Loading and Analysis of Large and Complex JSON Documents

Introduction
JSON is an ubiquitous format for exchanging data between business applications. It is text based, flexible, language independent, and it is easily understood by both humans and computers. JSON is used as format of choice by many messaging systems, application integrations, social media streams, document databases, system configurations, or data exports. For data lakehouses, JSON is one of the key source data formats.
JSON documents may be quite complex. With JSON objects and arrays you can create arbitrarily nested data structures, containing objects and arrays within objects, corresponding to complex business entities. Because of this flexibility, JSON is popular with application developers. However, the same flexibility makes analysis and visualizations of data stored in JSON documents challenging.
Most analytical and BI tools are unable to work with nested JSON documents directly. Rather, they require pre-processing of documents, typically by flattening of nested objects and pivoting or aggregating arrays into relational structures. And, because parsing and transforming of JSON documents is resource intensive, they might need to cache or materialize results to achieve good performance.
In this post I will show how you can effectively use JSON documents in Oracle Database 23ai together with Oracle Autonomous Database and Oracle Analytics Cloud to load, manage, transform, and analyze large and complex JSON documents. The size and complexity matters, as small and flat JSON documents can be analyzed in-place without much hassle.
The usual disclaimer applies. This post is not a benchmark. Your performance will differ, depending on your data model, data distribution, data sizes, configuration, and other parameters. I highly recommend testing performance on your data.
Summary
Oracle Database 23ai introduced a JSON Collection Table - a special type of table used to store collections of JSON documents. In addition to SQL, a collections can be accessed and manipulated with Oracle Database API for MongoDB and Simple Oracle Document Access (SODA). JSON Collection Table is a natural structure for storing source JSON documents in the original format in a Bronze layer of your data warehouse.
Loading of JSON documents from file or object storage into JSON Collection Table is easy. For adhoc loads, you can use visual Data Load tool in Database Actions. For production, regular data loads, you can use programmatic approach with DBMS_CLOUD, External Tables, and other built-in SQL/PLSQL commands. You can also utilize Oracle Scheduler to execute data loads according to the defined schedule.
For transforming JSON documents into relational structures suitable for analytics, you can use powerful built-in operators like JSON_VALUE and JSON_TABLE. I recommend encapsulating the transformation logic into views or materialized views and using the views as Silver layer by Oracle Analytics Cloud. Materialized views may be refreshed online, using REFRESH FAST ON STATEMENT or ON COMMIT, with guaranteed consistency between the base JSON Collection Table and materialized views.
Usage of materialized views may significantly accelerate queries against JSON documents. With the setup and test data described in this post, queries against materialized views were 5-12x faster than the same queries against JSON Collection Table. The performance gains will vary depending on your data and transformations, however you can see that materialized views could provide important latency and concurrency benefits.
However, materialized views do not come free. They require additional storage and they have dramatic impact on the load performance. Using the setup and test data described in this post, duration of load with materialized views refreshed FAST ON STATEMENT increased the load duration by factor of 5.5x. This is a difference of completing daily load in 30-40 seconds compared to 3-4 minutes.
I recommend testing the benefits of materialized views on your data. If you observe similar performance gains for user queries, I recommend considering materialized views instead of querying JSON documents via normal views or directly. Although the maintenance of materialized views increases the data load, it is outweighted by the much better latency and concurrency of user queries.
Use Case
Requirements
Business users need to analyze and forecast sales performance, trends, outliers, and seasonal behavior; to find out the best performing products, top customers, and sales opportunities; to identify anomalous invoices and non-standard discounts, and to perform other analytical tasks using the historical and current sales data.
Sales data required for this analytics comes primarily from customer invoices managed in the Accounts Receivable system (AR). AR regularly exports the invoices as JSON documents to external files. The files are uploaded to a bucket in OCI Object Storage. Within the bucket, the files are partitioned by date, with one folder containing invoices created in a single day.
Since the JSON documents with customer invoices are quite complex, it is necessary to transform the documents into structure that can be easily used by analytical and data science tools. At the same time, the source JSON documents must be stored in the original format, to accommodate schema changes and yet unknown, future analytical requirements.
The system must provide fast response to analytical queries, while supporting many concurrent sessions. Data should be stored with full history, allowing efficient management, archiving, and retirement of old data. And finally, the whole data loading and transformation pipeline must be fully automated and scheduled to run every day.
Solution Concept
All the above requirements can be easily met with a simple data lakehouse built with Oracle Autonomous Data Warehouse (ADW) running Oracle Database 23ai, and complemented by Oracle Analytics Cloud (OAC) for self-service analytics.
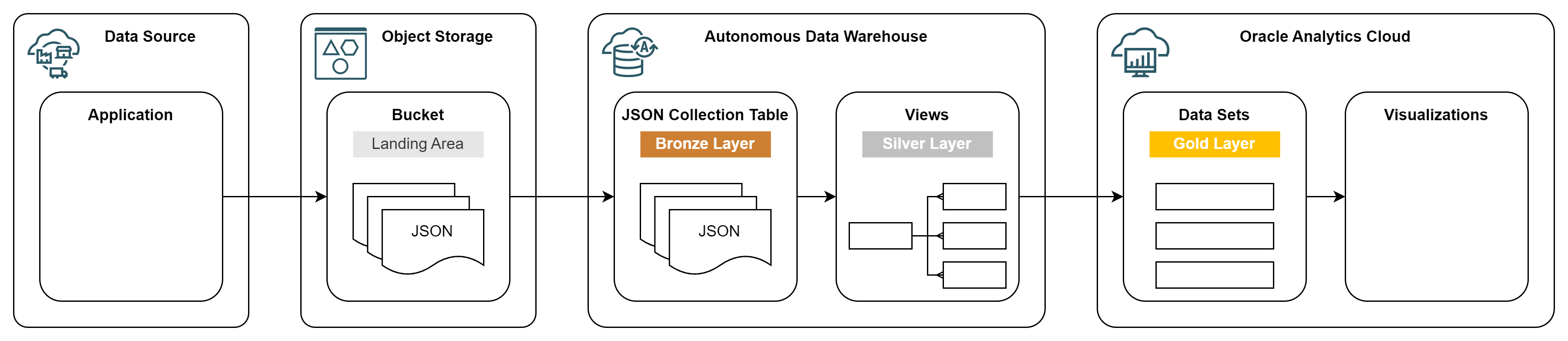
-
Bucket - JSON documents land in a bucket in OCI Object Storage. As the documents are quite large, a single file in the object storage typically contains only few JSON documents. Bucket acts as a Landing area. Once JSON documents are loaded into ADB, they can be archived or deleted from the object storage.
-
JSON Collection Table - JSON documents are loaded 1:1 from files in OCI Object Storage to a JSON Collection Table in Oracle Autonomous Database. One record in the JSON table corresponds to one JSON document. The JSON table acts as a Bronze layer. It contains complete source data in the original format.
-
Views - JSON documents are flattened into relational views or materialized views using JSON query support in the Oracle Autonomous Database. Views act as a Silver layer. They project JSON data into relational structure that can be easily queried and used by analytical tools.
-
Data Sets - Relational views are mapped to data sets in Oracle Analytics Cloud and used in visualizations. Optionally, you can apply additional data preparation steps in OAC or prepare a business model using OAC semantic modeler. Data sets represent the Gold layer used by all OAC analytics.
