Automate Publishing of Data Shares from Autonomous Database

Introduction
Data Sharing Options
The last step in most data pipelines is publishing the final data product to entitled internal and external consumers. With Oracle Autonomous Database (ADB), you have several ways how to securely publish data:
- SQL - consumers access data directly via SQL from JDBC or ODBC clients.
- REST API - data is published as REST API, using Oracle REST Data Services (ORDS).
- GraphQL - data is published as GraphQL queries, also supported by ORDS.
- Streaming - database transactions are streamed via GoldenGate service to Kafka or other messaging systems.
- Object Storage - data is exported to Object Storage and accessed via S3 API or OCI API.
- Delta Sharing - data is shared from ADB using Delta Sharing open-source protocol.
In this post I will demonstrate how you can easily use Delta Sharing for automated publishing of General Ledger star schema from the Autonomous Database.
My intention is to show data sharing on realistic use case and with reasonably large data set. General Ledger star schema is an example of a typical dimensional model you can find in many data warehouses, with large fact table and multiple smaller dimensions. I simulate the daily load frequency of this schema and show how the data sharing can be incorporated into the loading pipeline.
Benefits of Delta Sharing
Why did I choose Delta Sharing? It has several advantages over the other options:
- It is designed for publishing of large data sets.
- It supports versioning of data sets and incremental publishing.
- It shares both data and metadata (data schemas).
- It supports fast acces to shared data.
- Accessing the shared data does not impact the data provider.
- It is designed for heterogeneous environments, across technologies, clouds, and organizations.
- Delta Sharing is open-source protocol, supported by many technologies.
Post Topics
As this is quite long post, here are the links to individual sections.
- Use Case - source data, loading pipeline, and data sharing requirements.
- Concept - Delta Sharing concept and how does it fit our scenario.
- Creating Data Share - how to create and configure data share.
- Publishing Data Share - how to publish data share, automate the publishing, and monitor performance.
- Managing Data Share Versions - how to manage data share versions.
- Creating Data Share Recipient - how to create recipient and generate data share profile.
- Accessing Data Share - how to connect to data share and refresh authentication token.
- Resources - links to useful documentation pages, blog posts, and other resources.
Use Case
Data Model
The data to be shared represents a simple star schema with General Ledger transactions (called journals) as fact table.

GL_JOURNALS- fact table with the granularity of GL journal lines.GL_ACCOUNTS- dimension containing GL account hierarchy.GL_CURRENCIES- dimension containing currencies.GL_ORGANIZATIONS- dimension containing organizational hierarchy.GL_JOURNAL_LINE_TYPES- dimension with transaction types.GL_PERIODS- dimension containing accounting periods.GL_PROJECTS- dimension containing project hierarchy.
The tables are located in the database schema SHARE_PROVIDER.
Data Pipeline
The General Ledger star schema is loaded via Data Integration pipeline gl-pipeline
running with daily frequency.
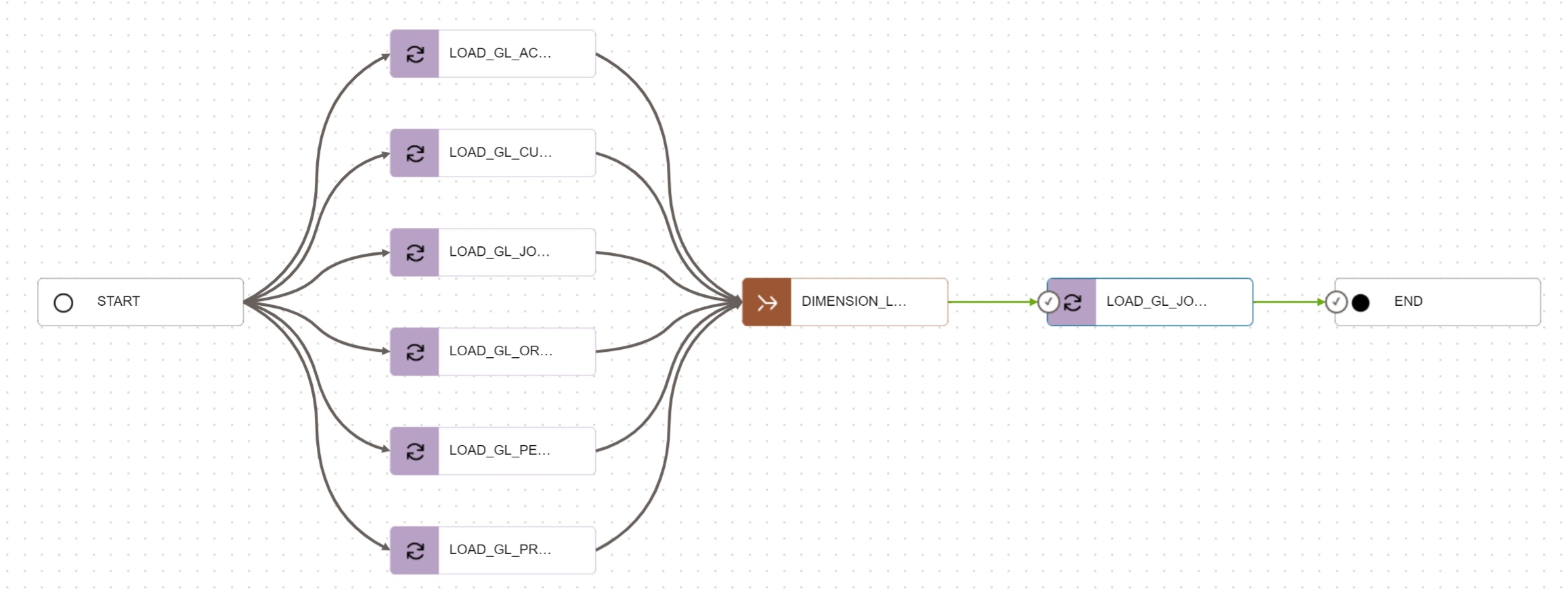
Dimensions are loaded in parallel as they do not depend on each other. Once all the
dimensions are up-to-date, the pipeline proceeds with the load of the fact table. The fact
table GL_JOURNALS is interval partitioned by JOURNAL_POSTED_DATE. Every daily load
produces a new partition in the fact table.
Data Sharing Requirements
-
All the tables belonging to the General Ledger star schema (i.e., the fact table and all the dimensions) must be shared with the consumers.
-
The new data loaded by the pipeline
gl-pipelinemust be shared after the whole pipeline is finished. The shared data must be consistent and valid as of the end of the pipeline. If the pipeline run does not finish for the day, the consumers must see data as of the previous day. -
Data must be shared only with the consumers registered by the data steward of the General Ledger star schema. Data steward must be able to add new consumers or revoke access from existing consumers anytime.
