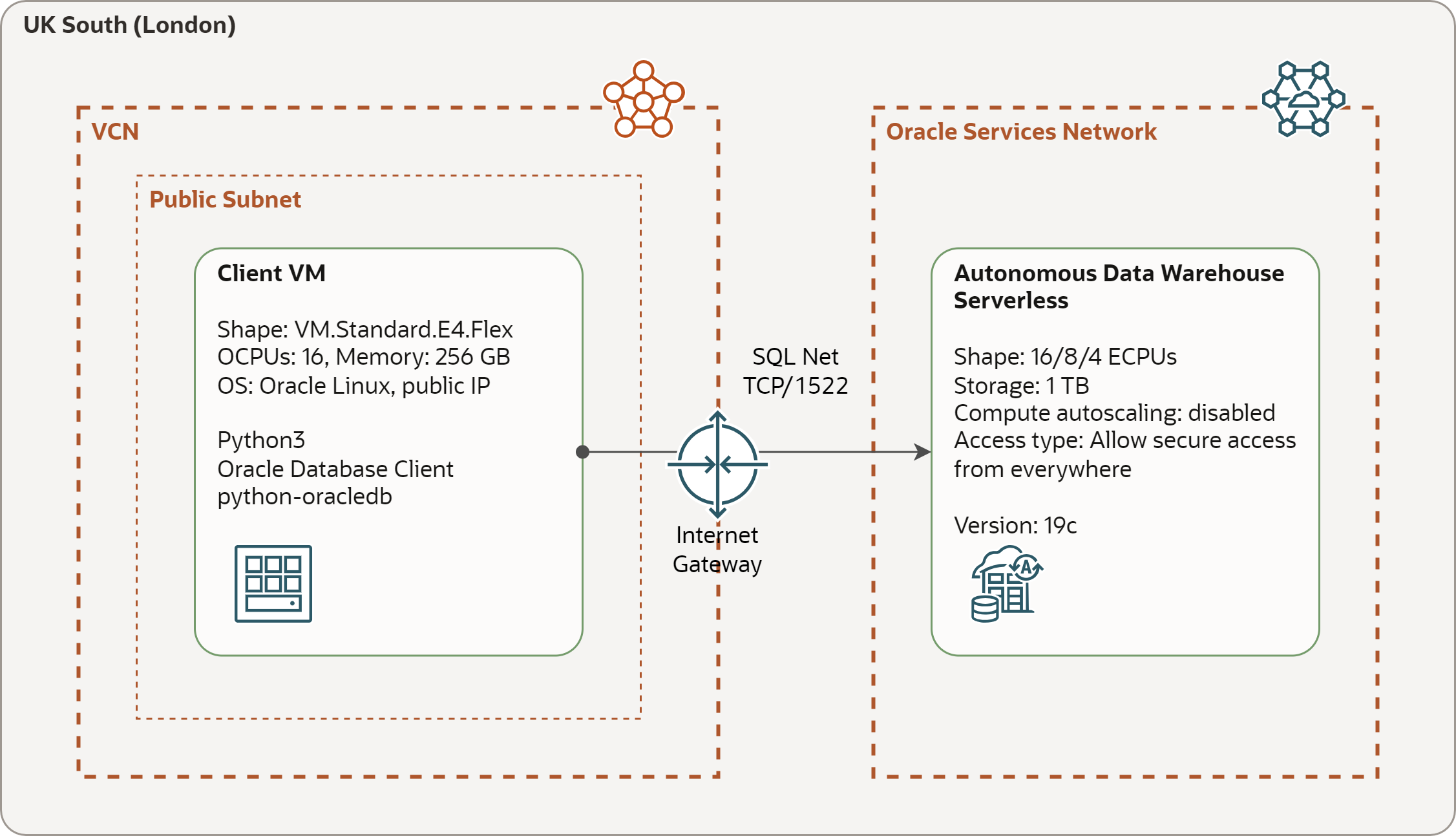
The test configuration consists of an instance of Autonomous Data Warehouse Serverless (ADW) with the target table and Compute VM with the load generator program. Both components are deployed in the OCI region UK South (London).
-
Autonomous Data Warehouse Serverless - configured with 16/8/4 ECPUs (without Autoscaling), 1 TB of storage, and Secure access from anywhere (i.e., without private endpoint and with mandatory mTLS). Note that 4 ECPUs correspond approximately to 1 OCPU, i.e., 16 ECPUs to 4 OCPUs.
-
Compute VM - configured with VM.Standard.E4.Flex shape with 16 OCPUs and running Oracle Linux 7.9. The VM is placed in a public subnet and it communicates with ADW over public IP.
-
Connectivity - Compute VM accesses ADW over SQL Net protocol using TCP and port 1522. The traffic is routed over Internet Gateway.
Execution Parameters
I tested the insert performance for the following combination of parameters:
- Test Duration - 10 minutes (600 seconds).
- Service - LOW (as we generate transactional, not analytical load).
- ADW Shape - 16 ECPUs, 8 ECPUs, 4 ECPUs.