Source Files
The source files are stored in the invoice-data bucket in OCI Object Storage. Files
are text documents in JSON Lines format. On average, a single file has about 1 MB and
there are about 500 files per day. The file names use have Hive style partitioning, with
date=YYYYMMDD folders.
$ oci os object list -bn invoice-data -ns <namespace> --prefix "date=20240902" | jq -r '.data[] | .name'
date=20240902/invoice-20240902101555483689-c833b348-24a7-4853-8125-afe1ebe0ca6b.json
date=20240902/invoice-20240902101555550272-6c0b31b6-2193-45d1-ac82-837490c055db.json
date=20240902/invoice-20240902101555672161-a7cefba1-a477-412d-8edd-d0b5c34e256a.json
date=20240902/invoice-20240902101555773958-01b73641-ecd0-4acc-92b7-ed9a0189ca24.json
date=20240902/invoice-20240902101555872248-1aa1e5ae-005c-4f5f-bb66-72ad7784399f.json
...
For the purpose of this post the documents are artificial, generated by file-generator.
JSON Schema
A sample of a customer invoice exported as JSON document (prettified) looks as follows.
{
"detail": {
"document_id": "unique ID of the document",
"invoice_number": "invoice number",
"purchase_order": "purchase order number",
"contract_number": "contract number",
"currency_code": "currency ISO code",
"invoice_date": "invoice date in YYYY-MM-DD format",
"due_date": "due date in YYYY-MM-DD format",
"created_timestamp": "invoice creation timestamp in YYYY-MM-DDTHH24:MI:SS format"
},
"customer": {
"customer_number": "customer number",
"name": "customer name",
"addresses": [
{
"address_type": "address type such as bill, ship",
"contact_name": "contact name",
"address_detail": "street name, street number, building number, etc.",
"zip_code": "zip code",
"city_name": "city name",
"country_name": "country name"
},..
]
},
"total": {
"base_amount": total base amount,
"discount_amount": total amount after discount,
"tax_amount": total tax amount,
"net_amount": total net amount
},
"tax_lines": [
{
"tax_code": "tax code",
"tax_pct": tax percentage,
"tax_desc": "tax description",
"tax_amount": tax amount
},..
],
"lines": [
{
"line_number": line number,
"product_code": "product code",
"product_desc": "product description",
"quantity": product quantity,
"unit_price": unit price,
"base_amount": base amount,
"discount_pct": discount percentage,
"discount_amount": amount after discount,
"tax_code": "tax code",
"tax_pct": tac percentage,
"tax_amount": tax amount,
"net_amount": net amount,
"comment": "line comment"
},..
],
"comments": [
{
"comment_number": comment number,
"comment_text": "invoice comment"
},..
]
}
Solution Design
Load Pipeline
JSON documents can be easily loaded with Data Load tool of Database Actions. This approach is useful for adhoc, on-demand data, but it is not suitable for production, regular data loads. Therefore I used a programmatic approach using the built-in SQL/PLSQL commands to schedule and load JSON documents and transform them to relational structures.
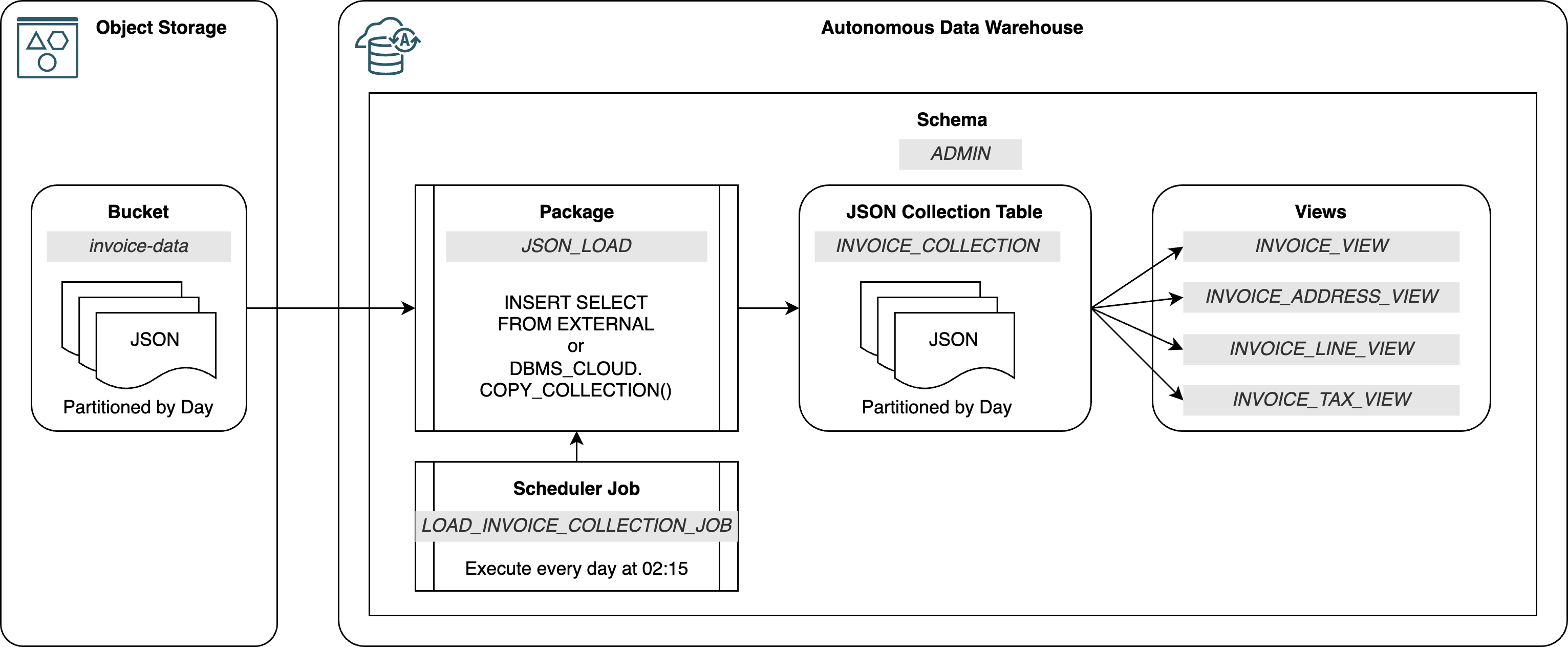
-
Package
JSON_LOADloads files from the Object Storage. The package supports two loading methods - using DBMS_CLOUD.COPY_COLLECTION and using INSERT SELECT FROM EXTERNAL. -
Job
LOAD_DAILY_INVOICESinvokes the file load. The job uses built-in Oracle Scheduler to automatically load JSON documents every day. -
JSON Collection Table
INVOICE_COLLECTIONstores JSON documents loaded from the Object Storage. The table is monthly partitioned by document date to improve query performance and to support data lifecycle management. -
Views
INVOICE%VIEWflatten and map JSON documents into several relational structures suitable for analytics. Both normal views and materialized views may be used. -
Schema
ADMIN- for simplicity, I deployed the test solution to the ADMIN schema, created out-of-the-box with every Autonomous Database. In a production deployment, you would use a different, application specific schema.
JSON Collection Table
JSON Collection Table is a special type of table used to store collections of JSON documents. In addition to SQL, a collection can be accessed and manipulated with Oracle Database API for MongoDB and Simple Oracle Document Access (SODA).
JSON Collection Table contains a single column DATA of a JSON data type. When inserting
JSON document into this table, Oracle automatically adds document identifier _id at the
top level, if it is not already available in the document.
