Data Lake File Access

Introduction
In this post I evaluate how easy it is to map files in Oracle Cloud Infrastructure (OCI) Object Storage to Autonomous Data Warehouse (ADW) and whether there is substantial difference in access performance depending on file format.
This type of access is used for example by a data mart pattern, where source data is staged in a Object Storage (Data Lake), and processed and accessed from ADW. The files in Object Storage may be accessed either directly, using the external table feature in ADW, or loaded to ADW and then processed via SQL/PLSQL modules.
The post is a sequel to the previous entry, where I compared several commonly used file formats from the space efficiency and speed of processing points of view. The first post is available here:
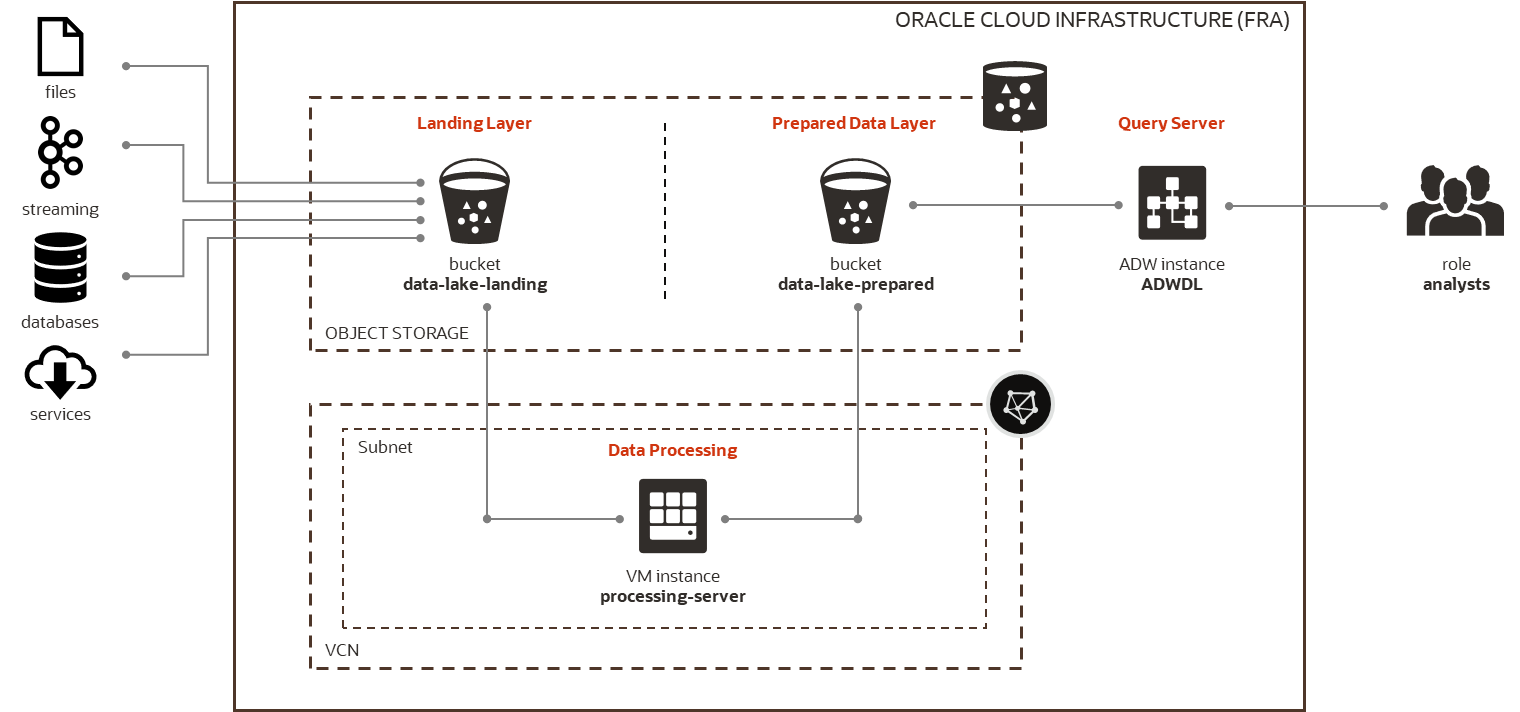
Architecture
Architecture used for the evaluation remains the same. But while in the previous post I tested data processing between Landing Layer and Prepared Data Layer using Python modules, in this post I evaluate access to Prepared Data Layer from Query Server, i.e. instance of Autonomous Data Warehouse.
