Decentralized Data Lake on OCI Object Storage (Part 2)

Introduction
This is the second part of the post describing Data Lake on Oracle Cloud Infrastructure (OCI) with OCI Object Storage as data store. The first part is available here: Decentralized Data Lake on OCI Object Storage (Part 1).
The first part addresses the organization of Compartments, Groups, Policies, Buckets, and Data Catalog assets in a multi-domain Data Lake, with decentralized and possibly geographically distributed data domains. In other words, the first part focuses on organization and governance of the Data Lake.
In the second part I look at the organization of data entities in the Data Lake. I outline how to map domains, data products, and entities to buckets and folders; how to name objects in the OCI Object Storage; how to work with partitioned entities; and how to use Data Lake entities in OCI Data Catalog and Autonomous Database.
Use Case
In this post I use the same use case as in the part 1. The use case is extremely simplified Data Lake for company providing communications services to customers, with Subscription, Usage, Billing, and Revenue Assurance domains, and data products publishing the main data entities from these domains.
Entities
Entity is a logical concept of a data structure containing information about a business entity. Entity can be realized in a Data Product as a stream, table, or data set. In our case, entity is a collection of objects in OCI Object Storage, with the same schema and format, and with data related to the same business entity.
Let’s assume the data products consist of the following entities:
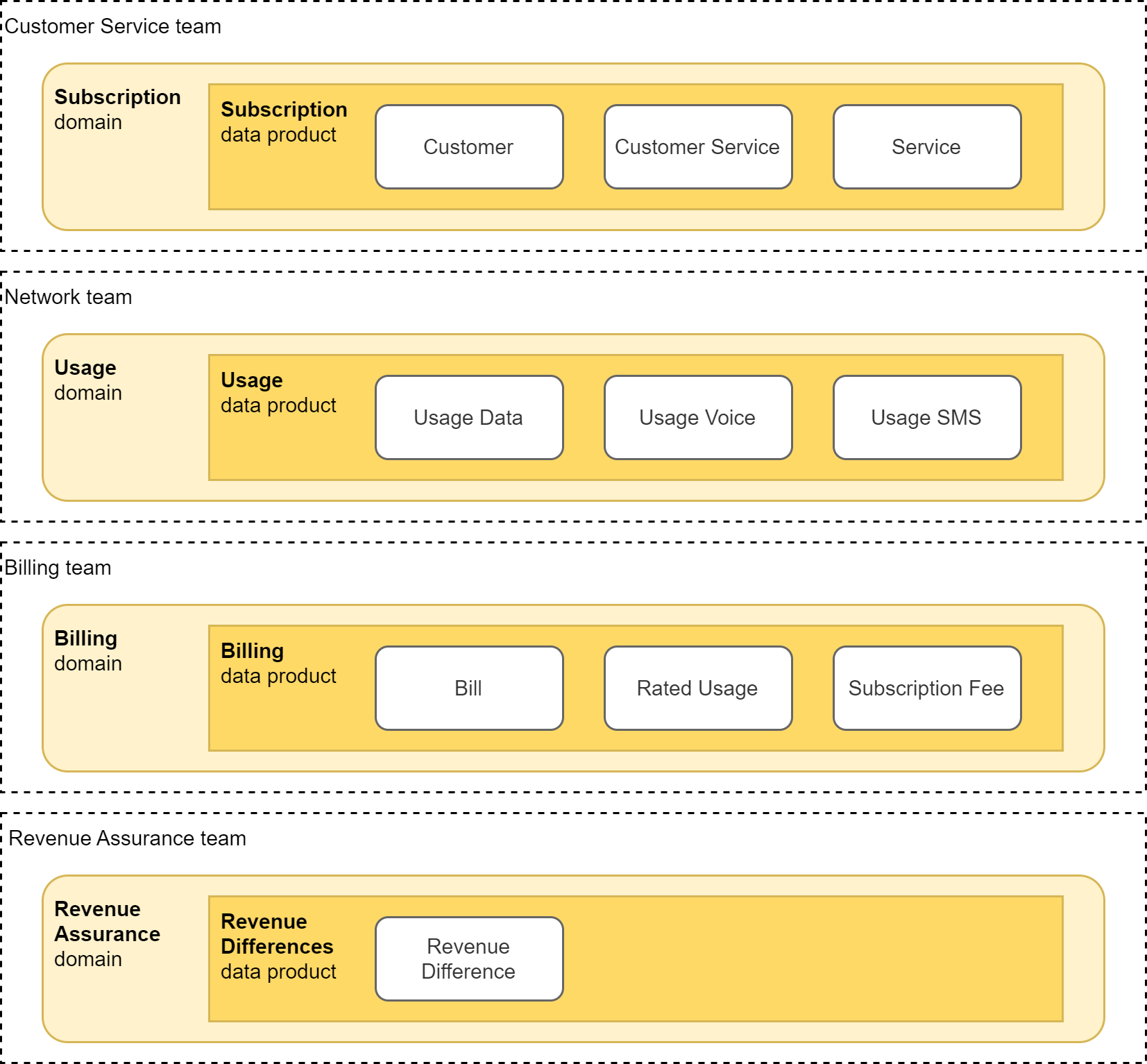
Subscription:
- Customer entity represents parties using services and products of the company.
- Service entity represents various services and products provided by the company.
- Customer Service entity represents services subscribed to or enabled by customers.
Usage:
- Usage Data entity represents usage records for data services.
- Usage Voice entity represents usage records for voice services.
- Usage SMS entity represents usage records for SMS services.
Billing:
- Bill entity represents itemized costs and consumption information for defined period.
- Rated Usage entity represents usage records with costs of consumed serviced.
- Subscription Fee entity represents costs of subscribed services and products.
Revenue Assurance:
- Revenue Difference entity represents differences between billed and calculated costs.
Partitions
Entities may be further decomposed into partitions to simplify data and lifecycle management and to improve performance of queries. Partitions are especially important for entities tracking temporal data. For these entities, partitions enable simple archival or deletion of historical data, they allow management operations on single partition, and they support partition pruning in queries.
In our simple use case, all the entities contain temporal data and should be therefore partitioned. (Actually, most entities in Data Lake contain bi-temporal data, with Event and Processing dates. Handling of bi-temporal data in a Data Lake is great topic for a future post and it is not described here.)
Organization of Data Products, Entities, and Partitions
This section describes how you can organize Data Products, Entities, and Partitions in the OCI Object Storage based Data Lake.
Logical Hierarchy
Before deciding on how to organize data, it is important to understand the logical hierarchy of Domains, Data Products, Entities, and Partitions. A simple hierarchy could look as follows.