-
The load of ADB instance with the General Ledger star schema should not be impacted by consumers accessing and analyzing the shared data. In other words, the access to shared data should be decoupled from the ADB usage.
-
And finally, it must be possible to automate all the steps for publishing and managing shared data. Data publishing step should be added to the end of the data pipeline.
Concept
Delta Sharing
Delta Sharing is a modern data sharing protocol, initially developed by Databricks and later open-sourced. It enables secure and efficient data sharing across locations and organizations. It provides high-performance and cost-effective solution for sharing large datasets without the need for data duplication or complex ETL processes.
Oracle Autonomous Database supports the Delta Sharing protocol, both as a Data Provider and as a Data Recipient. In this post I will show how to use ADB as the Data Provider.
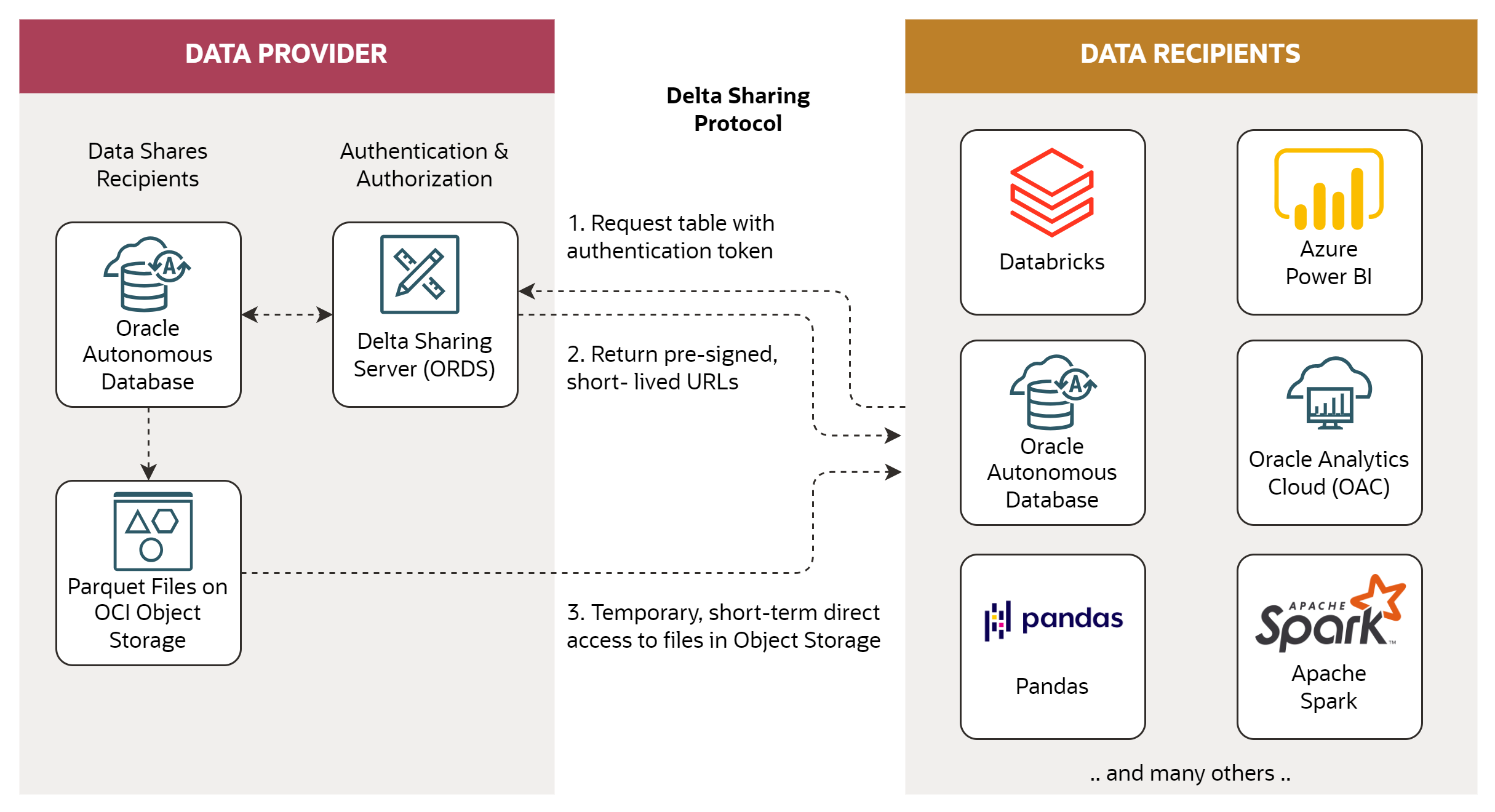
Oracle Autonomous Database supports creation and management of data shares and recipients. It also contains an implementation of the Delta Sharing server, that receives requests from Delta Sharing clients, authenticates and authorizes the requests, and generates short-term pre-authenticated requests (PARs) to reach the shared data. Data is stored in OCI Object Storage, which is directly accessed by clients via PARs.
Note the Delta Sharing support is currently available with Autonomous Database Serverless. It is not yet available with Autonomous Database on Dedicated Exadata Infrastructure.
Terms
- Cloud Storage Link - location where shared data is exported (Object Storage bucket and credential).
- Data Share - named collection of tables or views that are shared with recipients.
- Data Share Recipient - internal or external consumer who can access data share.
- Data Share Version - data share is versioned; recipients may usually access only the latest version.
- Data Share Publishing - process which exports data share and makes the new version available to recipients.
- Activation Link - link used to download data share profile with authentication token.
- Data Share Profile - JSON document with Delta Sharing endpoint and authentication token.
Meeting the Requirements
Delta Sharing in Autonomous Database nicely fits the scenario and all the requirements.
-
To share data, you have to create a data share and specify tables and/or views in the data share. Consumers (recipients in Delta Sharing terminology) will see all the tables and views that are part of the data share. In our scenario, the data share will contain all the tables belonging to the General Ledger star schema.
-
Shared data is not visible until it is published. ADB supports sharing of versioned data - every time a data share is published, a new version is created containing all the data in shared tables as of the time of publishing. In our scenario, the data share will be published every day, after all the tables in the General Ledger star schema are loaded.
-
The publisher must specify recipients of the data share. The publisher may choose to share the profile link with recipients via email or some other methods. The profile contains the data share endpoint and the authentication token. Existing recipients may be removed from the data share if required.
-
When recipients access the data share, they do not access data in the Autonomous Database. Instead, they access Parquet files in the Object Storage bucket, which are created when the data share is published. Reading from the Object Storage does not impact the ADB database.
-
All the data sharing steps may be scripted and automated with the dictionary package
DBMS_SHARE. This post shows how to do so. You may also try an excellent LiveLab Implement Data Sharing with PL/SQL.