For the test, I used the smallest ADW instance, with 1 OCPU and 1 TB of storage. The version of ADW was 19c. To access the database and run test SQL commands, I used web based SQL Developer, automatically provisioned with the ADW.
Test Data
I have tested 4 different file formats stored in Object Storage - JSON Lines, CSV, Avro, and Parquet. For Parquet, I tested also uncompressed files and files compressed with Snappy and gzip. The test data set was the same for all file formats. It consisted of 3 files stored in Object Storage, with over 3 million records, as shown in the table.
| Type | File Name | Size (MiB) | Records | Files |
|---|---|---|---|---|
| JSON | http_log_file_large_*.json | 1 627 | 3 225 744 | 3 |
| CSV | http_log_file_large_*.csv | 682 | 3 225 744 | 3 |
| Avro | http_log_file_large_*.avro | 663 | 3 225 744 | 3 |
| Parquet/uncompressed | http_log_file_large_n_*.parquet | 476 | 3 225 744 | 3 |
| Parquet/snappy | http_log_file_large_s_*.parquet | 215 | 3 225 744 | 3 |
| Parquet/gzip | http_log_file_large_g_*.parquet | 146 | 3 225 744 | 3 |
To create an external table in ADW against files stored in Object Storage, I used DBMS_CLOUD.CREATE_EXTERNAL_TABLE procedure. For formats with embedded schema, such as Avro and Parquet, the schema of external table is taken from the file. For text files, such as JSON and CSV, the schema must be specified when calling CREATE_EXTERNAL_TABLE.
For reference, the documentation on DBMS_CLOUD is available here:
JSON files
I have not found an easy way how to define a schema for JSON Lines directly in CREATE_EXTERNAL_TABLE. Instead, I created an external table with single CLOB column containing JSON documents, and then I created view which applies schema to the CLOB document.
The external table definition is as follows:
dbms_cloud.create_external_table(
table_name => 'LARGE_HTTP_LOG_FILE_N_JSON'
, credential_name => 'ObjectStorage'
, file_uri_list => 'https://objectstorage.eu-frankfurt-1.oraclecloud.com/n/<namespace>/b/test-bucket/o/target/large/http_log_file*_n.json'
, format => json_object('delimiter' value '\n')
, column_list => 'json_document clob'
, field_list => 'json_document char(5000)'
);
And the view applying schema for JSON column is:
create or replace view LARGE_HTTP_LOG_FILE_N_JSON_V as
select
json_value(json_document,'$.sn_start_time ') as sn_start_time
, json_value(json_document,'$.sn_end_time ') as sn_end_time
, json_value(json_document,'$.radius_calling_station_id ') as radius_calling_station_id
, json_value(json_document,'$.ip_subscriber_ip_address ') as ip_subscriber_ip_address
, json_value(json_document,'$.ip_server_ip_address ') as ip_server_ip_address
, json_value(json_document,'$.http_host ') as http_host
, json_value(json_document,'$.http_content_type ') as http_content_type
, json_value(json_document,'$.http_url ') as http_url
, json_value(json_document,'$.transaction_downlink_bytes ') as transaction_downlink_bytes
, json_value(json_document,'$.transaction_uplink_bytes ') as transaction_uplink_bytes
, json_value(json_document,'$.transaction_downlink_packets ') as transaction_downlink_packets
, json_value(json_document,'$.transaction_uplink_packets ') as transaction_uplink_packets
, json_value(json_document,'$.sn_flow_id ') as sn_flow_id
from LARGE_HTTP_LOG_FILE_N_JSON;
CSV files
For CSV files, I created schema by ordering attributes according to their position. Note that in real life I should also map the attributes to their real data types; for simplicity, I used VARCHAR2(4000) data type for every attribute.