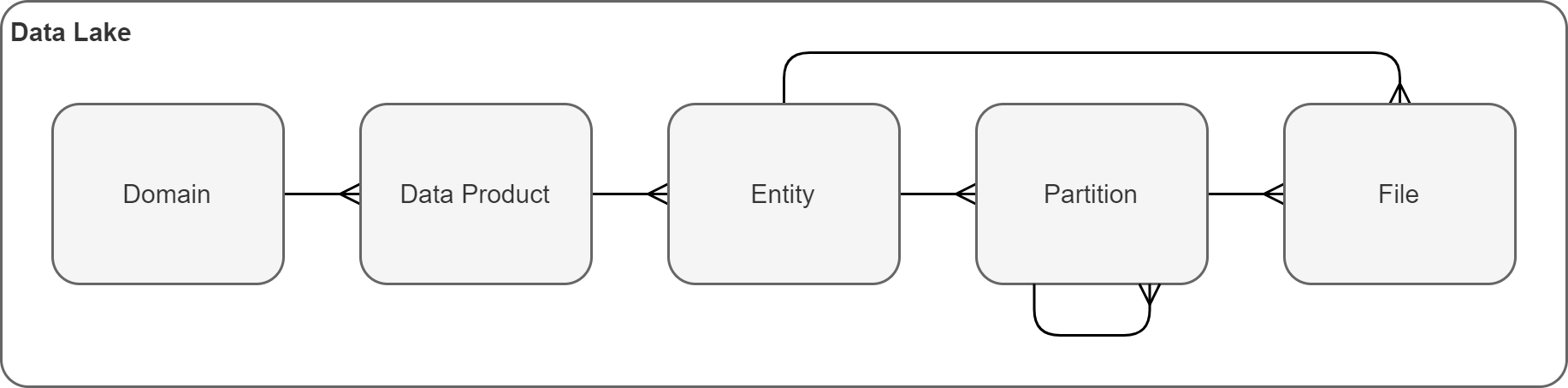
- Data Lake is a collection of Domains.
- Domain may contain multiple Data Products.
- Data Product consists of multiple Entities.
- Entity may optionally contain multiple Partitions.
- Partitions might have additional hierarchy (e.g., Year -> Month -> Day).
- Entity’s data are stored in one or more Files.
Physical Hierarchy
Mapping of the logical hierarchy to OCI Object Storage based Data Lake is depicted on the diagram below.
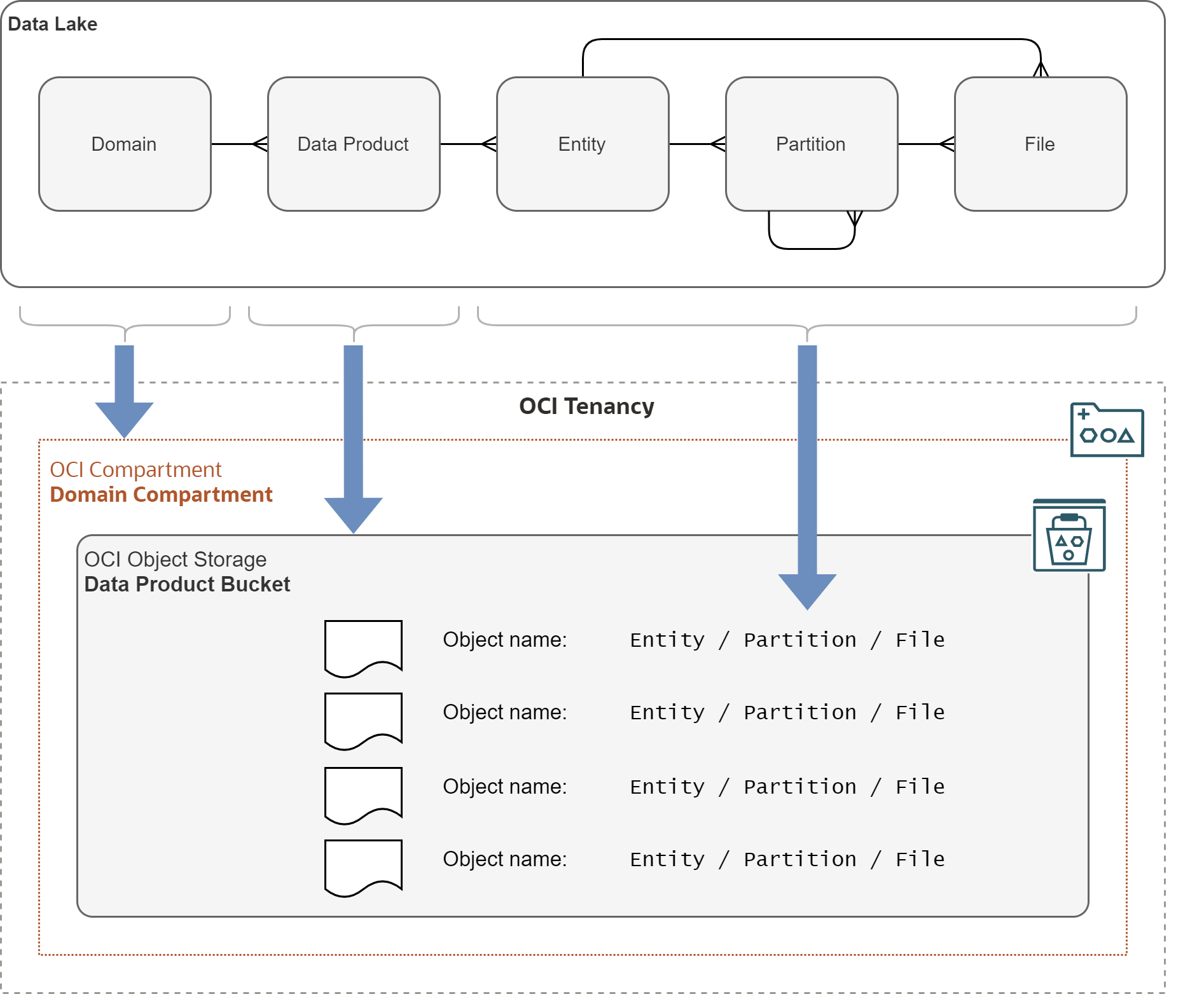
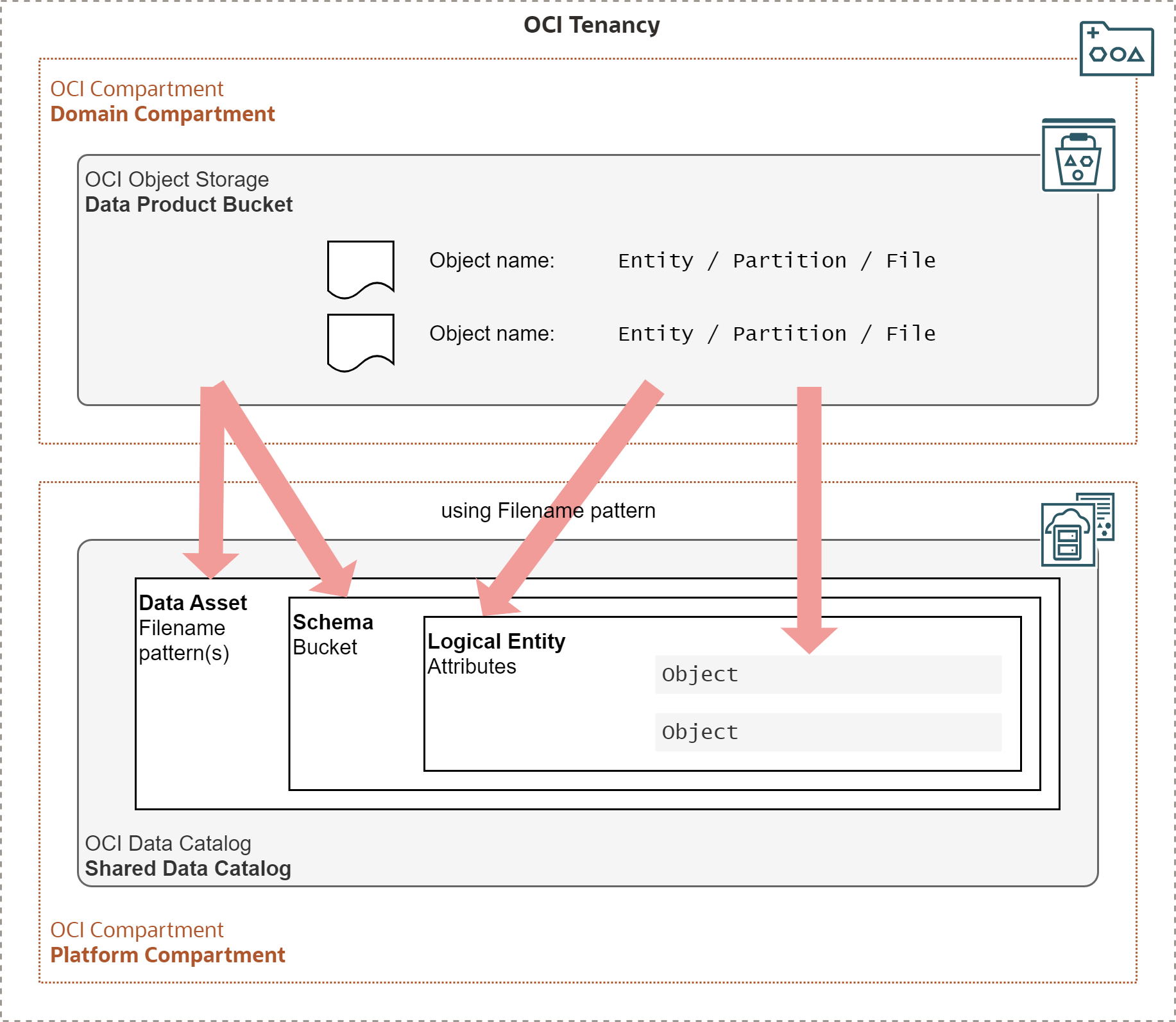
- Domain has all its Data Products within a single OCI Compartment.
- Data Product stores all its entities in a single OCI Object Storage Bucket.
- Bucket contains OCI Object Storage objects belonging to Entities and Partitions.
- Names of Entities, Partitions, and Files are encoded in object names.
Note that names of objects in OCI Object Storage often use / separator in a name to
emulate a folder structure. However, interpretation of such structure is up to the client.
As far as OCI Object Storage is concerned, names of objects in a bucket are flat and there
are no folders.
Object Name Patterns
So, how to encode Entity, Partition(s), and Files in an Object Name?
The following pattern provides an example for non partitioned entities:
<entity>/<filename>.<suffix>
<entity>- short name of the entity.<filename>- name of the file without suffix.<suffix>- suffix denoting format of the file (e.g.,parquet,json,csv, etc.).
And here is the pattern for partitioned entities:
<entity>/<partkey1>=<value1>/<partkey2>=<value2>/<partkeyN>=<valueN>/<filename>.<suffix>
<entity>- short name of the entity.<partkey1,2,..N>- name of the Nth partition key.<value1,2,..N>- value of the Nth partition key.<filename>- name of the file without suffix.<suffix>- suffix denoting format of the file (e.g.,parquet,json,csv, etc.).
As you can see, I recommend using the Hive convention for partition names. There are several other options, but I prefer Hive as it is self explanatory and supported by tools working with the Data Lake.
Regarding file name, I recommend it follows the following guidelines:
- File name is unique, ideally across the whole Data Lake.