Creating Data Share
Create Object Storage Bucket
Data shared from ADB via Delta Sharing will be stored in an Object Storage bucket. The bucket must exist before the data share is configured.
oci os bucket create --compartment-id <compartment OCID> --namespace-name <namespace> --name adb-delta-sharing
This command uses OCI CLI to create new bucket adb-delta-sharing that will store data
shared from ADB.
Enable User
In our scenario, data will be shared by the user SHARE_PROVIDER (owner of the General
Ledger schema). Before sharing data, the user must be enabled to use the DBMS_SHARE
package and the data share tool in Data Studio.
begin
dbms_share.enable_schema ( schema_name => 'SHARE_PROVIDER', privileges => dbms_share.priv_ords_acl );
dbms_cloud_admin.enable_resource_principal ( username => 'SHARE_PROVIDER' );
ords_admin.enable_schema ( p_schema => 'SHARE_PROVIDER' );
end;
/
The privilege PRIV_ORDS_ACL is used later to generate bearer token for data share
recipients by calling a local REST.
Note I enabled also Resource Principal authentication for accessing OCI sevices and usage of Oracle REST Data Service (ORDS). Instead of Resource Principal credential, you can use an API Key based credential.
The statement above has to be executed by an ADB administrator, i.e. user ADMIN. From
this step onward, all the other SQL and PLSQL commands should be executed by user
SHARE_PROVIDER.
Create Cloud Storage Link
Object Storage bucket is linked with data share via an object called Cloud Storage Link. Once the Cloud Storage Link is created, it must be assigned a credential, used for authenticating access to the bucket.
begin
dbms_share.create_or_replace_cloud_storage_link (
storage_link_name => 'DATA_SHARE_CLOUD_STORE',
uri => 'https://objectstorage.uk-london-1.oraclecloud.com/n/<namespace>/b/adb-delta-sharing/o/'
);
dbms_share.set_storage_credential (
storage_link_name => 'DATA_SHARE_CLOUD_STORE',
credential_name => 'OCI$RESOURCE_PRINCIPAL'
);
commit;
end;
/
This command creates Cloud Storage Link DATA_SHARE_CLOUD_STORE for bucket
adb-delta-sharing, with Resource Principal credential. You may validate the Cloud
Storage Link by querying the dictionary view USER_LINEAGE_CLOUD_STORAGE_LINKS.
select storage_link_name, credential_name, uri
from user_lineage_cloud_storage_links
order by storage_link_name
/
Create Data Share
When the Cloud Storage Link is created, you can create the data share and assign Cloud Storage Link to it.
begin
dbms_share.create_share (
share_name => 'GL_JOURNALS_SHARE',
share_type => dbms_share.share_type_versioned,
storage_link_name => 'DATA_SHARE_CLOUD_STORE',
description => 'Sample share containing General Ledger Journals star schema',
log_level => dbms_share.log_level_detail
);
commit;
end;
/
This command creates versioned data share GL_JOURNALS_SHARE with data stored in the
Cloud Storage Link DATA_SHARE_CLOUD_STORE. You may validate the created data share by
querying the dictionary view USER_SHARES.
select share_name, share_type, current_version, description
from user_shares
where share_name = 'GL_JOURNALS_SHARE'
/
Add Tables to Data Share
Once the data share is created, you can add tables or views to the Share. Note that adding tables to the data share does not export any data. For this, the Share must be published.
begin
dbms_share.add_to_share (
share_name => 'GL_JOURNALS_SHARE',
table_name => 'GL_ACCOUNTS'
);
dbms_share.add_to_share (
share_name => 'GL_JOURNALS_SHARE',
table_name => 'GL_CURRENCIES'
);
dbms_share.add_to_share (
share_name => 'GL_JOURNALS_SHARE',
table_name => 'GL_JOURNAL_LINE_TYPES'
);
dbms_share.add_to_share (
share_name => 'GL_JOURNALS_SHARE',
table_name => 'GL_ORGANIZATIONS'
);
dbms_share.add_to_share (
share_name => 'GL_JOURNALS_SHARE',
table_name => 'GL_PERIODS'
);
dbms_share.add_to_share (
share_name => 'GL_JOURNALS_SHARE',
table_name => 'GL_PROJECTS'
);
dbms_share.add_to_share (
share_name => 'GL_JOURNALS_SHARE',
table_name => 'GL_JOURNALS'
);
commit;
end;
/
The above statement adds all tables from the General Ledger star schema to the data share
GL_JOURNALS_SHARE. You can check the tables belonging to this Share by querying
dictionary view USER_SHARE_TABLES.
select share_name, share_schema_name, share_table_name, object_type, table_owner, table_name, status
from user_share_tables
where share_name = 'GL_JOURNALS_SHARE'
order by share_schema_name, share_table_name
/
Modify Data Share Property
Optionally, you may also need to modify some property of the data share.
begin
dbms_share.update_share_property (
share_name => 'GL_JOURNALS_SHARE',
share_property => 'SPLIT_SIZE',
new_value => '64000000'
);
commit;
end;
/
This statement modifies property SPLIT_SIZE to 64 MB from the default of 128 MB. This
property specifies the maximum size of single file created during publishing of the Share.
Publishing Data Share
Publish Share
Once the data share is created and tables are added to it, you can publish the Share by
calling PUBLISH_SHARE or PUBLISH_SHARE_WAIT procedure. Publishing will export all
tables in the Share to the bucket defined by Cloud Storage Link. Once the Share is
published, recipients may read data from the Share.
begin
dbms_share.publish_share_wait(
share_name => 'GL_JOURNALS_SHARE'
);
end;
/
This statement will publish the Share and wait until the publishing process is finished.
If you do not want to wait, use PUBLISH_SHARE instead. You can check the published
versions by querying dictionary view USER_SHARE_VERSIONS.
select share_name, share_version, status, num_files, export_time
from user_share_versions
where share_name = 'GL_JOURNALS_SHARE'
order by share_version desc
/
Add Publish Share to Pipeline
To automate publishing of the General Ledger star schema at the end of the loading
process, you can create a new SQL task PUBLISH_GL and add the task to the end of the
pipeline.