The following statement creates a JSON Collection Table INVOICE_COLLECTION with virtual
column DOCUMENT_DATE mapped to $.document_date field in the JSON document. The column
is used to partition the collection by day.
create json collection table invoice_collection (
document_date date generated always as (to_date(json_value(data,'$.document_date' error on error),'YYYY-MM-DD'))
)
partition by range (document_date)
interval (numtodsinterval(1,'DAY'))
(partition part_01 values less than (to_date('20240901', 'YYYYMMDD')))
/
It is not nesessary to define a constraint checking that the content is a valid JSON document. This check is performed automatically by the database.
Data Load
JSON documents stored in Object Storage are loaded by the PLSQL package JSON_LOAD. The
package supports two loading methods:
-
INSERT SELECT FROM EXTERNAL method -
into_collection_direct()loads JSON documents directly into target collection, using ORACLE_BIGDATA driver with jsondoc file format. -
DBMS_CLOUD.COPY_COLLECTION method -
into_collection_2steps()loads JSON documents first to staging Collection with DBMS_CLOUD.COPY_COLLECTION, and then it inserts documents into the target collection.
The complete description and code of the package is available here: file-loader.
JSON document transformation
The package extends the source JSON objects by additional runtime metadata document_date
and inserted_timestamp. The objective is to capture the value of the source partition
and use it to partition the target collection.
{
"document_date": "2024-09-01",
"inserted_timestamp": "2024-10-18T13:05:41.571",
"document_body": { ... }
}
document_date- value of parameter p_source_date in YYYY-MM-DD format.inserted_timestamp- insert timestamp in YYYY-MM-DD”T”HH24:MI:SS.FF3 format.document_body- JSON document from source file.
INSERT SELECT FROM EXTERNAL Method
This method uses the ability of ORACLE_BIGDATA access driver to read JSON documents from external objects. Note the SELECT FROM EXTERNAL clause accesses external data directly, without the need to create an external table.
This method is implemented in the procedure into_collection_direct() of the JSON_LOAD
package. The key code fragment is below.
insert into invoice_collection
select json_object(
'document_date' value to_char(p_source_date,'YYYY-MM-DD'),
'inserted_timestamp' value to_char(v_start_timestamp,'YYYY-MM-DD"T"HH24:MI:SS.FF3'),
'document_body' value data
returning json
)
from external (
(data json)
type ORACLE_BIGDATA
access parameters (
com.oracle.bigdata.fileformat = jsondoc
com.oracle.bigdata.credential.name = '<credential_name>'
)
location ('https://objectstorage.uk-london-1.oraclecloud.com/n/<namespace>/b/invoice-data/o/date=20240901/invoice*.json')
);
select json_object- this code extends the source JSON by additional metadata.from external- this code specifies parameters of the ORACLE_BIGDATA driver.com.oracle.bigdata.fileformat = jsondoc- specifies the format of source as JSON document.com.oracle.bigdata.credential.name- required to authorize access to Object Storage.location- specifies the source files, using wildcards.
DBMS_CLOUD.COPY_COLLECTION Method
This method loads data in two steps:
- JSON documents are loaded into temporary collection with DBMS_CLOUD.COPY_COLLECTION.
- JSON documents are extended and inserted from the temporary collection to the target collection.
The two steps are required to extend the source JSON documents by additional metadata and to enable partitioning of the target collection, as explained in JSON document transformation.
This method is implemented in the procedure into_collection_2steps() of the JSON_LOAD
package. The key code fragments are below.
1. Load into temporary collection
v_format :=
'{
"characterset" : "AL32UTF8",
"ignoreblanklines" : "true",
"rejectlimit" : "10000",
"unpackarrays" : "true",
"maxdocsize" : 64000000,
"regexuri" : "false"
}';
dbms_cloud.copy_collection (
collection_name => 'INVOICE_COLLECTION_STAGE',
credential_name => '<credential_name>',
file_uri_list => 'https://objectstorage.uk-london-1.oraclecloud.com/n/<namespace>/b/invoice-data/o/date=20240901/invoice*.json',
format => v_format,
operation_id => v_operation_id
);
"maxdocsize" : 64000000- maximum size of JSON document before compression to OSON format."regexuri" : "false"- prohibits usage of regular expression in file_uri_list.credential_name => '<credential_name>'- required to authorize access to Object Storage.file_uri_list => '<location>'- specifies the source files, using wildcards.
2. Insert into target collection
insert into invoice_collection
select json_object(
'document_date' value to_char(p_source_date,'YYYY-MM-DD'),
'inserted_timestamp' value value to_char(v_start_timestamp,'YYYY-MM-DD"T"HH24:MI:SS.FF3'),
'document_body' value json_transform(data, remove '$._id')
returning json
)
from invoice_collection_stage;
select json_object- this code extends the source JSON by additional metadata.
Scheduling Data Load
The load of JSON documents can be easily automated using the Oracle Scheduler available in every Oracle Database. To schedule a load, it is necessary to perform the following:
- Define Program - register JSON_LOAD as a program in Oracle Scheduler.
- Define Schedule - specify when and how often a program should run.
- Create Job - create Oracle Scheduler job by associating program with a schedule.
- Test Job - run job manually to make sure it works correctly.
Suppose we want to load JSON documents created during a day every night at 02:15 the
following day, using the json_load.into_collection_direct() procedure described above.
The Oracle Scheduler job will look like this:
Define Program
declare
v_action clob := q'!
begin
load_json.into_collection_direct (
p_credential => '<credential_name>',
p_source_file_uri_list => 'https://objectstorage.uk-london-1.oraclecloud.com/n/<namespace>/b/invoice-data/o/date=${date}/invoice*.json',
p_source_date => trunc(sysdate-1),
p_source_date_var => '${date}',
p_source_date_mask => 'YYYY-MM-DD',
p_target_schema => 'ADMIN',
p_target_collection => 'INVOICE_COLLECTION'
);
end;
!';
begin
dbms_scheduler.create_program (
program_name => 'LOAD_INVOICE_COLLECTION_PROGRAM',
program_type => 'PLSQL_BLOCK',
program_action => v_action,
enabled => true,
comments => 'Load JSON documents to INVOICE_COLLECTION for date SYSDATE-1'
);
end;
/
Define Schedule
begin
dbms_scheduler.create_schedule (
schedule_name => 'LOAD_INVOICE_COLLECTION_SCHEDULE',
start_date => systimestamp,
repeat_interval => 'FREQ=DAILY; BYHOUR=02; BYMINUTE=15',
end_date => null,
comments => 'Run every day at 02:15'
);
end;
/
Create Job
begin
dbms_scheduler.create_job (
job_name => 'LOAD_INVOICE_COLLECTION_JOB',
program_name => 'LOAD_INVOICE_COLLECTION_PROGRAM',
schedule_name => 'LOAD_INVOICE_COLLECTION_SCHEDULE',
job_class => 'HIGH',
enabled => true,
comments => 'Daily load of JSON documents to INVOICE_COLLECTION'
);
end;
/
Test Job
begin
dbms_scheduler.run_job (
job_name => 'LOAD_INVOICE_COLLECTION_JOB',
use_current_session => false
);
end;
/
Analytical Model
JSON Decomposition
Analytical and reporting tools cannot usually work with complex JSON documents similar to ones described in JSON Schema. It is necessary to decompose JSON document into one or more flat, relational structures. The process is demonstrated below.