- File name contains name or abbreviation of the entity.
- File name contains date and time (timestamp) of when it was created.
- File name (and content) is immutable - once created, it does not change.
Of course, you might not be able to ensure file names follow these guidelines all the time, as some frameworks let you specify object name prefix, but file names are generated automatically, using a framework specific pattern.
Object Name Examples
Applying the above patterns to our use case will produce these Object Names:
Subscription data product (dl-subscription-data-bucket)
customer/year=<year>/month=<month>/day=<day>/customer-<timestamp>-<sequence>.parquet
service/year=<year>/month=<month>/day=<day>/service-<timestamp>-<sequence>.parquet
customer-service/year=<year>/month=<month>/day=<day>/customer-service-<timestamp>-<sequence>.parquet
- Subscription data product is provided as daily snapshot of customer and services data.
- Subscription data is partitioned by year, month, and day.
Usage data product (dl-usage-data-bucket)
usage-data/year=<year>/month=<month>/day=<day>/usage-data-<timestamp>-<sequence>.parquet
usage-voice/year=<year>/month=<month>/day=<day>/usage-voice-<timestamp>-<sequence>.parquet
usage-sms/year=<year>/month=<month>/day=<day>/usage-sms-<timestamp>-<sequence>.parquet
- Usage data product represents detailed usage events.
- Usage data is partitioned by year, month, and day based on event timestamp.
Billing data product (dl-billing-data-bucket)
bill/year=<year>/billingperiod=<billingperiod>/bill-<timestamp>-<sequence>.parquet
usage-rated/year=<year>/billingperiod=<billingperiod>/usage-rated-<timestamp>-<sequence>.parquet
subscription-fee/year=<year>/billingperiod=<billingperiod>/subscription-fee-<timestamp>-<sequence>.parquet
- Billing data product is produced with frequency of billing periods.
- Billing data is partitioned by year and billing period.
Revenue Differences data product (dl-revassurance-data-bucket)
revenue-diff/year=<year>/month=<month>/revenue-diff-<timestamp>-<sequence>.parquet
- Revenue Differences are calculated for the whole calendar month.
- Revenue Differences are partitioned by year and month.