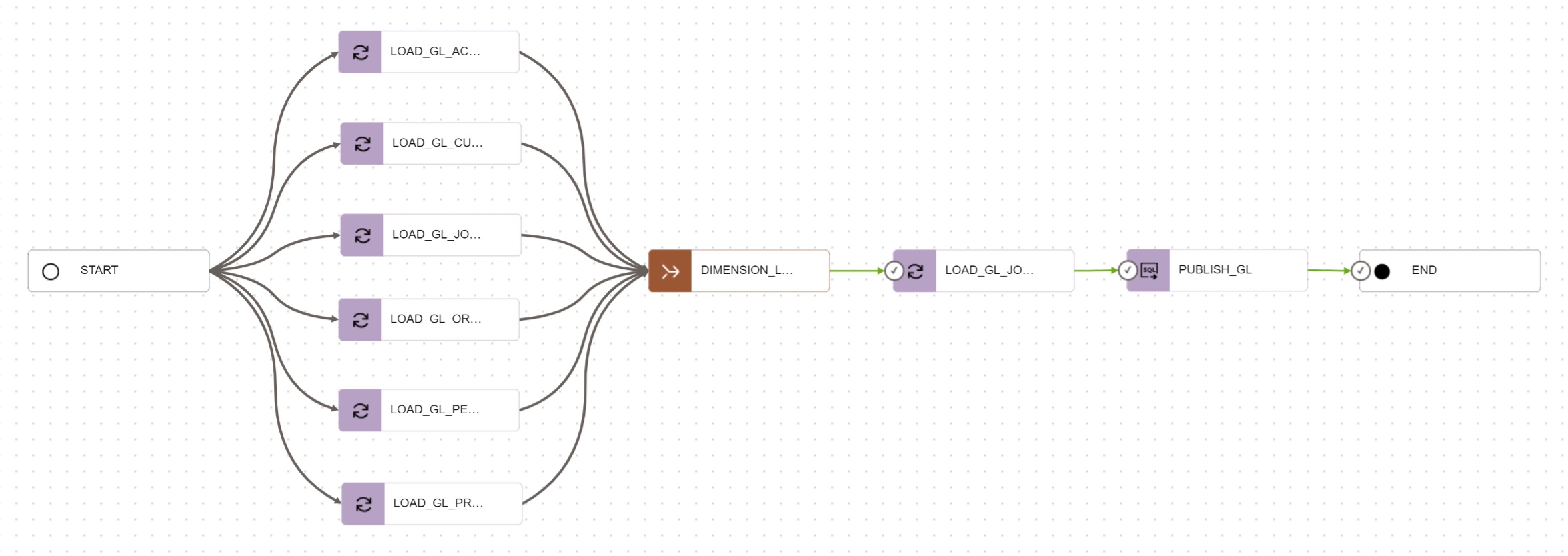
Note that if the pipeline is implemented with OCI Data Integration service, it is
necessary to encapsulate the call to DBMS_SHARE into a standalone PLSQL procedure, as
OCI Data Integration does not support calling procedures from packages.
create or replace procedure publish_share_wait (
p_share_name in varchar2
) authid current_user is
begin
dbms_share.publish_share_wait(
share_name => p_share_name
);
end publish_share_wait;
/
Size of Published Data
To understand the size of Object Storage required for published data share, I executed the
loading pipeline for every day of April 2023. After every load I measured the size of
Object Storage files used by the GL_JOURNALS_SHARE and compared it with the size of the
General Ledger star schema in the ADB database.
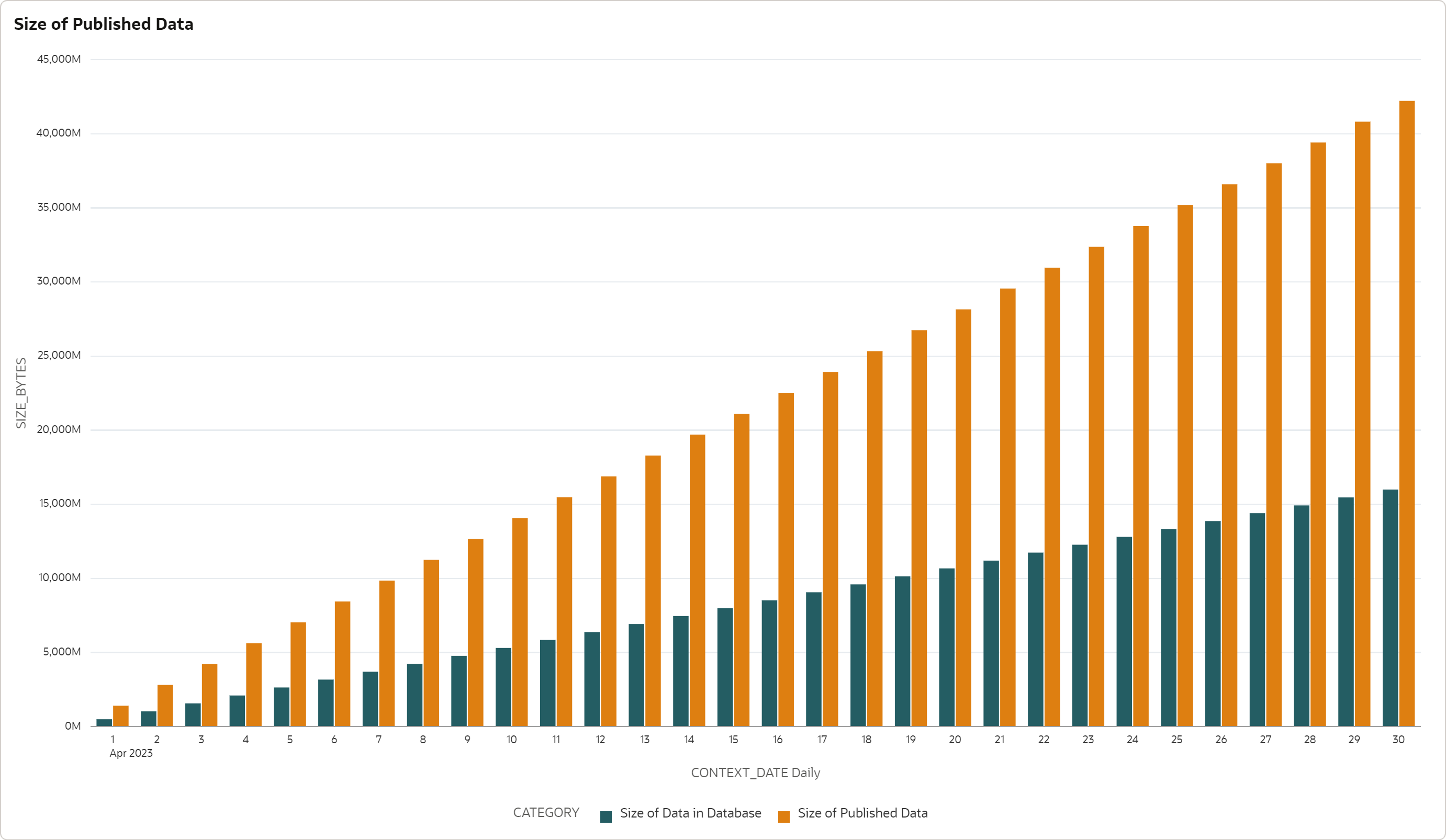
Every daily load adds about 7.6 million rows to the GL_JOURNALS fact table. This
corresponds to about 500 MB of data allocated by every partition in the GL_JOURNALS
table. The total size for 30 days is about 230 million rows and 16 GB of data. The loading
process does not delete any data - the data volumes are constantly growing.