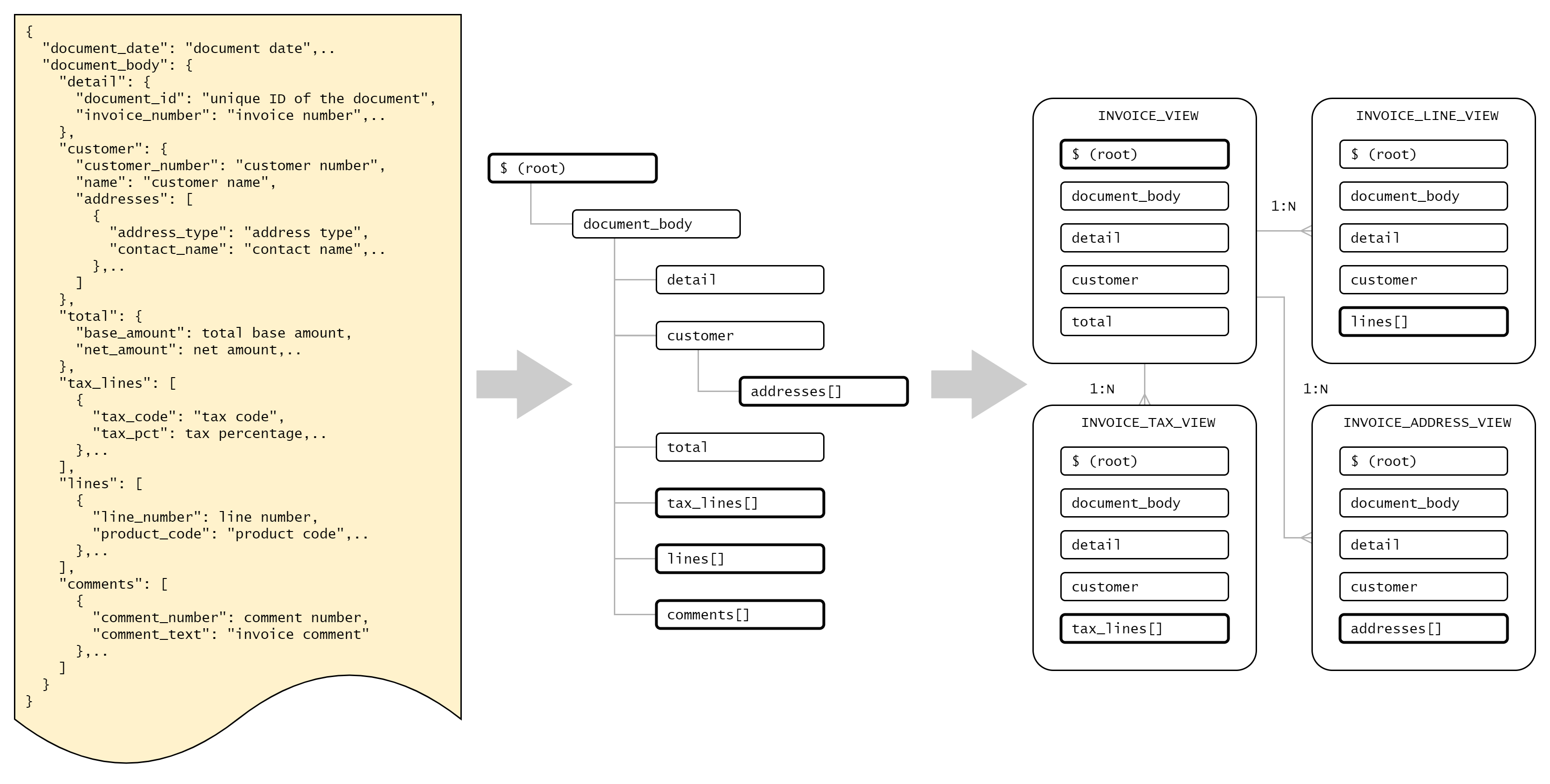
-
Before the modeling excercise, it is necessary to understand what types of queries users would like to run against JSON data. The relational structures must support these analysis. Often, parts of JSON documents are not needed and the analytical model may be simplified.
-
In the next step, it is useful to understand the hierarchy of JSON objects and arrays, starting from the root object. While scalar fields in objects may be mapped directly to root entity, every array requires a new data entity, with array members converted into rows and 1:N relationship with the root entity.
-
In the last step we create relational objects (views, materialized views, tables) designed to support user queries. Typically, there is a root object with the granularity of a single JSON document (e.g.,
INVOICE_VIEW) and multiple child objects corresponding to various JSON arrays (e.g.,INVOICE_LINE_VIEWandINVOICE_TAX_VIEW). -
The relational objects do not have to be fully normalized. For example, it might be useful to replicate identifiers and important descriptive attributes across root and child objects. However, attributes with numerical measures should have the same granularity. For example,
line_base_amountmust not be in the same object astotal_base_amount.
Views
Views provide the simplest way how you can transform JSON Collections into relational structures. You can extend or change the view definition anytime as no data is materialized and the transformation happens on the fly.
View INVOICE_VIEW (root)
The root view INVOICE_VIEW contains flattened attributes either on the root level (i.e.,
$) or in the nested objects (e.g., $.document_body.detail). The granularity of this view
is exactly the same as the granularity of the source JSON Collection.
create or replace view invoice_view as
select
r.resid as resid,
r.document_date as document_date,
json_value(r.data,'$._id' returning varchar2(40)) as record_id,
to_timestamp(json_value(r.data,'$.inserted_timestamp'),'YYYY-MM-DD"T"HH24:MI:SS.FF3') as inserted_timestamp,
json_value(r.data,'$.document_body.detail.document_id' returning varchar2(40)) as document_id,
json_value(r.data,'$.document_body.detail.invoice_number' returning varchar2(20)) as invoice_number,
json_value(r.data,'$.document_body.detail.purchase_order' returning varchar2(20)) as purchase_order,
json_value(r.data,'$.document_body.detail.contract_number' returning varchar2(20)) as contract_number,
json_value(r.data,'$.document_body.detail.currency_code'returning varchar2(3)) as currency_iso_code,
to_date(json_value(r.data,'$.document_body.detail.invoice_date'),'YYYY-MM-DD') as invoice_date,
to_date(json_value(r.data,'$.document_body.detail.due_date'),'YYYY-MM-DD') as due_date,
to_timestamp(json_value(r.data,'$.document_body.detail.created_timestamp'),'YYYY-MM-DD"T"HH24:MI:SS') as invoice_creation_timestamp,
json_value(r.data,'$.document_body.customer.customer_number' returning varchar2(20)) as customer_number,
json_value(r.data,'$.document_body.customer.name' returning varchar2(200)) as customer_name,
json_value(r.data,'$.document_body.total.base_amount' returning number) as total_base_amount,
json_value(r.data,'$.document_body.total.discount_amount' returning number) as total_amount_after_discount,
json_value(r.data,'$.document_body.total.tax_amount' returning number) as total_tax_amount,
json_value(r.data,'$.document_body.total.net_amount' returning number) as total_net_amount
from invoice_collection r
/
To flatten the nested objects into relational view, it is possible to use Simple Dot Notation Access to JSON Data. An alternative is JSON_VALUE, which provides better control over the value and error handling.