Mapping of Data Lake Entities to Cloud Tools
This section describes how you can map and work Data Lake entities in various OCI tools.
To demonstrate this, I use small subset of Usage data from bucket
dl-billing-data-bucket.
OCI Command Line Interface (CLI)
With OCI CLI, we can retrieve objects belonging to an entity using the prefix parameter.
We can retrieve all objects belonging to the entity, or only objects in a particular
partition.
The command below lists all objects belonging data product to Usage Data entity for day 2022/12/14:
$ oci os object list -bn dl-usage-data-bucket --prefix usage-voice/year=2022/month=12/day=14
{
"data": [
{
"archival-state": null,
"etag": "<etag>",
"md5": "rvseB7GvyLickxgCMbFj+w==",
"name": "usage-voice/year=2022/month=12/day=14/usage-voice20221214-000000.parquet",
"size": 441557,
"storage-tier": "Standard",
"time-created": "2023-02-19T11:12:41.749000+00:00",
"time-modified": "2023-02-19T11:12:41.749000+00:00"
},
{
"archival-state": null,
"etag": "<etag>",
"md5": "7w7tkrm1n7gp58MmxozLzg==",
"name": "usage-voice/year=2022/month=12/day=14/usage-voice20221214-000001.parquet",
"size": 441017,
"storage-tier": "Standard",
"time-created": "2023-02-19T11:12:42.303000+00:00",
"time-modified": "2023-02-19T11:12:42.303000+00:00"
},
...
],
"prefixes": []
}
OCI Console
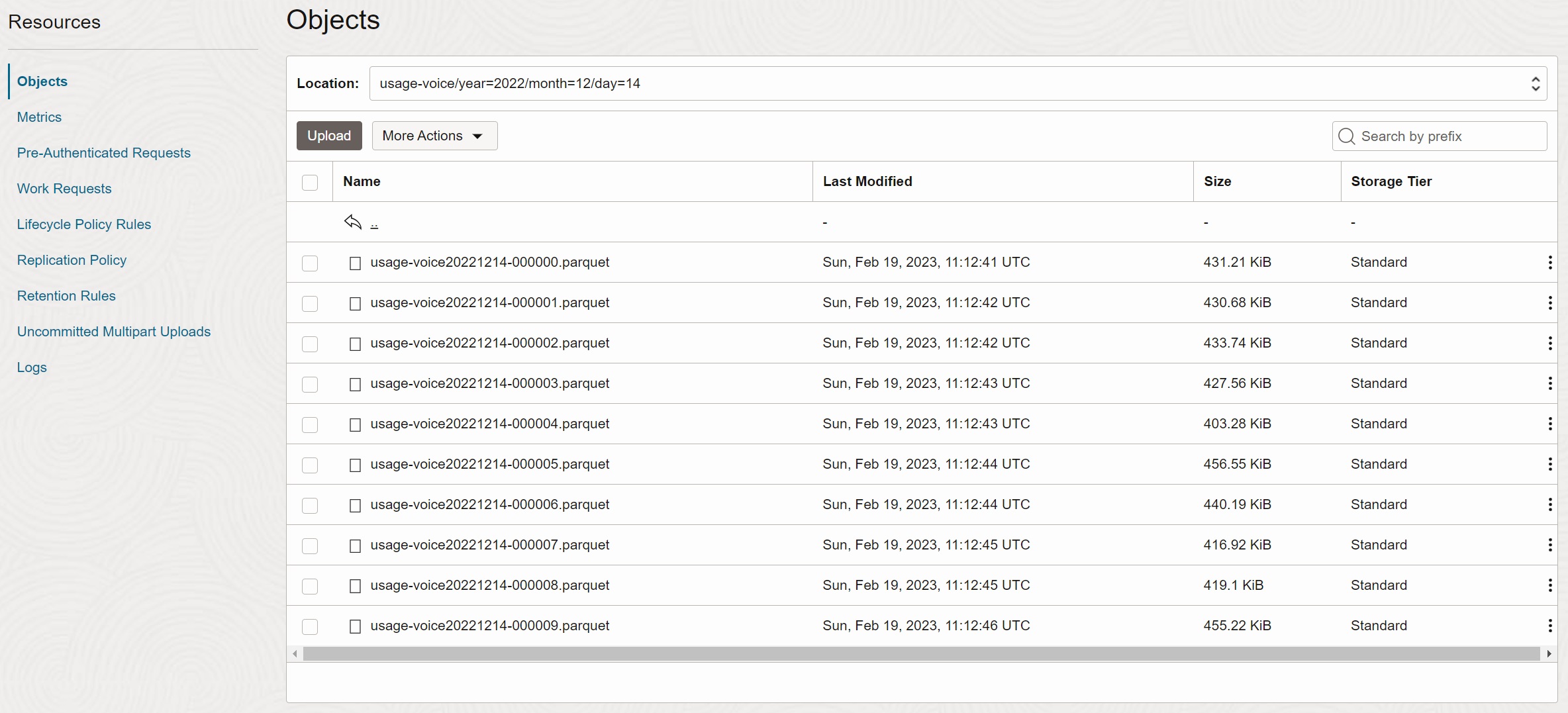
OCI Console shows objects in a bucket in a folder-like, hierarchical structure, using /
as a separator. Note there are no actual folders in Object Storage; the hierarchical view
is just a visualization applied by OCI Console.