The table is by default compressed with Hybrid Columnar Compression (HCC) with COMPRESS
FOR QUERY HIGH. Without the compression, a single partition would consume about 2.3 GB,
i.e. the compression ratio for our data is 4.5x. Data added by the dimensional tables are
negligible compared to the fact table.
Data published by GL_JOURNALS_SHARE consume about 1.4 GB for every day and 42 GB for the
whole month. This means that (for our scenario) the data share consumes about 2.6x more
space in Object Storage than what is allocated to the same data in ADB storage.
The higher storage requirements are caused by the different storage mechanism - HCC compressed tables in ADB versus Parquet files used by Delta Sharing. Also, Parquet files are compressed with Snappy compression, with significantly lower compression ratio than HCC.
Note that the figures presented here are specific for our scenario. The compression and comparison ratios will differ depending on your data sets. I strongly recommend testing the ratios on your data sets.
Duration of Publish Process
I also measured the duration of the publish process (i.e., the duration of
DBMS_SHARE.PUBLISH_SHARE_WAIT) to understand the impact of this step on the overall
duration of the data loading pipeline.
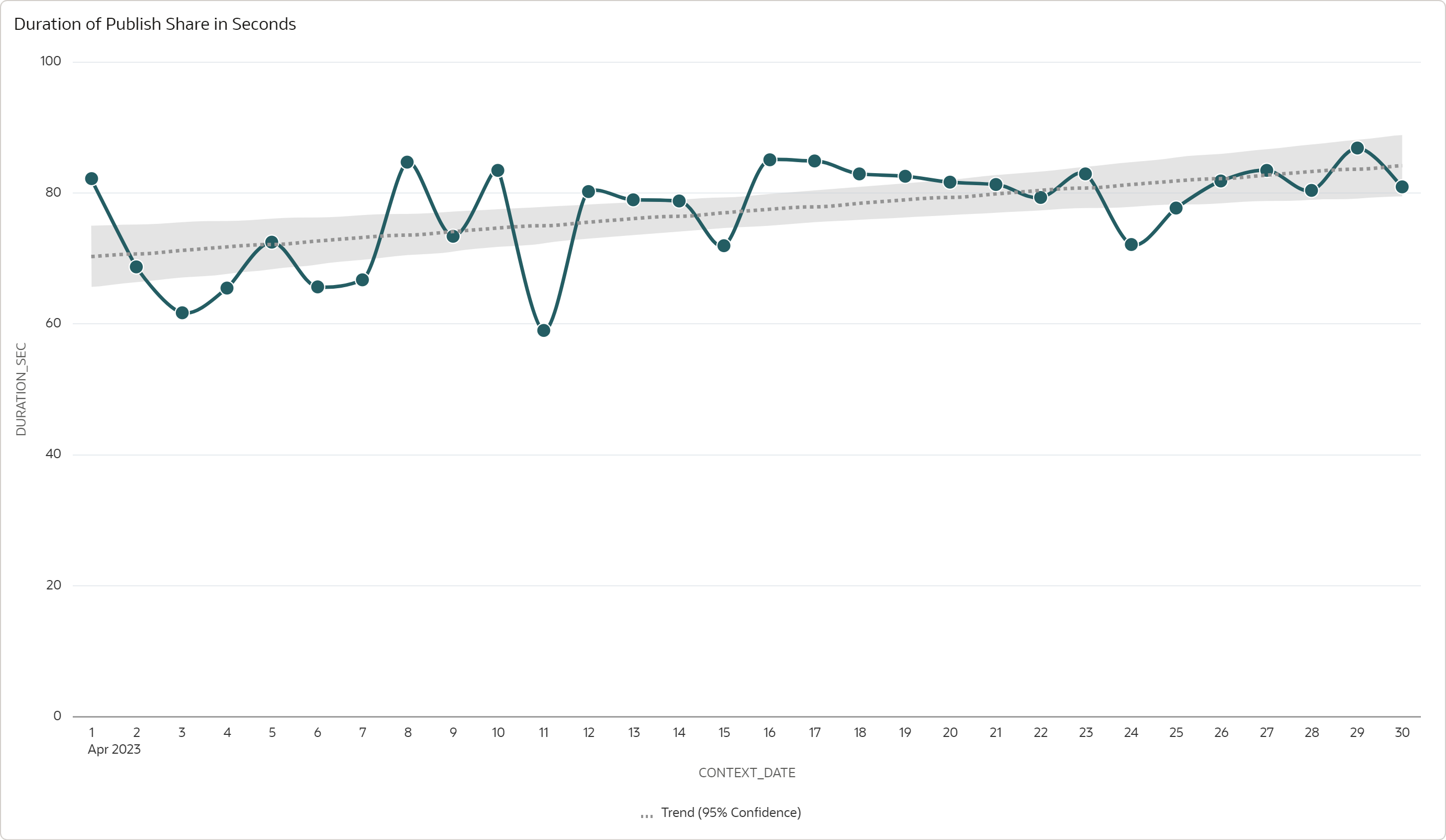
The duration took about 80 seconds per day and it remained constant during the month, even though the amount of data increased with every day. This is an important observation, as it means the duration depends on the size of the increment, and not on the overall size of the data share.
I believe that the publishing process implemented in ADB takes advantage of the fact that,
in our scenario, the fact table GL_JOURNALS is partitioned, with daily load inserting data
into one partition only. The process tracks the changes per partition and it can therefore
export only the data from the new partition.
Possibly, if the table is not partitioned or the daily load also updates the previously loaded data, the performance of the publishing process will be worse, as the process will have to do more work to identify changed data. Note this is my assumption only; I did not test the performance for different data models and load patterns.
Debugging the Publish Process
In case there are some errors in the publishing process, it is useful to examine the log
records by querying the dictionary view USER_SHARE_EVENTS.
select share_name, time, status, object_name, partition_name, details
from user_share_events
where share_name = 'GL_JOURNALS_SHARE'
and status = 'ERROR'
order by share_name, time
/
The log or error message is in the DETAILS column in the JSON format.
{
"message": "ODI_STATEMENT_FAILED",
"session_id": "752907641",
"trace": null,
"jobID": "32",
"objectOwner": "SHARE_PROVIDER",
"objectName": "GL_JOURNALS",
"odiJobID": "6",
"odiTaskStatus": "F",
"partitionName": "SYS_P3131",
"splitOrder": "2",
"executionInfo": {
"status": "FAILED",
"temp_folder": "/tmp",
"retry_count": 0,
"logs": [
"UPLOAD:File(GL_JOURNALS_SHARE_667631/SHARE_PROVIDER/GL_JOURNALS/SYS_P3131/V55_385S-385.parquet) exceeds max size(256MB)."
],
"file_details": [
{
"path_uri": "GL_JOURNALS_SHARE_667631/SHARE_PROVIDER/GL_JOURNALS/SYS_P3131/V55_385S-385.parquet",
"file_size": 309993764,
"generated": true,
"uploaded": false
}
]
}
}
Note the above error occured in older version of ADB and it was corrected since then.