- Scenarios - Single, Batch, Array, Fast.
- Number of Workers (Threads) - 1, 2, 4, 8, 16, 24, 32, 40.
The observed results for 16 ECPUs are in the table Test Results below.
Observations
Insert Throughput
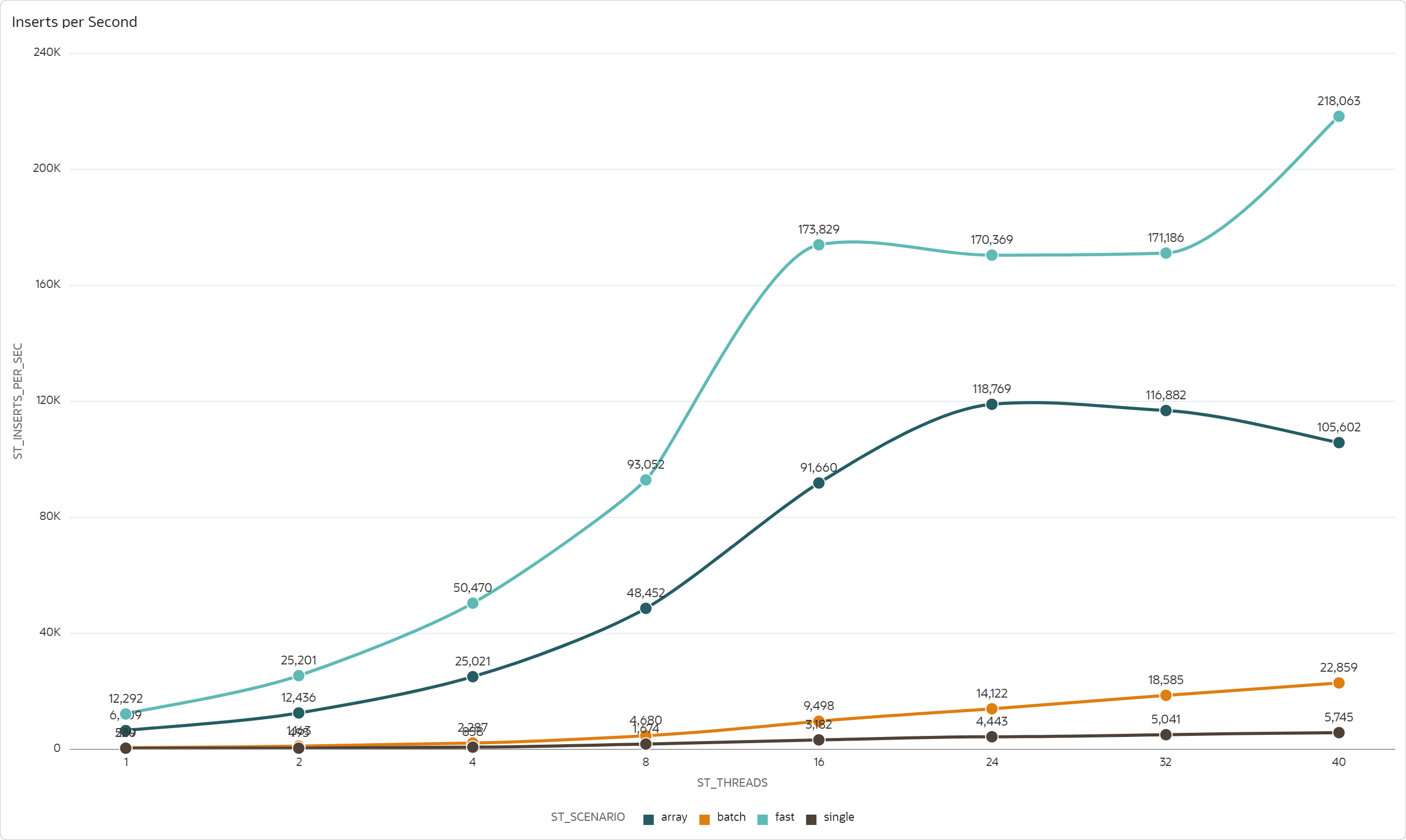
The first metric I was interested in is the overall insert throughput, which I calculated as number of inserted records per one second. For 16 ECPUs, the insert throughput looks like this:
-
Fast scenario provides the best throughput, with peak of 173k records inserted per second by 16 threads, and 218k records inserted by 40 threads respectively.
-
Array scenario comes second, with peak of 118k records inserted per second by 24 threads. Fast scenario has approximately 2x higher throughput for the same number of threads than Array scenario.
-
Batch scenario has significantly lower throughput, with peak of over 22k records inserted per second by 40 threads. Array scenario has almost 10x higher throughput for the same number of threads than Batch scenario.
-
Single scenario provides (unsurprisingly) the worst throughput, with peak of over 5k records inserted per second by 40 threads. Batch scenario has 3-4x higher throughput for the same number of threads than Single scenario.