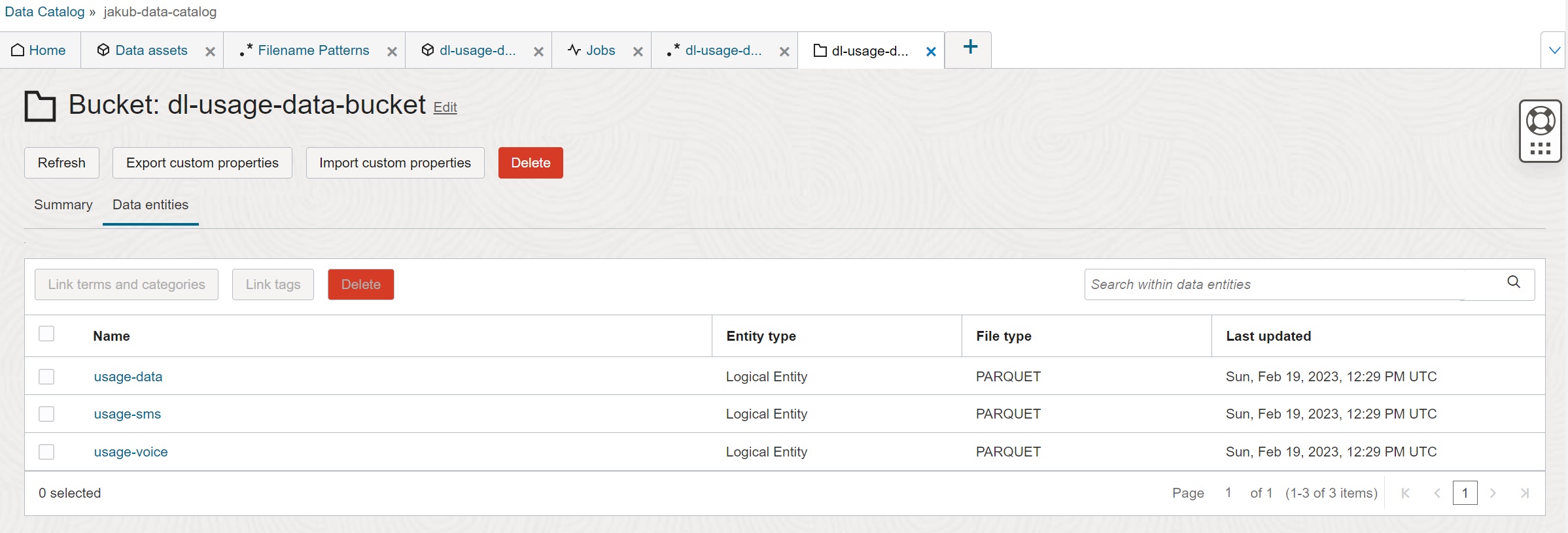
On the top level, you can see the list of entities available in the bucket:
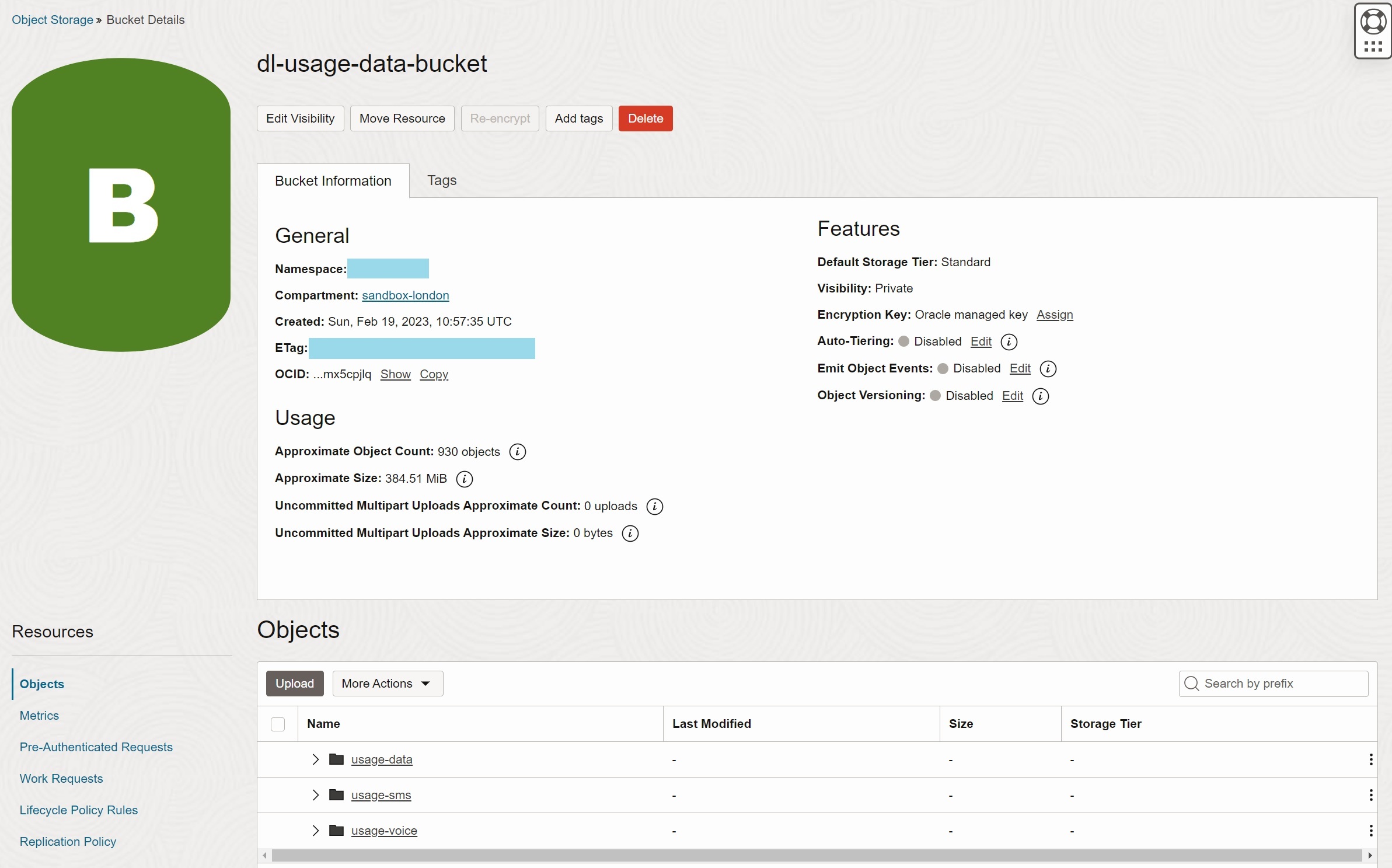
You can drill down from entity to partitions by clicking on the entity and partition names. On the most detail level you get the list of objects in a specific partition. Note that when you drill down, the prefix (Location) is updated.
OCI Data Catalog
In OCI Data Catalog, OCI Object Storage buckets are usually mapped to data assets and schemas, and Data Lake entities to logical entities in OCI Data Catalog, as demonstrated on the picture below. Furthermore OCI Data Catalog needs to understand the partitioning scheme to identify partition keys. And finally, files (objects) are mapped to logical entities.