Structure of Files in Object Storage
And finally, it is interesting to review the structure of files generated when publishing a data share. Although you cannot influence the naming pattern and you should not manage and access the files manually, you can use this information to understand how different objects are treated when published.
SQL> select object_name
2 from dbms_cloud.list_objects (
3 credential_name => 'OCI$RESOURCE_PRINCIPAL',
4 location_uri => 'https://objectstorage.uk-london-1.oraclecloud.com/n/<namespace>/b/adb-delta-sharing/o/'
5 )
6 where object_name like 'GL_JOURNALS_SHARE%'
7 order by object_name
8* /
OBJECT_NAME
_______________________________________________________________________________
GL_JOURNALS_SHARE_667631/SHARE_PROVIDER/GL_ACCOUNTS/V55_380S-380.parquet
GL_JOURNALS_SHARE_667631/SHARE_PROVIDER/GL_ACCOUNTS/V56_413S-413.parquet ...
GL_JOURNALS_SHARE_667631/SHARE_PROVIDER/GL_CURRENCIES/V55_379S-379.parquet
GL_JOURNALS_SHARE_667631/SHARE_PROVIDER/GL_CURRENCIES/V56_414S-414.parquet ...
GL_JOURNALS_SHARE_667631/SHARE_PROVIDER/GL_JOURNALS/SYS_P3131/V55_385S-385.parquet
GL_JOURNALS_SHARE_667631/SHARE_PROVIDER/GL_JOURNALS/SYS_P3131/V55_386S-386.parquet ...
GL_JOURNALS_SHARE_667631/SHARE_PROVIDER/GL_JOURNALS/SYS_P3132/V56_419S-419.parquet
GL_JOURNALS_SHARE_667631/SHARE_PROVIDER/GL_JOURNALS/SYS_P3132/V56_420S-420.parquet ...
GL_JOURNALS_SHARE_667631/SHARE_PROVIDER/GL_JOURNAL_LINE_TYPES/V55_381S-381.parquet
GL_JOURNALS_SHARE_667631/SHARE_PROVIDER/GL_JOURNAL_LINE_TYPES/V56_415S-415.parquet ...
GL_JOURNALS_SHARE_667631/SHARE_PROVIDER/GL_ORGANIZATIONS/V55_382S-382.parquet
GL_JOURNALS_SHARE_667631/SHARE_PROVIDER/GL_ORGANIZATIONS/V56_416S-416.parquet ...
GL_JOURNALS_SHARE_667631/SHARE_PROVIDER/GL_PERIODS/V55_383S-383.parquet
GL_JOURNALS_SHARE_667631/SHARE_PROVIDER/GL_PERIODS/V56_417S-417.parquet ...
GL_JOURNALS_SHARE_667631/SHARE_PROVIDER/GL_PROJECTS/V55_384S-384.parquet
GL_JOURNALS_SHARE_667631/SHARE_PROVIDER/GL_PROJECTS/V56_418S-418.parquet ...
1,020 rows selected.
SQL>
As you can see, files use the following naming pattern:
<Share Storage Folder>/<Share Schema>/<Share Table>[/<Partition Name>]/<Share Version>_<File ID>.parquet
- Share Storage Folder - top level folder for the data share (see
USER_SHARES.STORAGE_FOLDER) - Share Schema - owner of the data share
- Share Table - name of table in the data share
- Partition Name - name of the partition (for partitioned tables only)
- Share Version - published version
- File ID - internal file identifier to ensure uniqueness of files
Managing Data Share Versions
Drop Old Shares
Whenever you publish the versioned data share, a new version of data share is created. This version requires space in the Object Storage. So it is a good practice to regularly purge unused versions to preserve space. There are several procedures you can use to drop old versions. Note that the current version cannot be dropped.
DBMS_SHARE.DROP_SHARE_VERSION- drop a single version.DBMS_SHARE.DROP_SHARE_VERSIONS- drop range of versions.DBMS_SHARE.DROP_UNUSED_SHARE_VERSIONS- drop all versions with the exception of current one.
If you want to have an option to return to older versions, you might consider more
complex scenario, in which you keep the latest N versions and drop all the others. Below
is the procedure DROP_OLD_VERSIONS that implements this logic.
create or replace procedure drop_old_versions (
p_share_name in varchar2,
p_keep_versions in number
) authid current_user is
v_delete_from_version number;
v_delete_to_version number;
begin
/* get versions to drop */
select
min(share_version), max(share_version)
into
v_delete_from_version, v_delete_to_version
from (
select share_version, status, rank() over (order by share_version desc) as version_rank
from user_share_versions
where share_name = p_share_name
)
where version_rank > p_keep_versions;
/* drop old versions */
if (v_delete_from_version is not null) then
dbms_share.drop_share_versions (
share_name => p_share_name,
from_share_version => v_delete_from_version,
to_share_version => v_delete_to_version,
destroy_objects => true,
force_drop => true
);
end if;
end drop_old_versions;
/
Add Drop Old Share to Pipeline
To automate the deletion of old versions you can create a new SQL task DROP_OLD_VERSIONS
and add the task to the end of the pipeline, directly after the PUBLISH_GL task.
Return to Previous Version
Sometimes you might need to revert the publish process and return to the previous version. You can do this easily using the procedure:
DBMS_SHARE.SET_CURRENT_SHARE_VERSION- set the version as current.
For example, the following procedure REVERT_TO_PREVIOUS_VERSION returns to the previous
version by seting the previous version as current and dropping the latest version.
create or replace procedure revert_to_previous_version (
p_share_name in varchar2
) authid current_user is
v_latest_version number;
v_previous_version number;
begin
/* get latest and previous versions */
select
min(share_version), max(share_version)
into
v_previous_version, v_latest_version
from (
select share_version, status, rank() over (order by share_version desc) as version_rank
from user_share_versions
where share_name = p_share_name
)
where version_rank <= 2;
/* set previous version as current and drop the latest version */
if (v_previous_version < v_latest_version) then
dbms_share.set_current_share_version (
share_name => p_share_name,
share_version => v_previous_version
);
dbms_share.drop_share_version (
share_name => p_share_name,
share_version => v_latest_version,
destroy_objects => true
);
end if;
end revert_to_previous_version;
/
Visibility of Versions
By default, recipients see the current version of the data share. When you publish a new version or revert to the previous version, recipients will automatically access the new current version. In most scenarios this is the required behaviour, as it means the recipients will always get the correct data.