View INVOICE_LINE_VIEW (child)
The child view INVOICE_LINE_VIEW transforms lines (array $.document_body.lines[]) into
rows. The granularity of this view corresponds to number of invoice lines. In other words,
for every JSON document - invoice, there is 1 or more invoice lines.
create or replace view invoice_line_view as
select
r.resid as resid,
r.document_date as document_date,
json_value(r.data,'$._id' returning varchar2(40)) as record_id,
to_timestamp(json_value(r.data,'$.inserted_timestamp'),'YYYY-MM-DD"T"HH24:MI:SS.FF3') as inserted_timestamp,
json_value(r.data,'$.document_body.detail.document_id' returning varchar2(40)) as document_id,
json_value(r.data,'$.document_body.detail.invoice_number' returning varchar2(20)) as invoice_number,
json_value(r.data,'$.document_body.detail.purchase_order' returning varchar2(20)) as purchase_order,
json_value(r.data,'$.document_body.detail.contract_number' returning varchar2(20)) as contract_number,
json_value(r.data,'$.document_body.detail.currency_code'returning varchar2(3)) as currency_iso_code,
to_date(json_value(r.data,'$.document_body.detail.invoice_date'),'YYYY-MM-DD') as invoice_date,
to_date(json_value(r.data,'$.document_body.detail.due_date'),'YYYY-MM-DD') as due_date,
json_value(r.data,'$.document_body.customer.customer_number' returning varchar2(20)) as customer_number,
json_value(r.data,'$.document_body.customer.name' returning varchar2(200)) as customer_name,
r_lines.*
from invoice_collection r,
json_table(r.data,'$.document_body.lines[*]' columns (
line_number number path '$.line_number',
line_product_code varchar2(20) path '$.product_code',
line_product_desc varchar2(200) path '$.product_desc',
line_quantity number path '$.quantity',
line_unit_price number path '$.unit_price',
line_base_amount number path '$.base_amount',
line_discount_pct number path '$.discount_pct',
line_discount_amount number path '$.discount_amount',
line_tax_code varchar2(20) path '$.tax_code',
line_tax_pct number path '$.tax_pct',
line_tax_amount number path '$.tax_amount',
line_net_amount number path '$.net_amount',
line_comment varchar2(400) path '$.comment'
)) r_lines
/
The projection of JSON array into rows is performed with JSON_TABLE function.
Materialized Views
For large and complex JSON documents, the query performance of views might not be great, because every query must parse and transform the JSON objects. This is particularly visible when there are many nested arrays or when arrays contain a lot of members. In these cases you can consider materialized views, which will calculate and store the transformed data and significantly improve query response.
The definition of materialized views is almost exactly the same as the definition of
normal views. Oracle Database 23ai supports both FAST REFRESH ON COMMIT and FAST REFRESH
ON STATEMENT for materialized views using JSON_VALUE and JSON_TABLE. Note that in our case
the materialized views are equi-partitioned with the base table INVOICE_COLLECTION.
The downside of materialized views refreshed ON COMMIT or ON STATEMENT is increased duration of the data load, caused by the need to parse the JSON documents, transform arrays into rows, and insert data into materialized views. The more materialized views there are, the bigger the performance impact.
Materialized View INVOICE_MVIEW
create materialized view invoice_mview
partition by range (document_date)
interval (numtodsinterval(1,'DAY'))
(partition part_01 values less than (to_date('20240901', 'YYYYMMDD')))
refresh fast on statement with rowid
as select
r.rowid as rid,
r.resid as resid,
r.document_date as document_date,
...
from invoice_collection r
/
Materialized View INVOICE_LINE_MVIEW
create materialized view invoice_line_mview
partition by range (document_date)
interval (numtodsinterval(1,'DAY'))
(partition part_01 values less than (to_date('20240901', 'YYYYMMDD')))
refresh fast on statement with rowid
as select
r.rowid as rid,
r.resid as resid,
r.document_date as document_date,
...
from invoice_collection r,
json_table(r.data,'$.document_body.lines[*]' columns (
line_number number path '$.line_number',
line_product_code varchar2(20) path '$.product_code',
...
)) r_lines
/
Configuration
The test configuration consists of Compute VM with the file generator program, Object Storage bucket, instance of Autonomous Data Warehouse, and instance of Oracle Analytics Cloud. All components are deployed in the OCI region UK South (London).
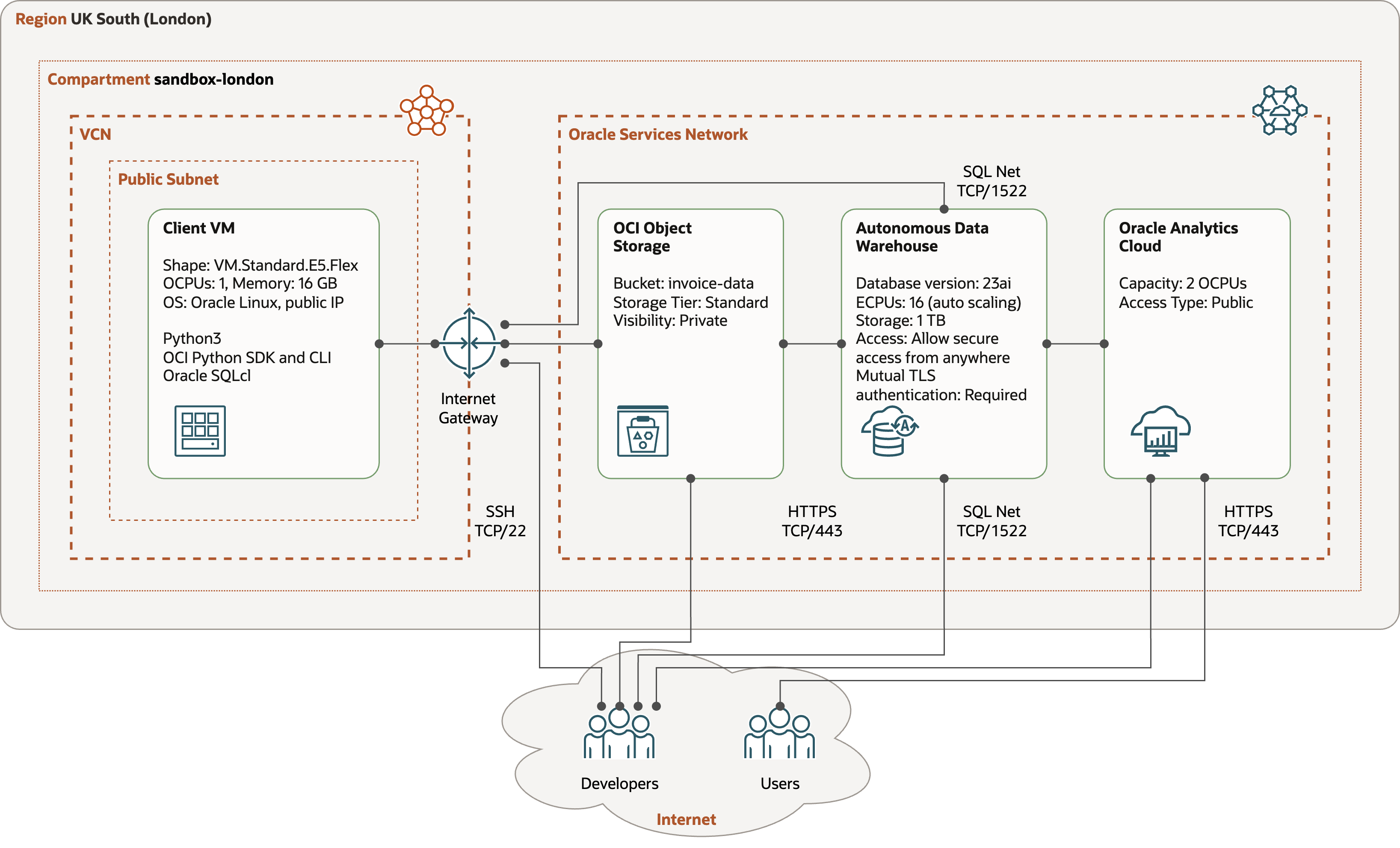
-
Compute VM - VM.Standard.E5.Flex shape with 1 OCPUs and 16 GB of memory, running Oracle Linux 8, Python 3.9, OCI Python SDK, and Oracle SQLcl. The VM is placed in a public subnet.