Insert Throughput per Thread
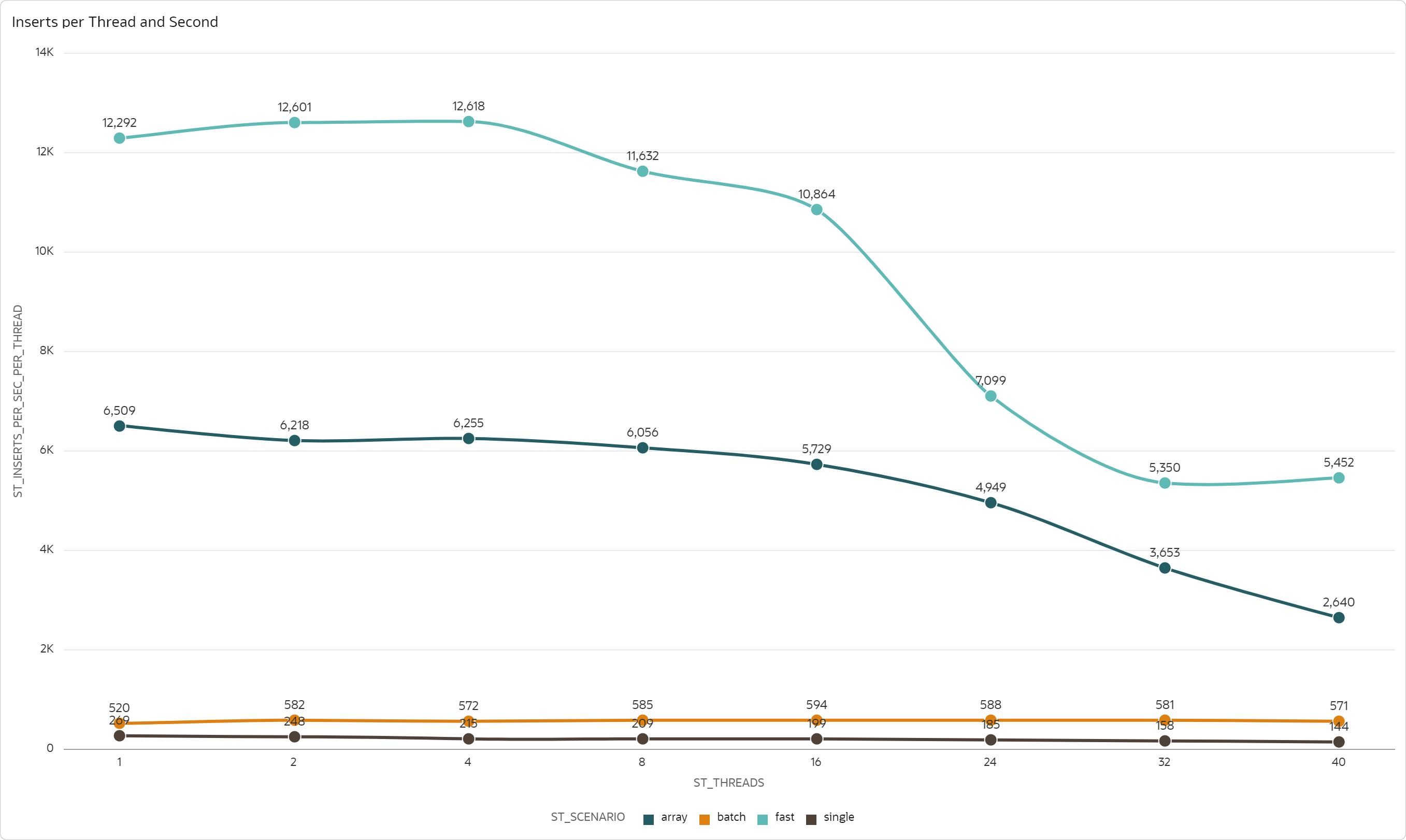
The second metric is an average throughput per thread, measured as number of inserted records per one second by one thread, averaged over the threads. For 16 ECPUs, the insert throughput per thread looks like this:
-
Fast scenario supports over 12k inserts per second and thread, but only up to 4 threads. With higher parallelism the throughput decreases, with significant drop for 24 and more threads.
-
Array scenario supports over 6k inserts per second and thread, but only up to 8 threads. With more parallelism the throughput gradually decreases, with bigger drop for 32 and more threads.
-
Batch scenario supports over 570 inserts per second and thread. This throughput is consistent across the whole range of threads; there is no significant drop.
-
Single scenario supports over 200 inserts per second and thread. This throughput is consistent up to 8 threads, after that the throughput gradually decreases.