dbms_cloud.create_external_table(
table_name => 'LARGE_HTTP_LOG_FILE_N_CSV'
, credential_name => 'ObjectStorage'
, file_uri_list => 'https://objectstorage.eu-frankfurt-1.oraclecloud.com/n/<namespace>/b/test-bucket/o/target/large/http_log_file*_n.csv'
, format => json_object('type' value 'csv', 'skipheaders' value '1', 'ignoremissingcolumns' value 'true', 'delimiter' value ',', 'quote' value '"')
, column_list => 'lineno varchar2(4000),
sn_start_time varchar2(4000),
sn_end_time varchar2(4000),
radius_calling_station_id varchar2(4000),
ip_subscriber_ip_address varchar2(4000),
ip_server_ip_address varchar2(4000),
http_host varchar2(4000),
http_content_type varchar2(4000),
http_url varchar2(4000),
transaction_downlink_bytes varchar2(4000),
transaction_uplink_bytes varchar2(4000),
transaction_downlink_packets varchar2(4000),
transaction_uplink_packets varchar2(4000),
sn_flow_id varchar2(4000)'
);
Avro files
Creation of external tables for Avro files is very simple, as DBMS_CLOUD gets the schema from Avro files.
dbms_cloud.create_external_table(
table_name => 'LARGE_HTTP_LOG_FILE_N_AVRO'
, credential_name => 'ObjectStorage'
, file_uri_list => 'https://objectstorage.eu-frankfurt-1.oraclecloud.com/n/<namespace>/b/test-bucket/o/target/large/http_log_file*_n.avro'
, format => '{"type":"avro", "schema": "first"}'
);
Parquet files
Similarly, for Parquet files you also do not have to provide the schema.
Note that DBMS_CLOUD recognizes how Parquet file is compressed - there is no need to specify compression when creating external table for Parquet files. The first external table maps non-compressed Parquet files, the second Parquet files with Snappy compression, the third Parquet files with gzip compression. The command remains the same.
dbms_cloud.create_external_table(
table_name => 'LARGE_HTTP_LOG_FILE_N_PARQUET'
, credential_name => 'ObjectStorage'
, file_uri_list => 'https://objectstorage.eu-frankfurt-1.oraclecloud.com/n/<namespace>/b/test-bucket/o/target/large/http_log_file*_n.parquet'
, format => '{"type":"parquet", "schema": "first"}'
);
dbms_cloud.create_external_table(
table_name => 'LARGE_HTTP_LOG_FILE_S_PARQUET'
, credential_name => 'ObjectStorage'
, file_uri_list => 'https://objectstorage.eu-frankfurt-1.oraclecloud.com/n/<namespace>/b/test-bucket/o/target/large/http_log_file*_s.parquet'
, format => '{"type":"parquet", "schema": "first"}'
);
dbms_cloud.create_external_table(
table_name => 'LARGE_HTTP_LOG_FILE_G_PARQUET'
, credential_name => 'ObjectStorage'
, file_uri_list => 'https://objectstorage.eu-frankfurt-1.oraclecloud.com/n/<namespace>/b/test-bucket/o/target/large/http_log_file*_g.parquet'
, format => '{"type":"parquet", "schema": "first"}'
);
Test Results
I have tested 3 data access scenarios. For each scenario and for each file format type, I executed SQL command shown below, and measured duration and throughput of the SQL command.
The commands were executed serially (i.e. only single command was running at one time). I have used the ADW’s “Low” service, which prevents utilization of parallel query. The results presented are averages from 10 consecutive runs.