Mapping of data assets to objects is performed in the following steps:
- Create Filename Pattern
- Create Data Asset
- Harvest Data Asset
- Periodically run incremental Harvesting
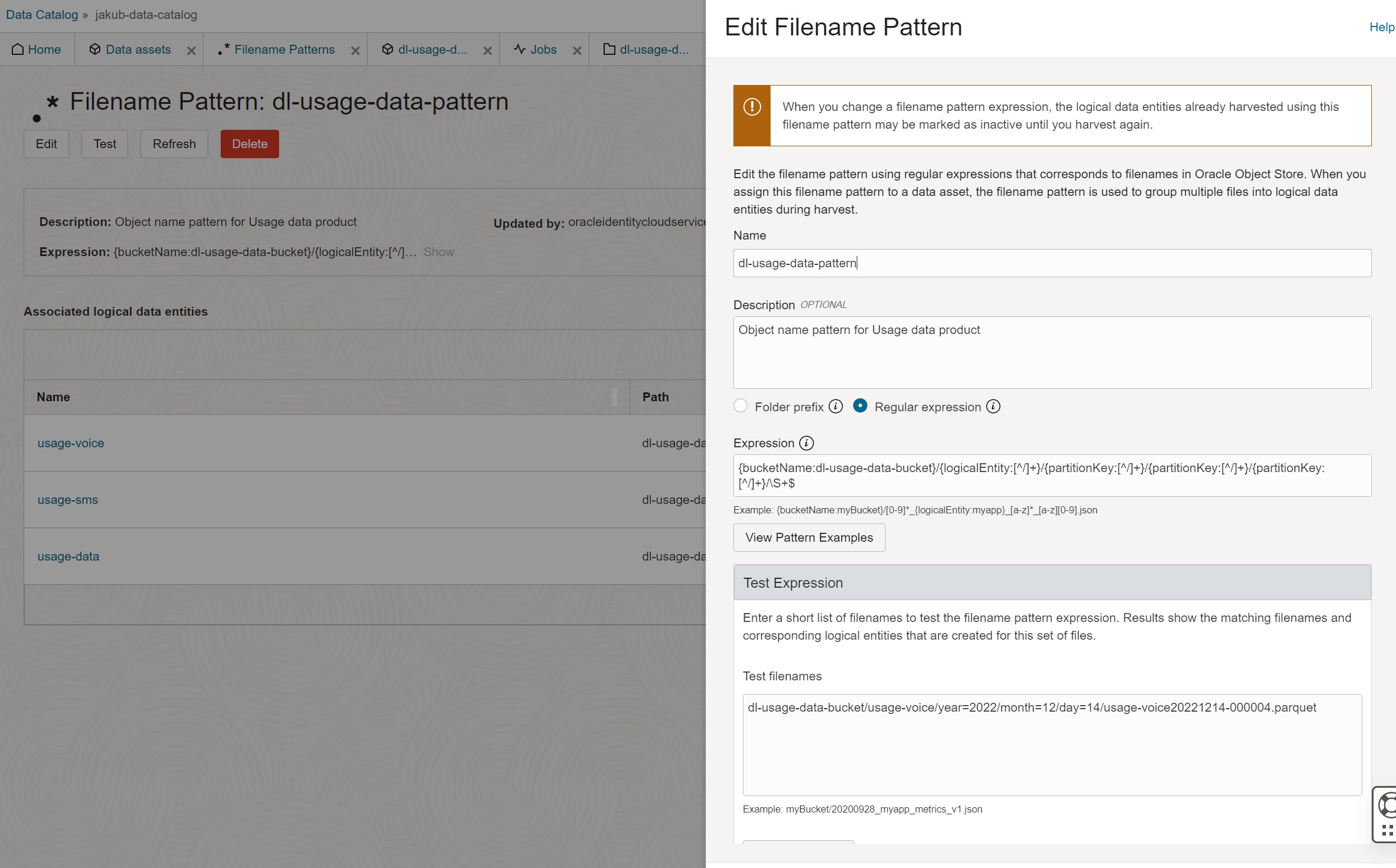
Filename Pattern
In this step you define the bucket name and regular expression that is used to derive name of entities and partitions. For our use case, the pattern looks as follows:
{bucketName:dl-usage-data-bucket}/{logicalEntity:[^/]+}/{partitionKey:[^/]+}/{partitionKey:[^/]+}/{partitionKey:[^/]+}/\S+$
{bucketName:dl-usage-data-bucket}- the first part of the expression specifies name of the bucket.{logicalEntity:[^/]+}- this part of the expression defines entity name{partitionKey:[^/]+}- this part of the expression defines partition key(s).\S+$- the rest of the expression is the object name
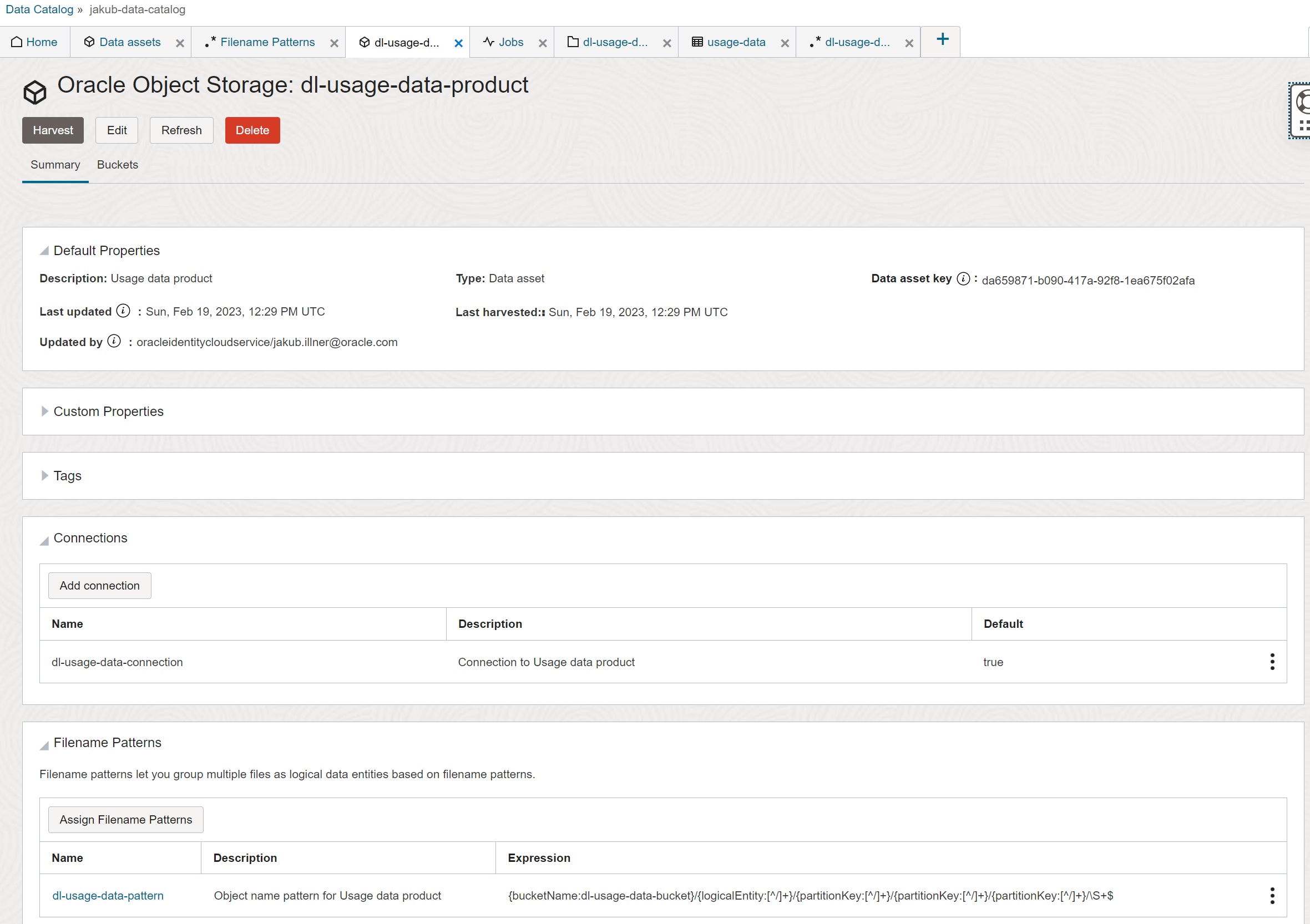
Data Asset
In this step you name the data asset, specify its type as OCI Object Storage, create connection to data asset and associate it with Filename Pattern. When creating the connection, I recommend using resource principal authentication, as described in the previous post.