However, you can change the default behaviour and allow access to all versions. This is
done by modifying the data share and recipient properties VERSION_ACCESS as shown below.
begin
dbms_share.update_recipient_property (
recipient_name => 'SAMPLE_RECIPIENT',
recipient_property => 'VERSION_ACCESS',
new_value => dbms_share.version_access_any
);
dbms_share.update_share_property (
share_name => 'GL_JOURNALS_SHARE',
share_property => 'VERSION_ACCESS',
new_value => dbms_share.version_access_any
);
end;
/
Creating Data Share Recipient
Create Recipient
A recipient must be created for every consumer of data share. The email address is used by Data Studio to send the activation link.
begin
dbms_share.create_share_recipient (
recipient_name => 'SAMPLE_RECIPIENT',
description => 'Recipient used by OAC reporting',
email => 'some.user@example.com'
);
commit;
end;
/
You can validate the created recipient by querying dictionary view
USER_SHARE_RECIPIENTS. Note that email address is not visible through this view.
select recipient_name, recipient_id, recipient_type, description
from user_share_recipients
where recipient_name = 'SAMPLE_RECIPIENT'
/
Allow Recipient to Access Data Share
A newly created recipient does not have access to any data share. The access has to be explicitly granted.
begin
dbms_share.grant_to_recipient (
share_name => 'GL_JOURNALS_SHARE',
recipient_name => 'SAMPLE_RECIPIENT'
);
end;
/
The data shares a recipient can access are visible in the dictionary view
USER_SHARE_RECIPIENT_GRANTS.
select recipient_name, recipient_id, share_name, share_id
from user_share_recipient_grants
where recipient_name = 'SAMPLE_RECIPIENT'
order by share_name
/
Modify Recipient Property
Optionally, you may also need to modify some property of the recipient.
begin
dbms_share.update_recipient_property (
recipient_name => 'SAMPLE_RECIPIENT',
recipient_property => 'TOKEN_LIFETIME',
new_value => '90 00:00:00'
);
commit;
end;
/
This statement modifies property TOKEN_LIFETIME to 90 days. This property specifies the
time during which the token is valid. After this time, the recipient looses access to the
data share, until he requests a new token.
Get Data Share Profile
To use a data share, the recipient needs data share profile. The profile is a small JSON file, containing authentication token, endpoint of the Delta Sharing server, and few other attributes. The profile may be either downloaded from the activation link by the recipient or you may create it and share with the recipient.
Note that ownership of the activation link or the profile enables a person to access the data share. Therefore, you should distribute activation links and profiles securely and protect them like passwords, API keys, and other secrets.
Example of the profile file:
{
"shareCredentialsVersion" : 1,
"endpoint" : "https://xxxxxxxxxxxxxxx-myadw.adb.uk-london-1.oraclecloudapps.com/ords/share_provider/_delta_sharing/",
"bearerToken" : "xxxxxxxxxxxxxxxxxxxxxx",
"expirationTime": "2024-04-23T07:34:53.702Z",
"tokenEndpoint" : "https://xxxxxxxxxxxxxxx-myadw.adb.uk-london-1.oraclecloudapps.com/ords/share_provider/oauth/token",
"clientID" : "xxxxxxxxxxxxxxxxxxxxxxxx",
"clientSecret" : "xxxxxxxxxxxxxxxxxxxxxxxx"
}
Activation Link
You can generate an activation link and share it with the recipient. When the recipient opens the link in a browser, he can download the profile file. Note the activation link may be used only once and it expires after the specified number of seconds.
declare
v_activation_link varchar2(1000);
begin
v_activation_link := dbms_share.get_activation_link(
recipient_name => 'SAMPLE_RECIPIENT',
expiration => 1*24*60*60
);
dbms_output.put_line(v_activation_link);
end;
/
The activation link looks like this:
https://xxxxxxxxxxxxxxx-myadw.adb.uk-london-1.oraclecloudapps.com/ords/_adpshr/delta-sharing/download?key=xxxxxxxxxxxxxxx=
Generate the Profile
As an alternative to activation link, you can create the profile directly using the
POPULATE_SHARE_PROFILE procedure.
declare
v_share_profile sys.json_object_t;
v_share_profile_text varchar2(4000);
begin
dbms_share.populate_share_profile(
recipient_name => 'SAMPLE_RECIPIENT',
share_profile => v_share_profile
);
v_share_profile_text := v_share_profile.to_string;
dbms_output.put_line (json_query(v_share_profile_text, '$' pretty));
end;
/
Accessing Data Share
Connect to Data Share
Delta Sharing client requires the profile file to connect to the share. The following screenshot
shows how to create a Pandas dataframe from data share using the delta_sharing Python client.
Pandas is running in OCI Data Science notebook.
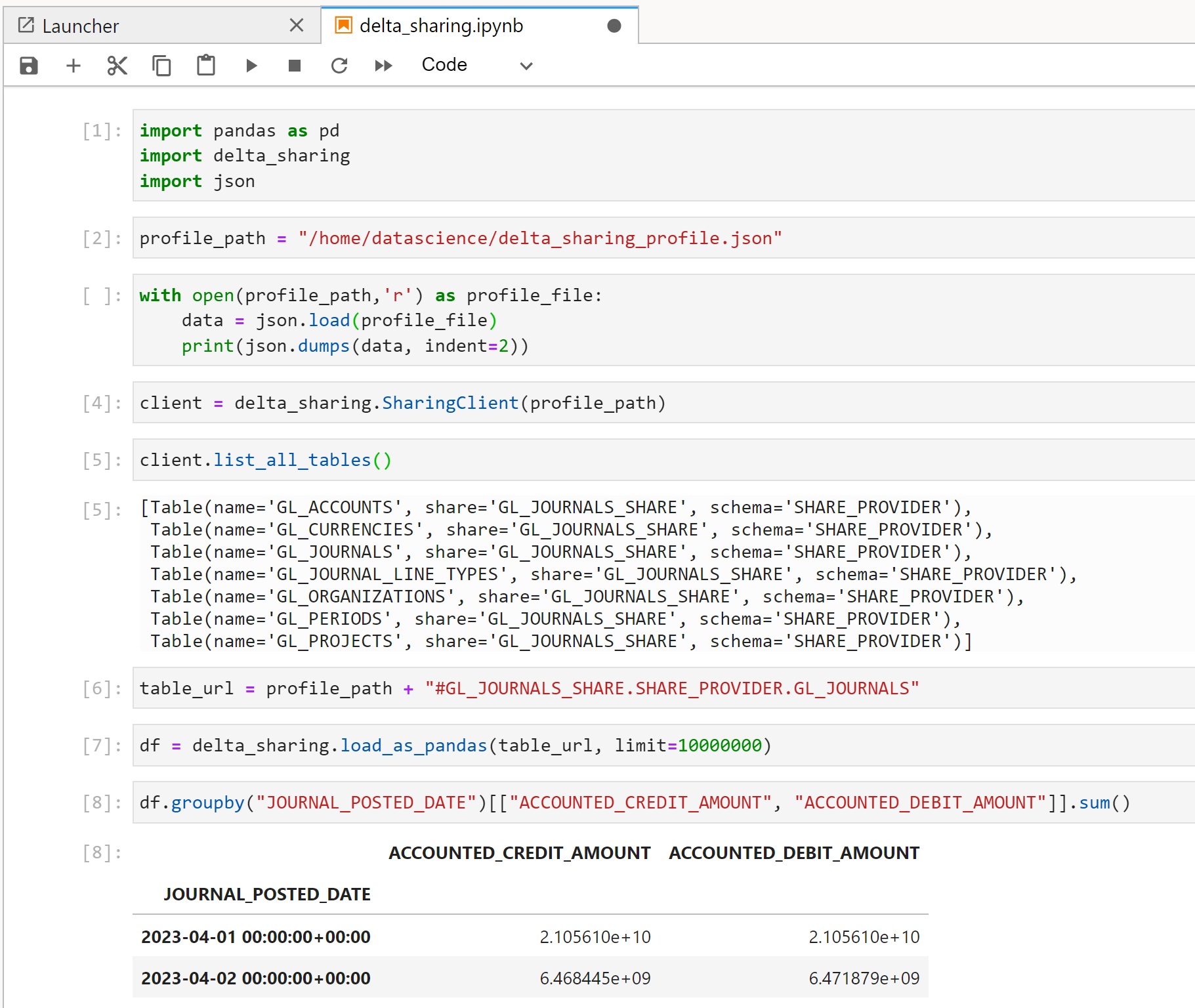
Note that I restricted the size of Pandas dataframe to 10 million rows. The reason is that Pandas loads the whole data set into memory and it crashes if the data set is larger then the available memory. For larger data sets, it is therefore better using Spark instead of Pandas. Or using larger instance with more than 16 GB of memory that I have.