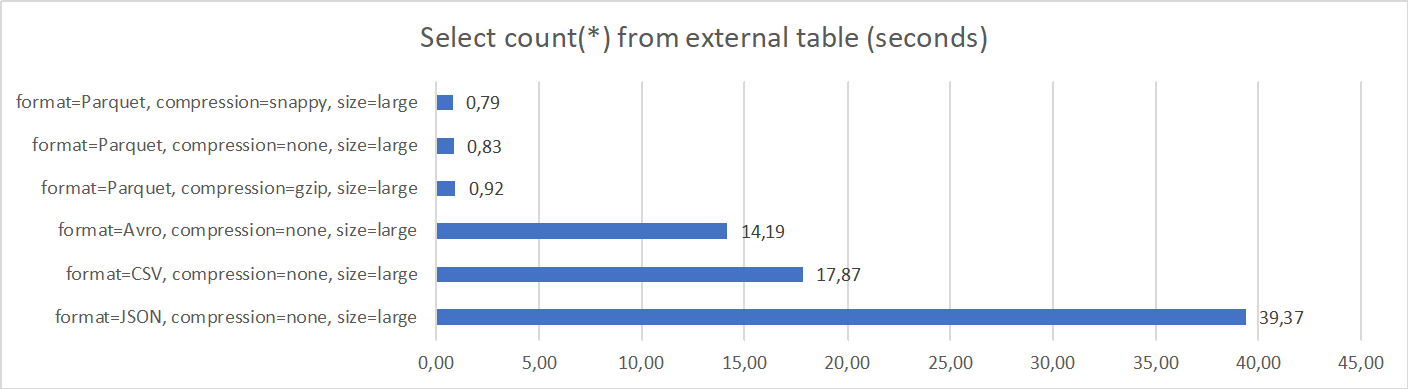
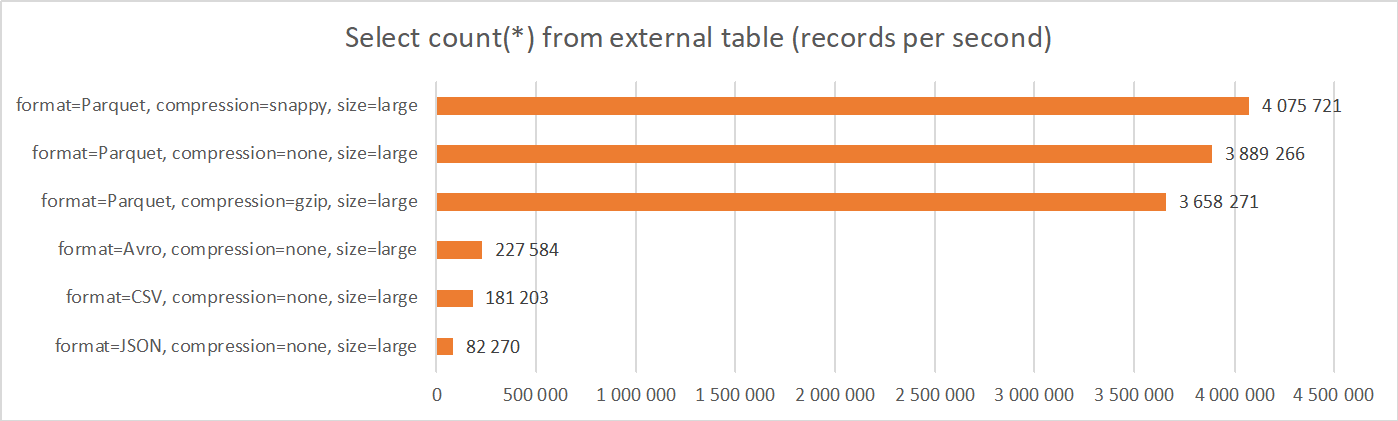
1. Select count(*) from external table
This scenario tests a simple query which reads and counts all records in the external table. Data remains in Object Storage; no data is materialized in ADW.
select count(*)
from <external table>
Results show dramatic performance difference between different file formats. Parquet (regardless of the compression method) is the best performing format, Avro and CSV are significantly worse performing, and JSON is the slowest format.
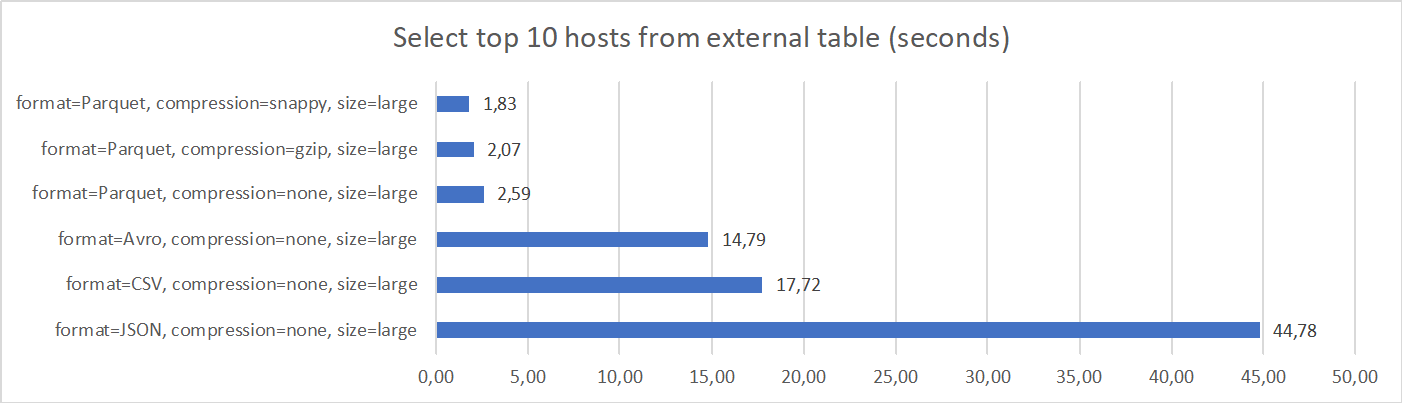
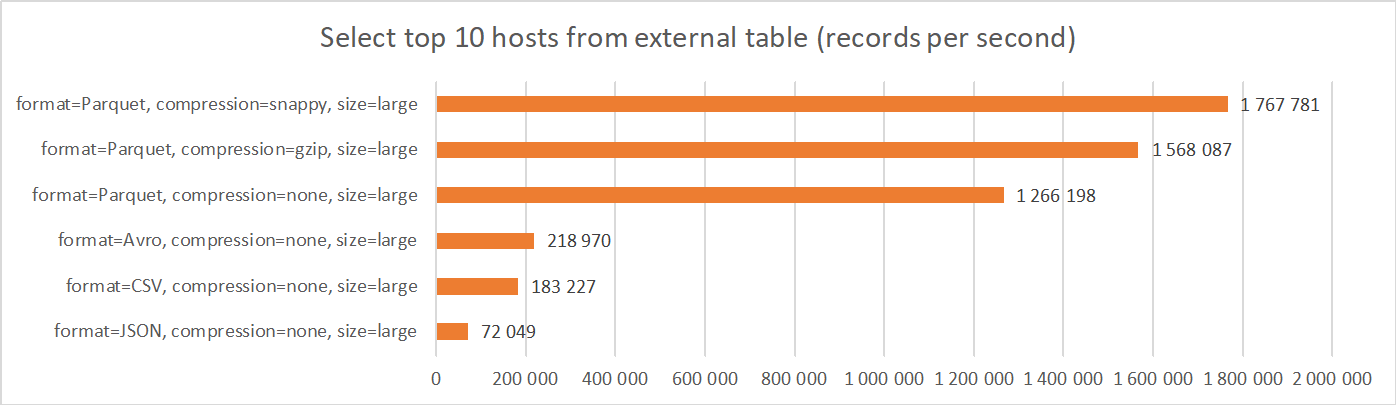
2. Select top 10 hosts from external table
This scenario tests a moderately complex query, which reads and aggregates all records in the external table and it returns 10 locations (hosts) which are most frequently accessed. Similar to previous scenario, data remains in Object Storage.
select http_host, http_host_cnt, http_host_rank
from (
select http_host, http_host_cnt
, dense_rank() over (order by http_host_cnt desc) as http_host_rank
from (
select http_host, count(*) as http_host_cnt
from <external table>
group by http_host
)
)
where http_host_rank <= 10
order by http_host_rank, http_host_cnt, http_host
Results are very similar to previous, simple query scenario. Apparently, performance is still driven by the performance of accessing and processing files from Object Storage, instead of running the aggregation and calculation.