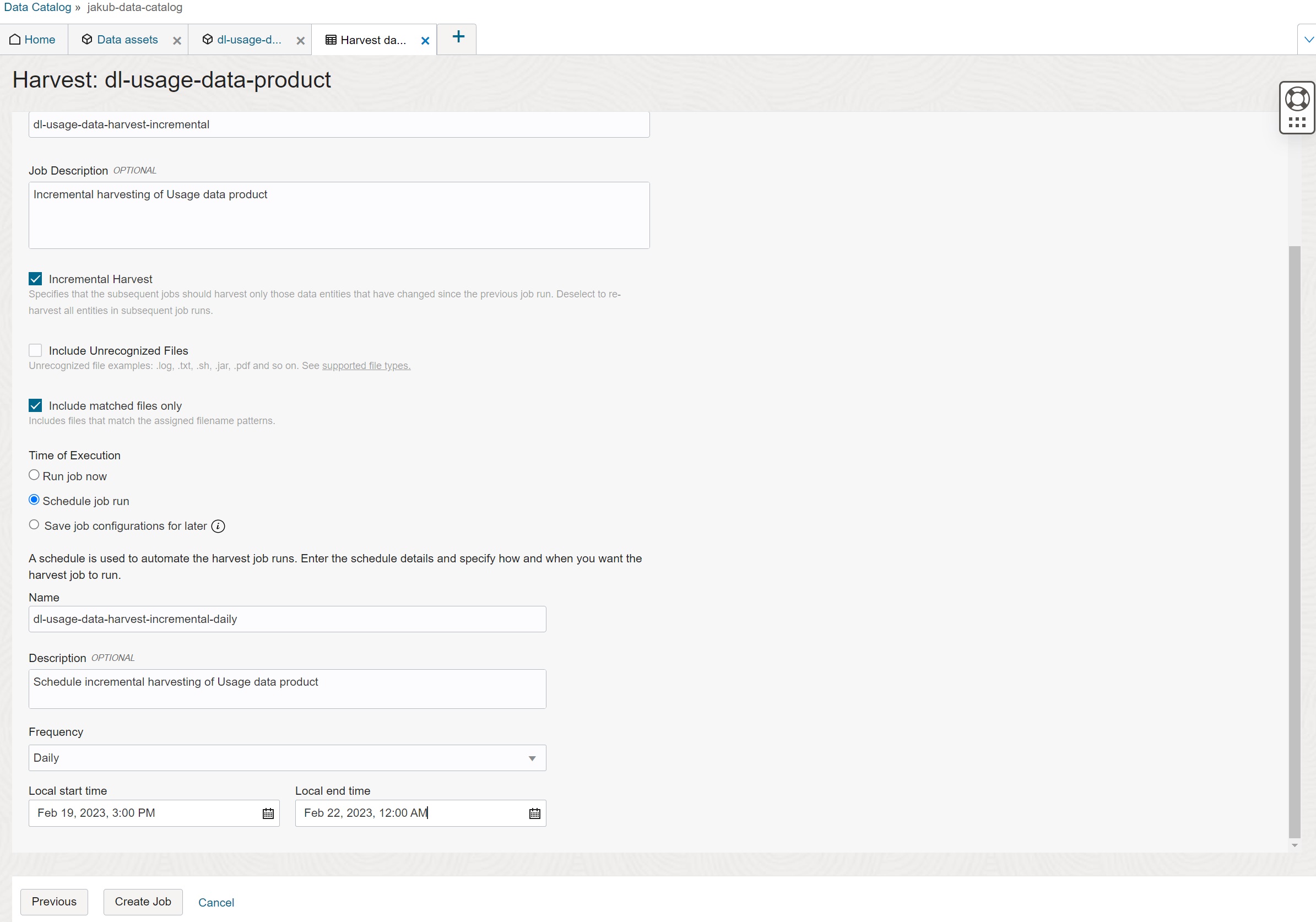
Data Harvesting Job
In this step you create a Job that performs initial harvesting of data set. The harvesting job applies the pattern to objects, it discovers entities, entities schema, partition keys, and it associates entities with objects.
Incremental Harvesting
In the last step you schedule periodic, incremental harvesting of data asset with the period of your choice. Regular re-harvesting is important to discover new entities and files added to Data Lake since the last harvesting.
Autonomous Data Warehouse
With Autonomous Data Warehouse, OCI Object Storage buckets are usually mapped to database schemas and Data Lake entities to external tables, as demonstrated on the picture below. For partitioned entities, it is further necessary to map table partitions. Once created, external tables may be queried via SQL like any other tables.