Refresh Authentication Token
You may wonder what happens when the authentication token in the profile expires. In this case the recipient may request a new token from the Delta Sharing server using the REST POST call to the token endpoint.
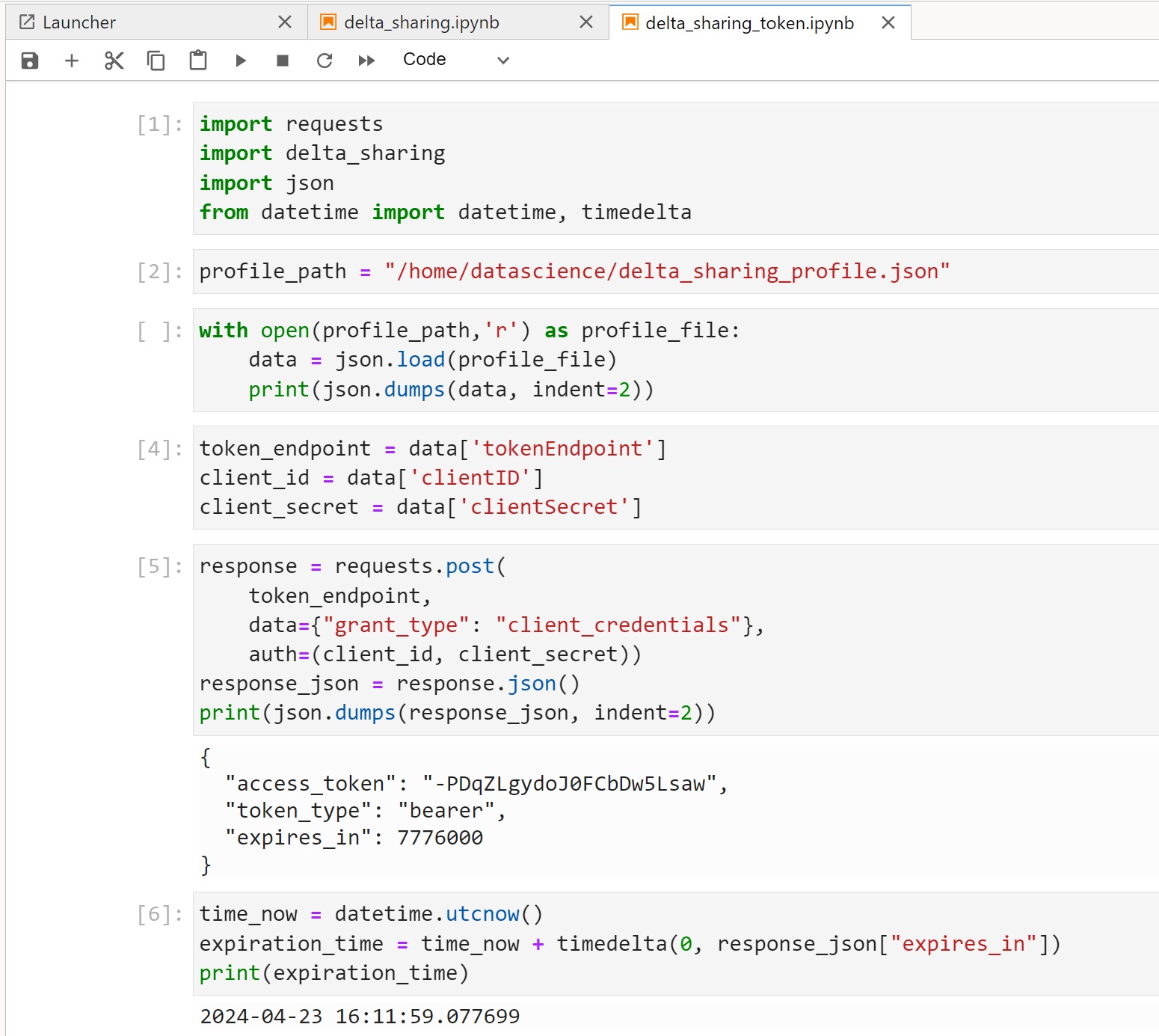
Note that both token endpoint and authentication parameters are provided in the profile.
Once you retrieve the new token from the field access_token, you can modify the profile
and replace value for bearerToken by this value.
The above example uses Python requests library to call the REST service. You could do
the same with Postman or curl.
Resources
- Delta Sharing on GitHub: Delta Sharing: An Open Protocol for Secure Data Sharing.
- Blog post introducting Delta Sharing in Autonomous Database from Alexey Filanovskiy: Unlimited data-driven collaboration with Data Sharing of Oracle Autonomous Database.
- Blog post describing data sharing between ADB and Databricks from Alexey Filanovskiy: How Oracle Autonomous Database Connects with Databricks Across Clouds.
- Oracle LiveLab on implementing Delta Sharing with PL/SQL: Implement Data Sharing with PL/SQL.
- Oracle LiveLab on implementing Delta Sharing with Data Studio: Implement Data Sharing with ADB Data Studio.
- Reference documentation on DBMS_SHARE package in Autonomous Database: DBMS_SHARE Package.