-
Object Storage Bucket - single bucket
invoice-datawith source JSON files generated by the file-generator. -
Autonomous Data Warehouse Serverless with Oracle Database 23ai - shape with 16 ECPUs and Autoscaling enabled. For the simplicity, the database is accessible from Internet, with TLS enforced connection.
-
Oracle Analytics Cloud - shape with 2 OCPUs. For the simplicity, OAC is accessible from Internet. Also, traffic to data sources travels over Internet.
-
Connectivity - Compute VM accesses OCI Object Storage over HTTPS and Autonomous Data Warehouse over SQL Net. The traffic is routed over Internet Gateway.
Observations
Test Data Sets
I tested the above solution with two data sets:
- Large - large JSON documents with average size of 256 kB.
- Small - small JSON documents with average size of 27 kB.
The parameters of these data sets are as as follows:
| Data Set | Days | Files | Documents | Lines | Size (MB) | Avg Files in Day | Avg Documents in Day | Avg Lines per Document | Avg kB per Document |
|---|---|---|---|---|---|---|---|---|---|
| Large | 91 | 38250 | 133676 | 70187054 | 34307 | 420 | 1469 | 525 | 257 |
| Small | 91 | 35959 | 1800868 | 90983295 | 48601 | 395 | 19790 | 51 | 27 |
- Days - number of days with generated data (3 months).
- Files - total number of generated files.
- Documents - total number of generated JSON documents in files.
- Lines - total number of “Invoice Lines” in generated JSON documents.
- Size (MB) - total size of generated files in MB.
- Avg Files in Day - average number of files generated per day.
- Avg Documents in Day - average number of JSON documents generated per day.
- Avg Lines per Document - average number of “Invoice Lines” in a single JSON document.
- Avg kB per Document - average size of a single JSON document in kB.
Collection Size
When loaded into the partitioned JSON Collection table, the JSON documents require the following storage:
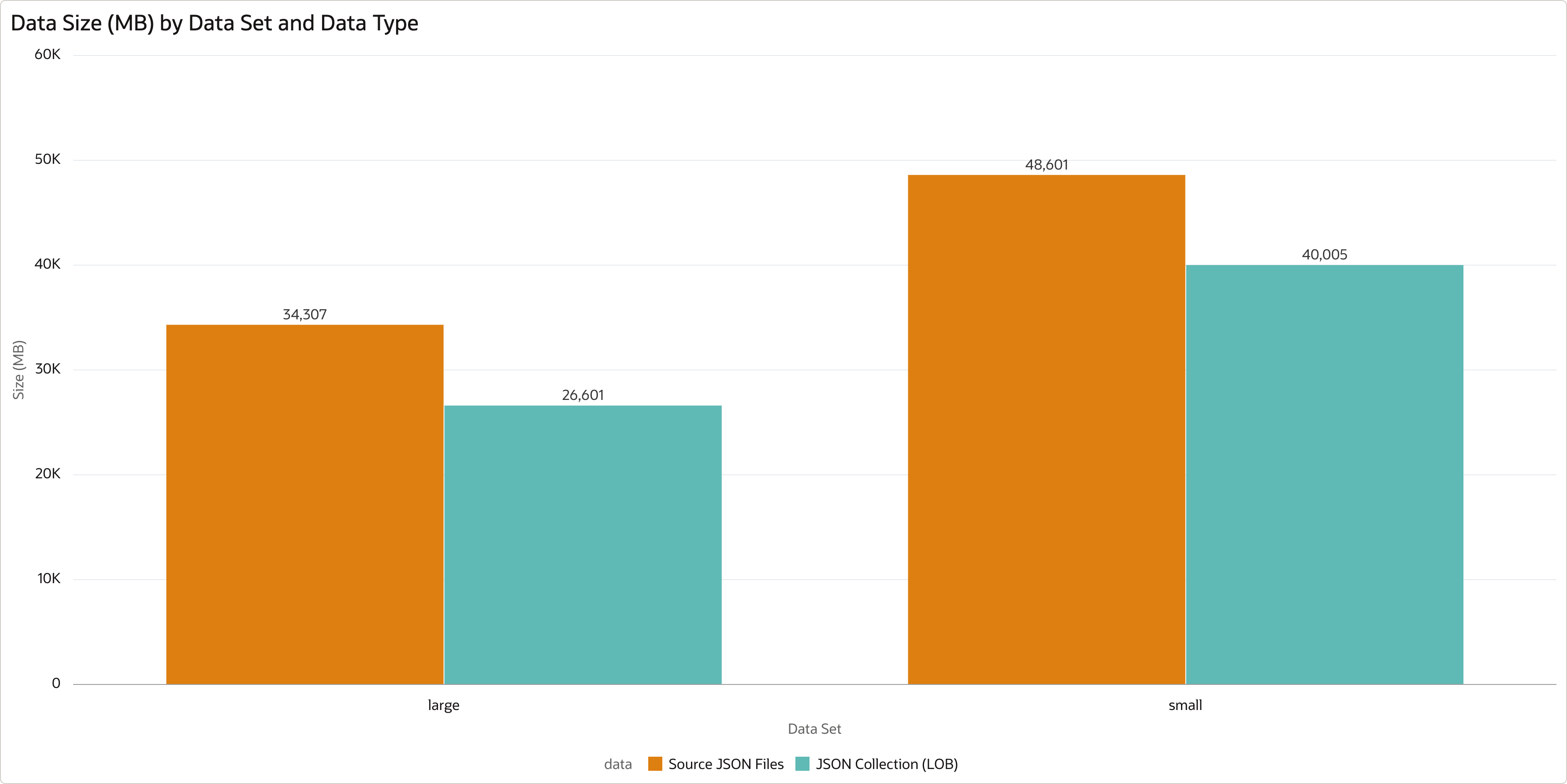
| Data Set | Partitions | Table Partition (MB) | LOB Partition (MB) | Total Size (MB) | File Size (MB) | Compression Ratio | Total Documents |
|---|---|---|---|---|---|---|---|
| Large | 92 | 763 | 26601 | 27365 | 34307 | 1.29 | 133676 |
| Small | 92 | 3061 | 40005 | 43066 | 48601 | 1.21 | 1800868 |
- Partitions - number of table partitions (number of days + 1).
- Table Partition (MB) - storage allocated by segment type
TABLE PARTITIONin MB. - LOB Partition (MB) - storage allocated by segment type
LOB PARTITIONin MB. - Total Size (MB) - total storage allocated by
INVOICE_COLLECTIONtable in MB. - File Size (MB) - total size of generated files in MB.
- Compression Ratio - compression ratio calculated as “File Bytes” / “LOB Partition”.