Maximum Parallelism for ADW Shape
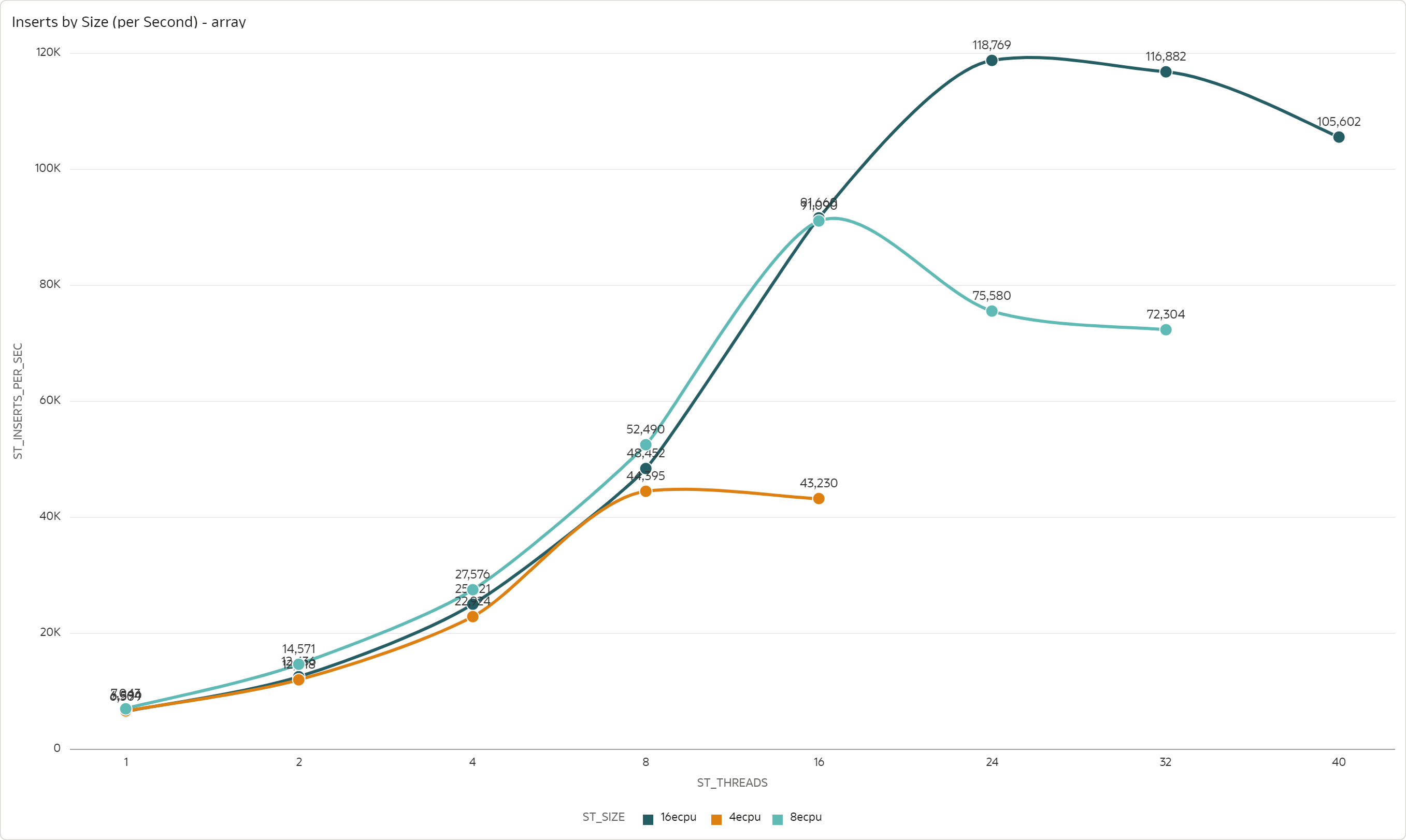
The next chart shows the maximum level of parallelism that an ADW shape can support, tested with 16 ECPU, 8 ECPU, and 4 ECPU shapes. The maximum level of parallelism is defined as maximum number of threads, for which the throughput scales.