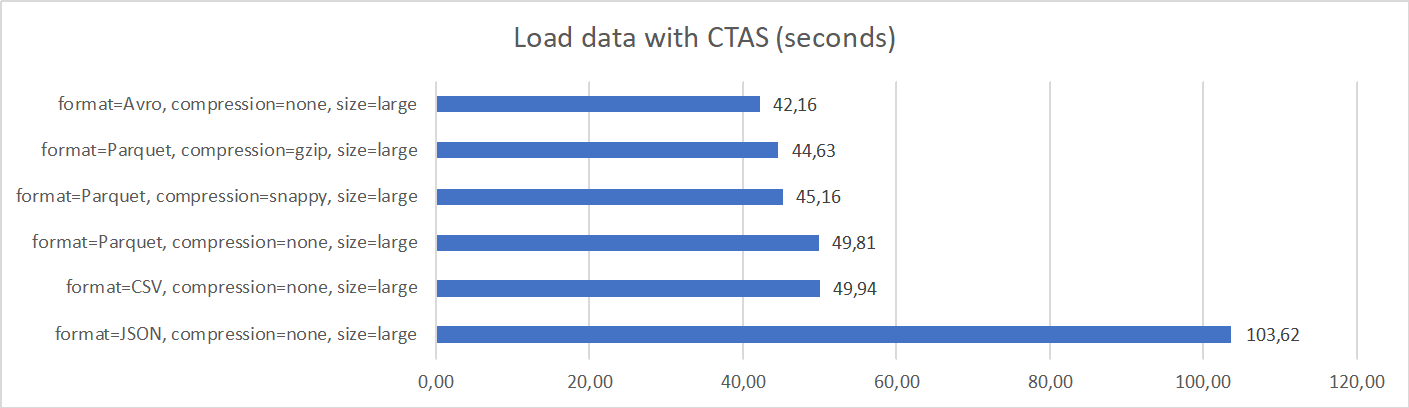
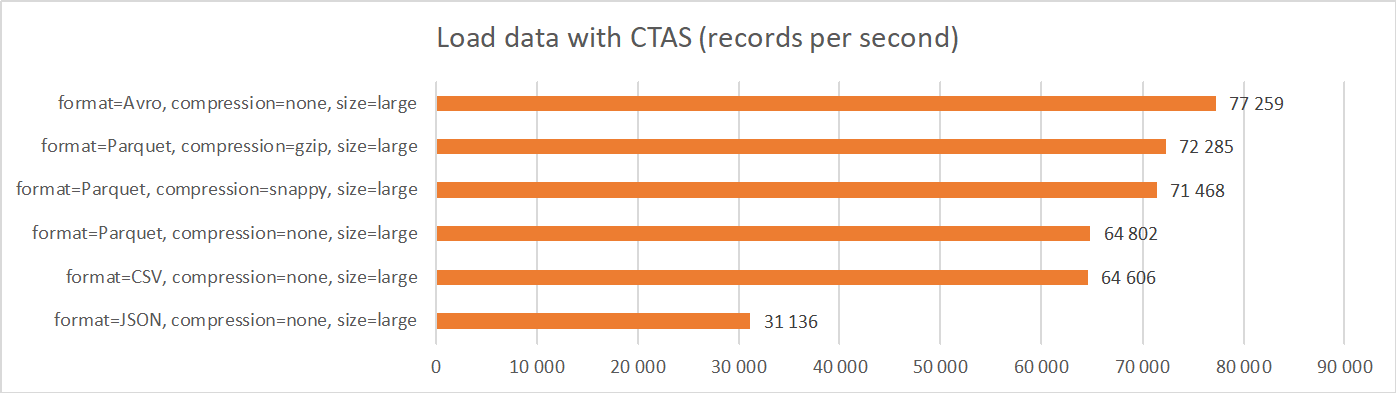
3. Load data with CTAS
This scenario creates and loads an ADW table from data stored in Object Storage. It uses Create Table As Select command (CTAS), with the source defined as external table against Object Storage.
create table <target table> as
select * from <external table>
Results differ significantly from previous two scenarios. Performance of loading Avro, Parquet, and CSV files is comparable, with Avro being the best performing. JSON files still have the worst performance.
Summary
This concludes the second part of the blog, focused on accessing files with different file formats on Object Storage from Autonomous Data Warehouse (ADW).
-
Parquet and Avro files contain schema and are therefore much easier and less error prone to use than text formats like CSV and JSON Lines. For Prepared Data layer, I recommend using these formats instead of other formats, where the schema must be defined when creating external tables in ADW.
-
Parquet provides by far the best performance when reading and analyzing files on Object Storage from ADW. Compression method does not have significant impact on access performance, however given the storage and network bandwidth savings, I recommend using either Snappy or gzip compression, as explained in the previous blog entry.
-
Avro and CSV provide comparable performance for reading and analyzing files, which is considerable worse than Parquet. For this reason I do not recommend using these formats for direct analysis of Object Storage files. However, if Object Storage is used for staging only and all data is materialized into ADW, than these formats deliver similar performance (in Avro case better) as Parquet.
-
JSON Lines files provide the worst performance, for both direct analysis and loading into ADW. For this reason, I recommend avoiding JSON Lines format when accessing and loading larger data from/into ADW.
So, the clear winner in this test is Parquet with Snappy or gzip compression. Note this is the same conclusion as I came to in the previous entry, where I compared performance and storage effectiveness of data preparation.
What is also clear is that JSON Lines format should not be used for larger data sets, as it does not perform (for both data access and data preparation) and it does not store data effectively.