JSON documents in the Oracle Database 23ai use JSON data type with native binary format (OSON). As you can see, OSON is more effective than the original source format. On the test data set, I observed compression ratio 1.29 and 1.21 respectively. On your data, you will probably see higher ratio, as the test data set is randomly generated.
You can also see that JSON documents are stored in LOB segments instead of being stored inline in the table. This is caused by the size of documents - documents larger than 4000 bytes are stored offline, in LOB segments, while smaller documents are stored inline. Documents stored inline benefit from HCC compression and Exadata smart scans.
Materialized View Size
Materialized views defined in the section Materialized Views require additional storage:
| Data Set | Partitions | INVOICE MVIEW (MB) | INVOICE LINE MVIEW (MB) | INVOICE TAX MVIEW (MB) | MVIEW Size (MB) | Collection Size (MB) | Overhead Ratio |
|---|---|---|---|---|---|---|---|
| Large | 92 | 772 | 9196 | 772 | 10740 | 27365 | 39% |
| Small | 92 | 1106 | 25609 | 1258 | 27974 | 43066 | 65% |
- Partitions - number of table partitions (number of days + 1).
- INVOICE MVIEW (MB) - storage allocated by materialized view
INVOICE_MVIEWin MB. - INVOICE LINE MVIEW (MB) - storage allocated by materialized view
INVOICE_LINE_MVIEWin MB. - INVOICE TAX MVIEW (MB) - storage allocated by materialized view
INVOICE_TAX_MVIEWin MB. - MVIEW Size (MB) - total storage allocated by all materialized views in MB.
- Collection Size (MB) - storage allocated by
INVOICE_COLLECTIONtable in MB. - Overhead Ratio - additional storage required by mviews, calculated as 100* “MVIEW Bytes” / “Collection Bytes”.
The size of materialized views depends entirely on your data and the definition of views. For my test data set, I observed that materialized views require 39% and 65% respectively on top of the base JSON collection.
Load Performance
I tested the performance of loading data into JSON collection without and with materialized views. I used a single process connected to ADW database via HIGH service, using the DBMS_CLOUD.COPY_COLLECTION() method described in the section Data Load. The process loaded one day at a time.
I measured both the time required to load the JSON documents into staging JSON collection via DBMS_CLOUD.COPY_COLLECTION(), and the time spent to enrich and insert the data from staging to the target collection.
Note I did not test loading documents using the INSERT SELECT FROM EXTERNAL method. The reason is that this approach does not utilize parallelism and the performance suffers. I believe this limitation will be corrected in the future.
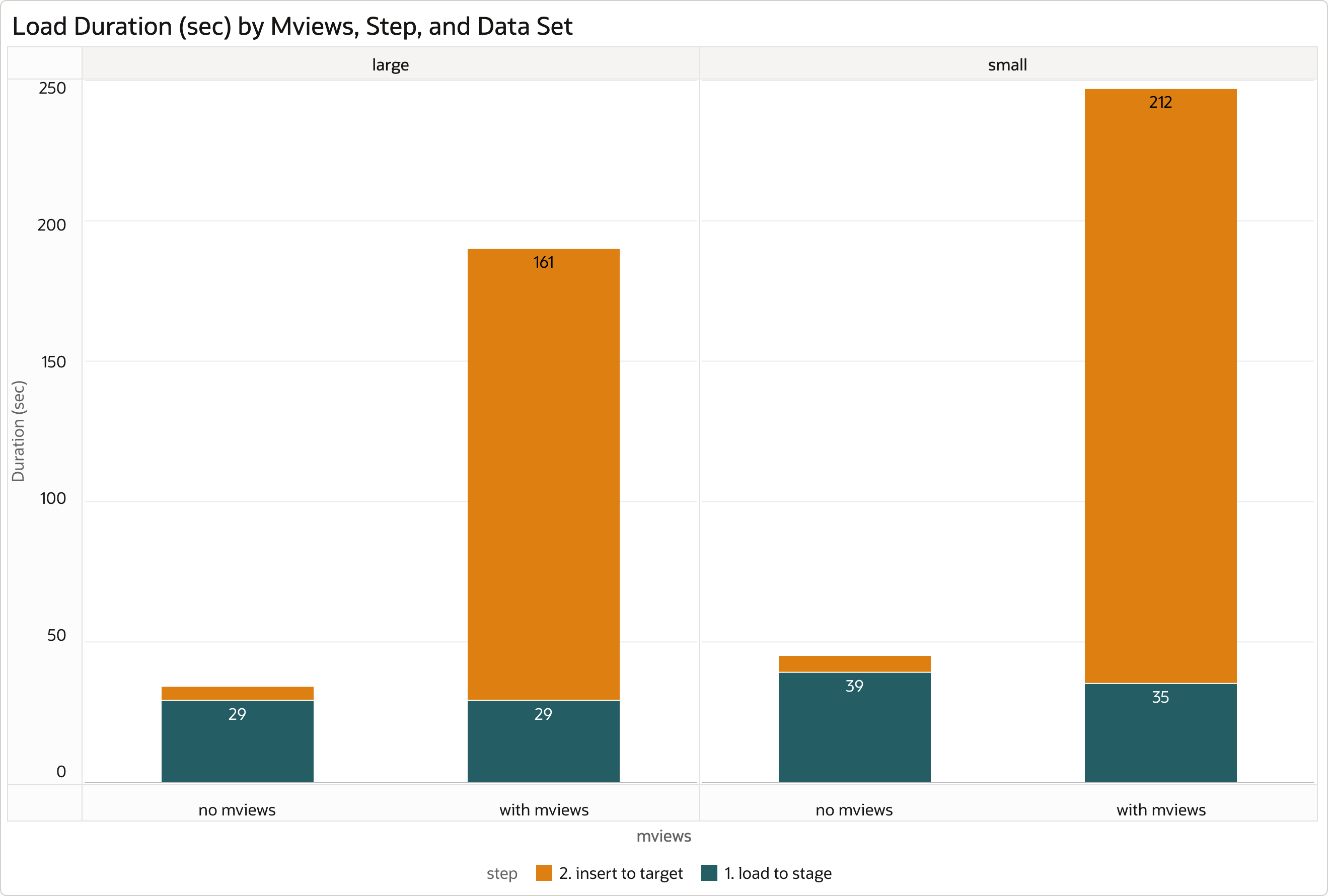
| Data Set | No Mviews - Avg Load Time | No Mviews - Avg Stage Time | No Mviews - Avg Insert Time | Mviews - Avg Load Time | Mviews - Avg Stage Time | Mviews - Avg Insert Time | Mviews Factor |
|---|---|---|---|---|---|---|---|
| Large | 34 | 29 | 5 | 190 | 29 | 161 | 5.6 |
| Small | 45 | 39 | 6 | 247 | 35 | 212 | 5.5 |
- No Mviews - Avg Load Time - average duration of a single day total load in seconds, without mviews.
- No Mviews - Avg Stage Time - average duration of a single day load into staging in seconds, without mviews.
- No Mviews - Avg Insert Time - average duration of a single day insert into target in seconds, without mviews.
- Mviews - Avg Load Time - average duration of a single day total load in seconds, with mviews.
- Mviews - Avg Stage Time - average duration of a single day load into staging in seconds, with mviews.
- Mviews - Avg Insert Time - average duration of a single day insert into target in seconds, with mviews.
- Mviews Factor - Performance impact of materialized views, calculated as “Mviews - Avg Load Time” / “No Mviews - Avg Load Time” (the smaller the better).