For the Array scenario, you can clearly see that the maximum parallelism is 8 threads for 4 ECPUs, 16 threads for 8 ECPUs, and 24 threads for 16 ECPUs:
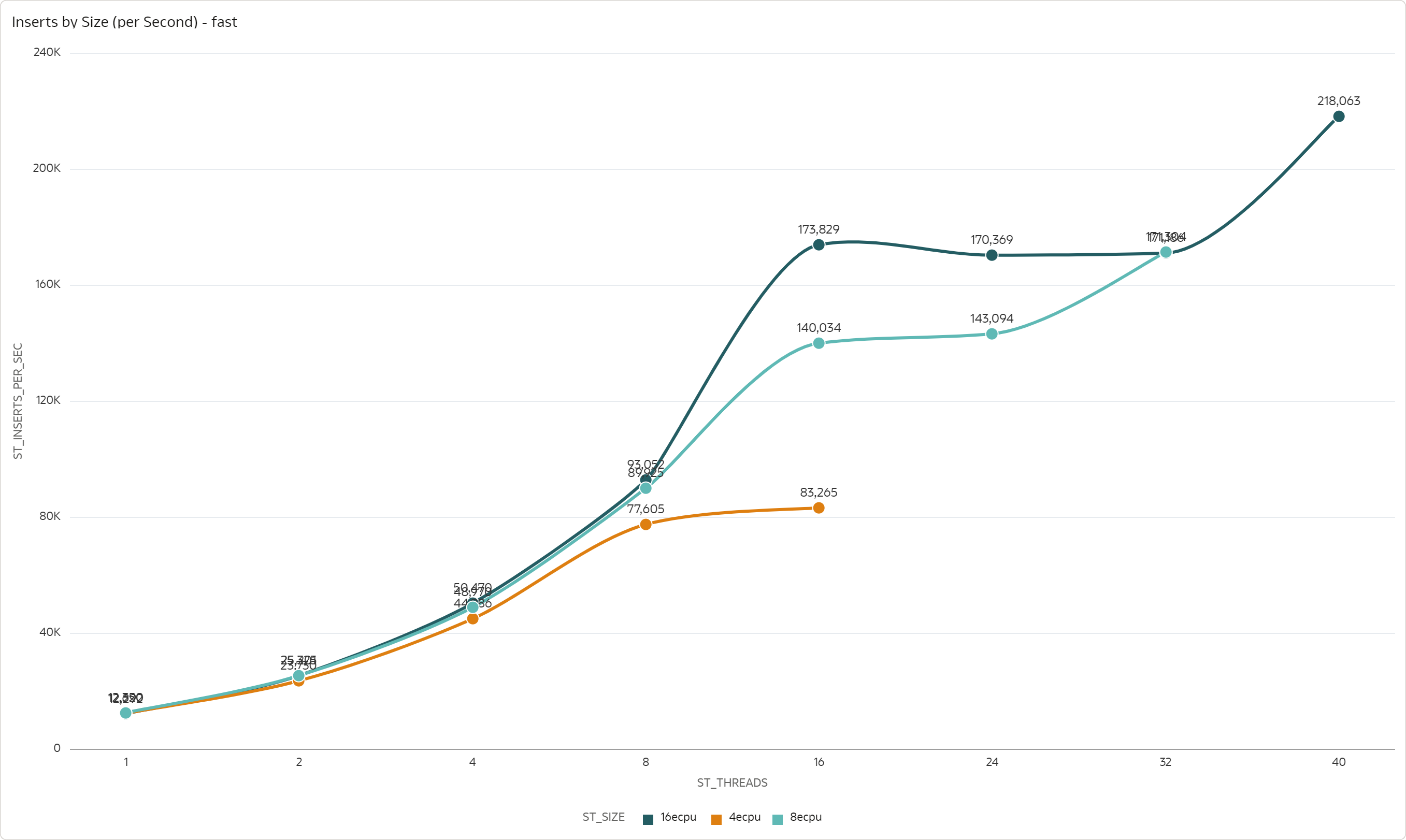
For the Fast scenario, the results are not so obvious. The throughput scales up to 8 threads for 4 ECPUs, 16 threads for 8 ECPUs, and also 16 threads for 16 ECPUs. However, after a dip it seems to grow again.
CPU Utilization of ADW Instance
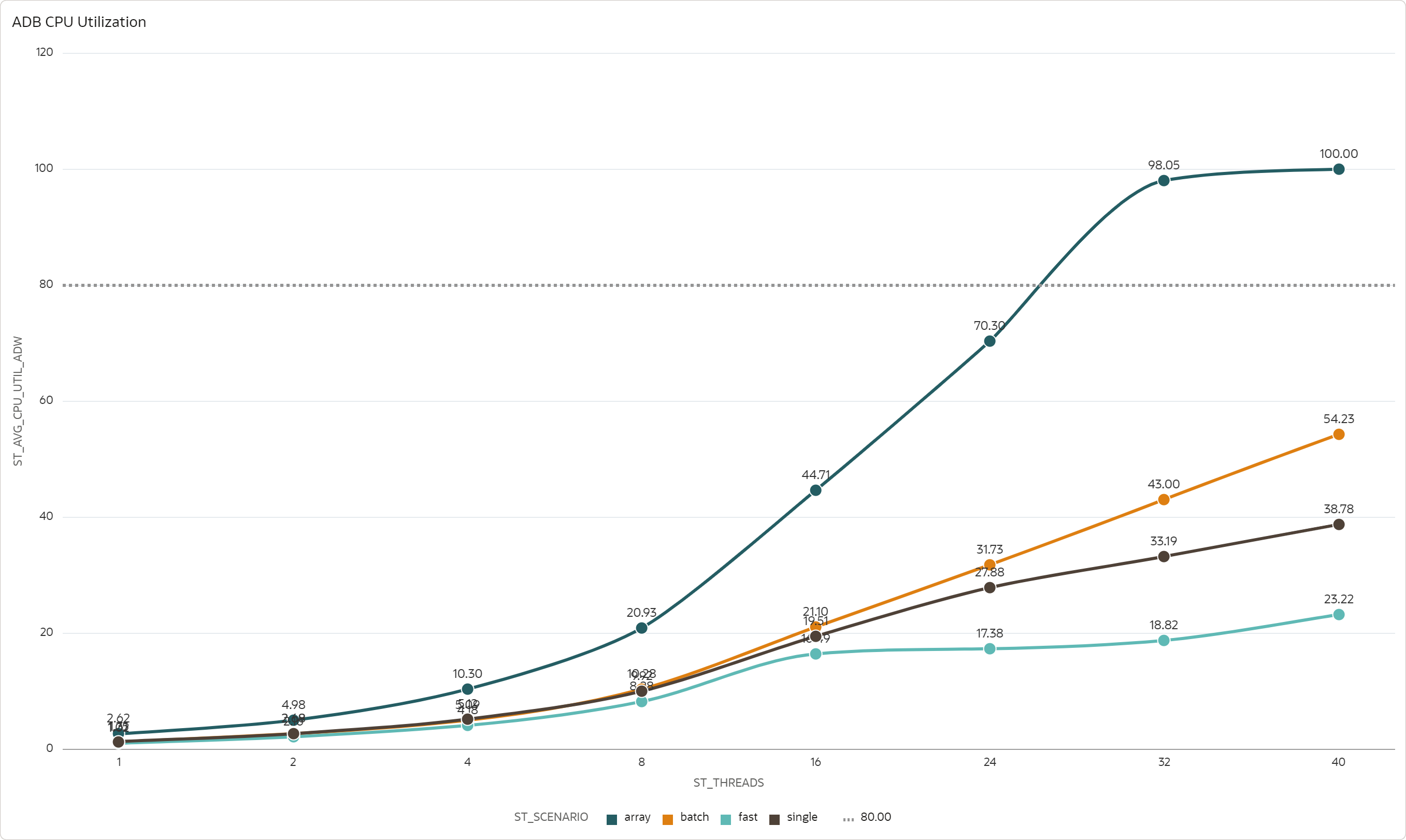
A possible explanation of the throughput behavior observed in previous sections is that with higher parallelism we reach ADW CPU utilization maximum. The following chart shows the median ADW CPU utilization 16 ECPUs.
-
Array scenario is obviously constrained by the ADW CPU utilization. Somewhere between 24 and 32 threads the ADW reaches 80% CPU utilization. This observation is well aligned with the maximum parallelism of 16 threads, i.e., before the ADW CPU is fully utilized.
-
Fast, Batch, and Single scenarios are constrained by some other resource, as there is plenty of spare ADW CPU capacity. Curiously, even though Fast scenario provides the highest throughput, it needs the least amount of ADW CPU.
Data Compression
The final chart shows how much storage is allocated. To compare the results between scenarios with different amount of generated data, I measured average storage required by a single record.
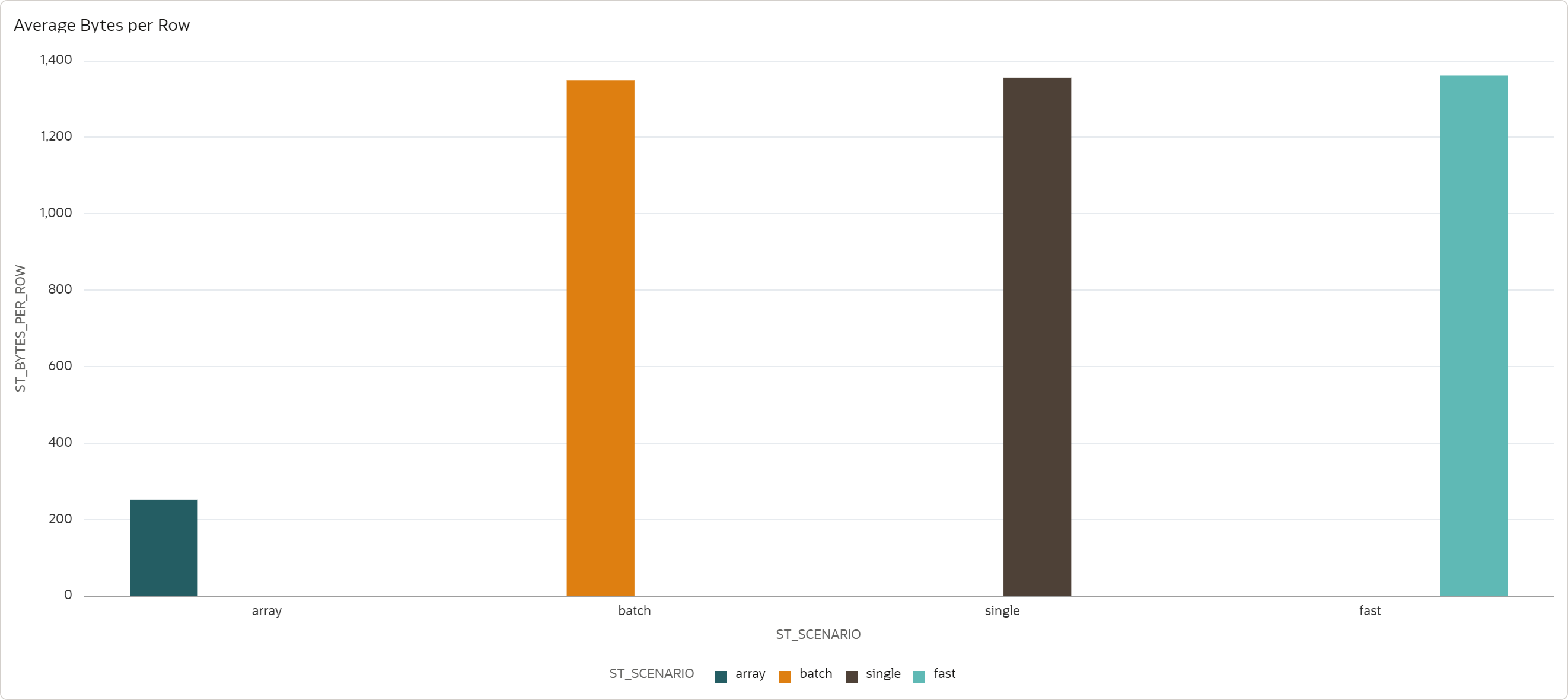
-
Fast, Batch, and Single scenario store data without HCC compression, with average row size of 1360 bytes. This is no suprise - Fast Ingest does not support compression in 19c and the target table must be explicitly created with NOCOMPRESS. And Batch and Single scenarios do not support HCC compression by design (single row insert).