Without materialized views, the majority of time - about 86% - is spent on loading JSON documents to staging collection. Enriching the documents and inserting them into the target collection is relatively quick, requiring about 14% of the overall time. Both load and insert steps utilize parallelism provided by the HIGH service.
With materialized views, the overall performance is driven by the insert part. The presence of materialized views refreshed FAST ON STATEMENT has significant negative impact on the load performance. In my case, the load of documents into target collection with materialized views present increases the duration of the load approximately by the factor of 5.5. In other words, if a single day data are loaded in 1 minute without materialized views, the load needs more than 5 minutes with materialized views.
The question therefore is, do we really need materialized views to improve query performance? Can existence of online materialized views justify the significantly increase load time?
Query Performance
To answer this question, I tested how a medium complex analytical query behaves when running against normal views (see section Views) compared to materialized views (see section Materialized Views).
The query filters and aggregates Invoice Lines. When running against normal view, it transforms JSON array into rows online, using JSON_TABLE operator. The transformation is not needed for materialized views.
The query is executed multiple times sequentially for different combination of input parameters and the results are averaged across the executions. It uses MEDIUM database service. I measured both the query elapsed time and the DB Time consumed by the query. SQL Cache was disabled.
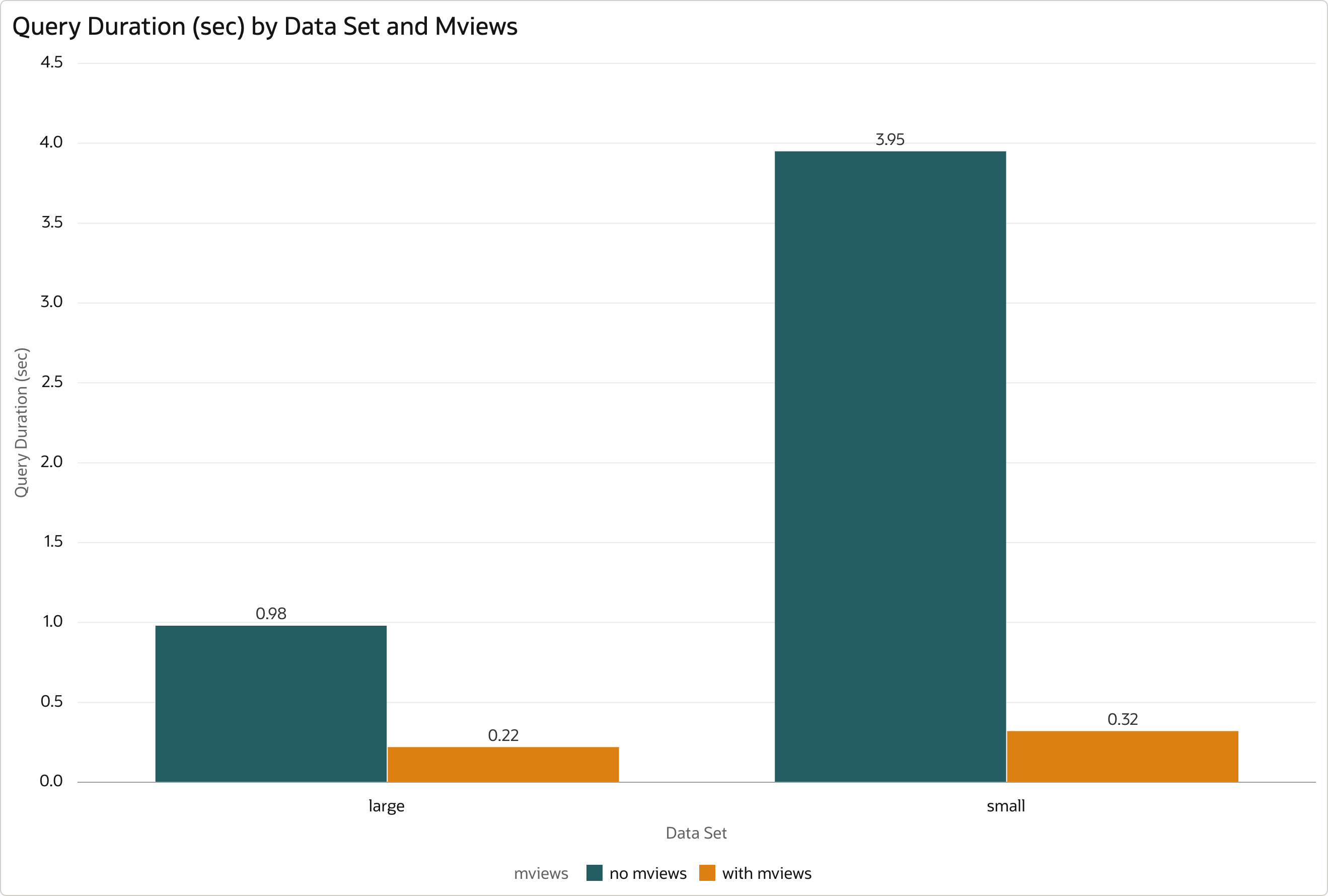
| Data Set | Views - Avg Query Time | Views - Avg DB Time | Mviews - Avg Query Time | Mviews - Avg DB Time | Mviews Factor |
|---|---|---|---|---|---|
| Large | 0.98 | 771.23 | 0.22 | 153.39 | 4.6 |
| Small | 3.95 | 2404.17 | 0.32 | 240.86 | 12.2 |
- Views - Avg Query Time - average elapsed time of the query running against views in seconds.
- Views - Avg DB Time - average DB Time of the query running against views.
- Mviews - Avg Query Time - average elapsed time of the query running against materialized views in seconds.
- Mviews - Avg DB Time - average DB Time of the query running against materialized views.
- Mviews Factor - Performance improvement of materialized views, calculated as “Views - Avg Query Time” / “Mviews - Avg Query Time” (the bigger the better).
The query runs significantly faster against materialized views compared to normal views. The performance improvement very much depends on the shape of JSON documents - with large data set the query performs on average 5x faster, with small data set it performs 12x faster. The ratio is the same for both elapsed time and DB Time.
I did not test the performance with multiple concurrent sessions and different types of queries. However, I assume the advantage of materialized views will be even more visible - allowing much more concurrent users with better response to end user queries.
If your data and queries exhibit similar performance gains, I recommend considering materialized views instead of querying JSON documents via views or directly. Although the maintenance of materialized views significantly impacts the data load, it is outweighted by the much better latency and concurrency of user queries.
Considerations
There are many ways how to work with JSON data. You may consider the following ideas and changes in the solution design, as they might be appropriate for your needs.
- Use standard tables with JSON column(s), instead of JSON Collection Table.
- Use different partitioning model for the JSON Collection Table and materialized views.
- Load JSON Collection Table with INSERT SELECT FROM EXTERNAL method via ORACLE_BIGDATA access driver.
- Use materialized views refreshed as COMPLETE or FAST ON DEMAND, possibly using Partition Change Tracking.
- Use JSON-Relational Duality View instead of JSON Collection Table. You will not need materialized views with this approach.
- Transform and flatten JSON documents outside the database, for example using OCI Data Integration.
Resources
- Oracle Database 23ai JSON capabilities: JSON Developer’s Guide.
- Overview of Oracle Scheduler: Oracle Scheduler Concepts.
- Program to generate test JSON documents: file-generator.
- PLSQL package for loading JSON documents to database: file-loader.