-
Array scenario on the other hand does support HCC compression. I admit I did not expect that. Average row size is 250 bytes, with the compression ratio of 5-6x. The compression ratio highly depends on the data - in our case, descriptive fields are randomly generated, which probably leads to lower ratio than normal data.
Note that Fast Ingest in 23c will support compression, as outlined in the blog Oracle Database 23c Fast Ingest Enhancements.
Test Results
The table shows results that I used for the charts above. Note these results were produced with 16 ECPUs allocated for the ADW instance, with Autoscaling disabled.
| Scenario | Threads | Total Inserts | Inserts per Thread | Inserts per Second | Inserts per Second and Thread | Used Bytes | Bytes per Row | ADW CPU Utilization % | ADW Client Sent Bytes | Client CPU Utilization % |
|---|---|---|---|---|---|---|---|---|---|---|
| single | 1 | 161476 | 161476 | 269 | 269 | 218103808 | 1351 | 1.31 | 17471416 | 0.17 |
| single | 2 | 297206 | 148603 | 495 | 248 | 402653184 | 1355 | 2.68 | 31151767 | 0.3 |
| single | 4 | 514973 | 128743 | 858 | 215 | 696254464 | 1352 | 5.12 | 56239732 | 0.49 |
| single | 8 | 1006353 | 125794 | 1674 | 209 | 1409286144 | 1400 | 9.92 | 108626727 | 0.92 |
| single | 16 | 1909146 | 119322 | 3182 | 199 | 2616197120 | 1370 | 19.51 | 205437397 | 1.94 |
| single | 24 | 2665583 | 111066 | 4443 | 185 | 3587178496 | 1346 | 27.88 | 286919810 | 2.92 |
| single | 32 | 3024726 | 94523 | 5041 | 158 | 4091543552 | 1353 | 33.19 | 320723761 | 3.53 |
| single | 40 | 3447097 | 86177 | 5745 | 144 | 4673503232 | 1356 | 38.78 | 374464698 | 4.05 |
| batch | 1 | 312210 | 312210 | 520 | 520 | 419430400 | 1343 | 1.25 | 33544602 | 0.22 |
| batch | 2 | 697947 | 348974 | 1163 | 582 | 939524096 | 1346 | 2.69 | 74481470 | 0.47 |
| batch | 4 | 1371920 | 342980 | 2287 | 572 | 1866465280 | 1360 | 5.09 | 147525388 | 0.89 |
| batch | 8 | 2807957 | 350995 | 4680 | 585 | 3811573760 | 1357 | 10.28 | 302819487 | 1.91 |
| batch | 16 | 5699053 | 356191 | 9498 | 594 | 7702839296 | 1352 | 21.1 | 613625382 | 4.14 |
| batch | 24 | 8473112 | 353046 | 14122 | 588 | 11460935680 | 1353 | 31.73 | 914679629 | 6.76 |
| batch | 32 | 11150937 | 348467 | 18585 | 581 | 15014559744 | 1346 | 43 | 1202846932 | 9.16 |
| batch | 40 | 13715453 | 342886 | 22859 | 571 | 18433966080 | 1344 | 54.23 | 1483715019 | 11.62 |
| array | 1 | 3905174 | 3905174 | 6509 | 6509 | 998244352 | 256 | 2.62 | 392426992 | 0.97 |
| array | 2 | 7449168 | 3724584 | 12436 | 6218 | 1946157056 | 261 | 4.98 | 790648022 | 1.77 |
| array | 4 | 15012417 | 3753104 | 25021 | 6255 | 3759144960 | 250 | 10.3 | 1590553386 | 3.55 |
| array | 8 | 29071138 | 3633892 | 48452 | 6056 | 7314866176 | 252 | 20.93 | 3074097328 | 7.16 |
| array | 16 | 54995783 | 3437236 | 91660 | 5729 | 13689159680 | 249 | 44.71 | 5870053062 | 14.52 |
| array | 24 | 71142564 | 2964274 | 118769 | 4949 | 17716740096 | 249 | 70.3 | 7700615372 | 21.44 |
| array | 32 | 70129137 | 2191536 | 116882 | 3653 | 17445158912 | 249 | 98.05 | 7291388140 | 24.19 |
| array | 40 | 63360903 | 1584023 | 105602 | 2640 | 15777923072 | 249 | 100 | 5820054045 | 21.5 |
| fast | 1 | 7375197 | 7375197 | 12292 | 12292 | 10092544000 | 1368 | 1.02 | 774367576 | 1.75 |
| fast | 2 | 15095665 | 7547833 | 25201 | 12601 | 20561526784 | 1362 | 2.16 | 1593179223 | 3.39 |
| fast | 4 | 30282148 | 7570537 | 50470 | 12618 | 41224765440 | 1361 | 4.18 | 3189663856 | 6.75 |
| fast | 8 | 55831396 | 6978925 | 93052 | 11632 | 75959894016 | 1361 | 8.28 | 5875185001 | 14.08 |
| fast | 16 | 104297635 | 6518602 | 173829 | 10864 | 141947830272 | 1361 | 16.49 | 11196136570 | 27.05 |
| fast | 24 | 102562062 | 4273419 | 170369 | 7099 | 139527716864 | 1360 | 17.38 | 10778883774 | 32.92 |
| fast | 32 | 103225392 | 3225794 | 171186 | 5350 | 140403277824 | 1360 | 18.82 | 11678089935 | 32.05 |
| fast | 40 | 130837615 | 3270940 | 218063 | 5452 | 177978998784 | 1360 | 23.22 | 13739915894 | 47.56 |
- Scenario - testing scenario.
- Threads - number of processes (workers), inserting data into the target database in parallel.
- Total Inserts - total number of records inserted into the target database by all threads during 10 minutes.
- Inserts per Thread - average number of records inserted into the target database by a single thread during 10 minutes.
- Inserts per Second - average number of records inserted into the target database by all threads during 1 second.
- Inserts per Second and Thread - average number of records inserted into the target database by single thread during 1 second.
- Used Bytes - number of bytes allocated by all inserted records in the database, as reported by the dictionary view
USER_SEGMENTS. - Bytes per Row - average number of bytes allocated by a single record in the database, as reported by the dictionary view
USER_SEGMENTS. - ADW CPU Utilization % - average CPU utilization of the ADW instance, retrieved from Monitoring service with the query
CpuUtilization[1m]{resourceId = "<ADW OCID>"}.mean(). - ADW Client Sent Bytes - average number of bytes per minute sent from the client VM to the ADW instance, retrieved from Monitoring service with the query
SQLNetBytesFromClient[1m]{resourceId = "<ADW OCID>"}.mean(). - Client CPU Utilization % - average CPU utilization of the client VM instance, retrieved from Monitoring service with the query
CPUUtilization[1m]{resourceId = "<Client VM OCID>"}.mean().
Considerations
Changes in Data Model
For your workload, you might want to consider some changes in the data model that will impact the throughput performance. You should test the throughput with your data model to get realistic figures.
- Change the data model for your data.
- Add primary or unique keys constraints.
- Add analytical indexes.
- Change JSON data type to BLOB if you have large JSON documents.
- Partition the target table by time.
- Insert data into multiple target tables.
- Add materialized views with refresh ON COMMIT.
Tuning
For large data volumes, requiring performance beyond the figures achieved with out-of-the-box setup, you might need additional tuning of the data model, data loader, or configuration. Some options to consider are below.
- Scale up the ADW instance and/or enable Compute Autoscaling.
- Eliminate gateways in the traffic between clients and database.
- Analyze the contention bottlenecks for Fast and/or Array scenarios.
- Optimize array size and commit frequency.
- Partition for scalability.
- Use Direct Path Load with micro-batching.
- Shard with Oracle Sharding or manually.
I also recommend reviewing Oracle White Paper by Andy Rivenes on Best Practices For High Volume IoT workloads with Oracle Database 19c for ideas on other optimization methods.
Resources
- Using Oracle Autonomous Database Serverless: Use Fast Ingest on Autonomous Database.
- Oracle Database 19c, Database Performance Tuning Guide, Tuning the System Global Area: Using the Fast Ingest.
- Oracle Database 19c, Utilities: Data Loading Methods.
- Oracle Database 19c, PL/SQL Packages and Types Reference: DBMS_MEMOPTIMIZE.
- Oracle Database In-Memory blog by Andy Rivenes: New in Oracle Database 19c: Memoptimized Rowstore – Fast Ingest.
- Oracle Database In-Memory blog by Andy Rivenes: Memoptimized Rowstore - Fast Ingest Updates.
- Oracle Database In-Memory blog by Andy Rivenes: Oracle Database 23c Fast Ingest Enhancements.
- Oracle White Paper by Andy Rivenes: Best Practices For High Volume IoT workloads with Oracle Database 19c.
- Program to test high frequency inserts: load-generator.