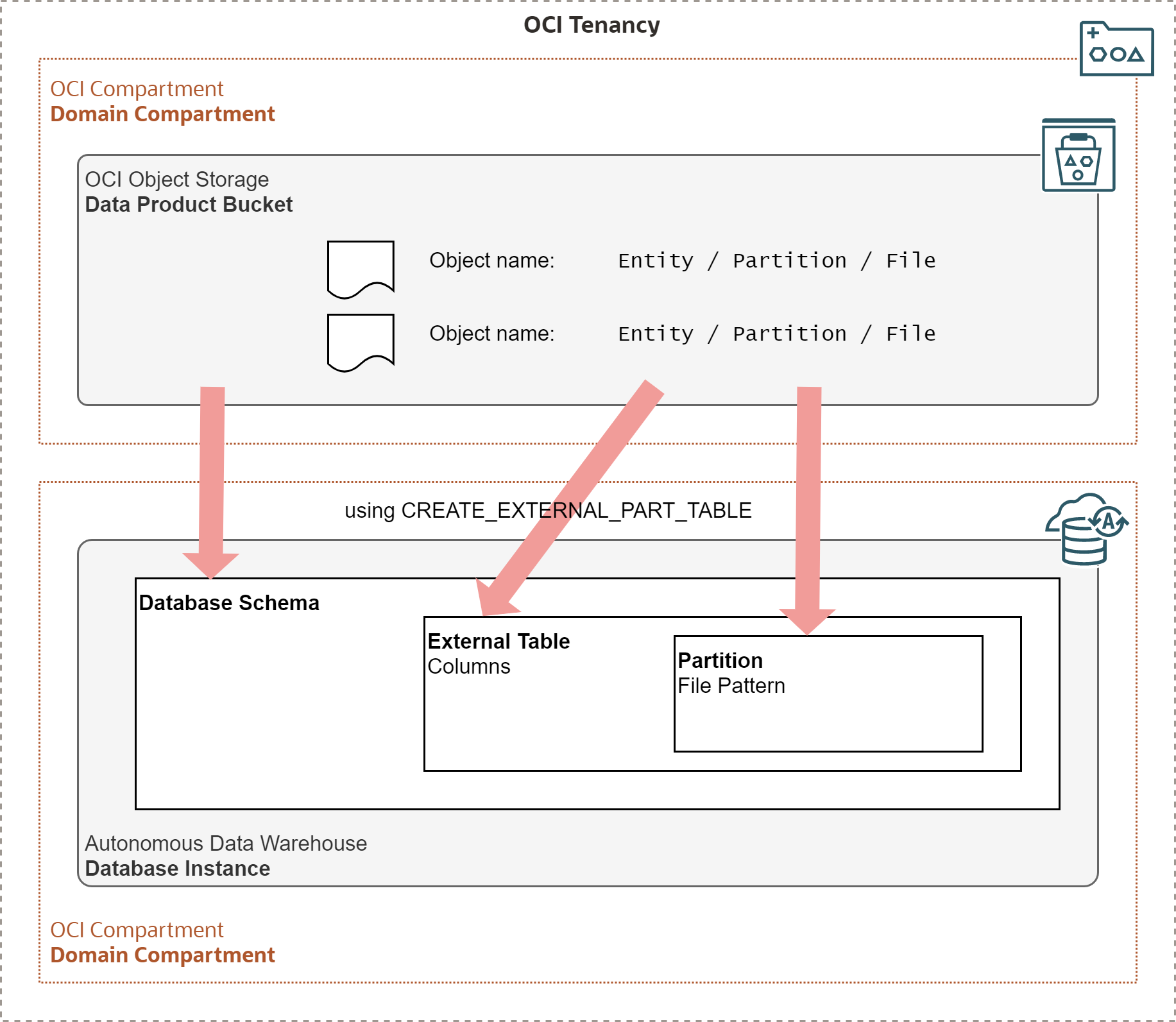
The mapping process consists of the following steps:
- Create Credential
- Create External Table
- Periodically sync External Table
Credential
Credential is an object in Autonomous Database which specifies how the database is authenticated for OCI operations. Similar to OCI Data Catalog, Autonomous Data Warehouse may be authenticated via resource principal. The example below shows how default user ADMIN is enabled for the resource principal authentication.
SQL> begin
2 dbms_cloud_admin.enable_resource_principal();
3 end;
4* /
PL/SQL procedure successfully completed.
SQL> select owner, credential_name
2 from dba_credentials
3 where credential_name = 'OCI$RESOURCE_PRINCIPAL'
4 and owner = 'ADMIN'
5* /
OWNER CREDENTIAL_NAME
________ __________________________
ADMIN OCI$RESOURCE_PRINCIPAL
SQL>
External Table
External partitioned tables are created with DBMS_CLOUD.CREATE_EXTERNAL_PART_TABLE
procedure. Note how the FILE_URI_LIST parameter defines the namespace, bucket name,
and file pattern.
SQL> begin
2 dbms_cloud.create_external_part_table(
3 table_name => 'USAGE_DATA',
4 credential_name => 'OCI$RESOURCE_PRINCIPAL',
5 file_uri_list => 'https://objectstorage.uk-london-1.oraclecloud.com/n/<namespace>/b/dl-usage-data-bucket/o/usage-data/*usage-data*.parquet',
6 format => json_object(
7 'type' value 'parquet', 'schema' value 'first',
8 'partition_columns' value json_array(
9 json_object('name' value 'year', 'type' value 'number'),
10 json_object('name' value 'month', 'type' value 'number'),
11 json_object('name' value 'day', 'type' value 'number')
12 )
13 )
14 );
15 end;
16* /
PL/SQL procedure successfully completed.
Below see the DDL command for the USAGE_DATA table created by the above procedure:
SQL> select dbms_metadata.get_ddl('TABLE','USAGE_DATA') from dual;
DBMS_METADATA.GET_DDL('TABLE','USAGE_DATA')
_____________________________________________
CREATE TABLE "ADMIN"."USAGE_DATA"
( "YEAR" NUMBER,
"MONTH" NUMBER,
"DAY" NUMBER,
"EVENT_ID" VARCHAR2(4000) COLLATE "USING_NLS_COMP",
"EVENT_START_TIMESTAMP" TIMESTAMP (6),
"EVENT_END_TIMESTAMP" TIMESTAMP (6),
"EVENT_TYPE" VARCHAR2(4000) COLLATE "USING_NLS_COMP",
...
) DEFAULT COLLATION "USING_NLS_COMP"
ORGANIZATION EXTERNAL
( TYPE ORACLE_BIGDATA
DEFAULT DIRECTORY "DATA_PUMP_DIR"
ACCESS PARAMETERS
( com.oracle.bigdata.fileformat=parquet
com.oracle.bigdata.filename.columns=["year","month","day"]
com.oracle.bigdata.file_uri_list="https://objectstorage.uk-london-1.oraclecloud.com/n/<namespace>/b/dl-usage-data-bucket/o/usage-data/*usage-data*.parquet"
com.oracle.bigdata.credential.schema="ADMIN"
com.oracle.bigdata.credential.name="OCI$RESOURCE_PRINCIPAL"
com.oracle.bigdata.trimspaces=notrim
)
)
REJECT LIMIT 0
PARTITION BY LIST ("YEAR","MONTH","DAY")
(PARTITION "P1" VALUES (( 2022, 12, 01 ))
LOCATION
( 'https://objectstorage.uk-london-1.oraclecloud.com/n/frqap2zhtzbe/b/dl-usage-data-bucket/o/usage-data/year=2022/month=12/day=01/*usage-data*.parquet'
),
PARTITION "P2" VALUES (( 2022, 12, 02 ))
LOCATION
( 'https://objectstorage.uk-london-1.oraclecloud.com/n/frqap2zhtzbe/b/dl-usage-data-bucket/o/usage-data/year=2022/month=12/day=02/*usage-data*.parquet'
),
...
PARTITION "P31" VALUES (( 2022, 12, 31 ))
LOCATION
( 'https://objectstorage.uk-london-1.oraclecloud.com/n/frqap2zhtzbe/b/dl-usage-data-bucket/o/usage-data/year=2022/month=12/day=31/*usage-data*.parquet'
))
PARALLEL
As you can see, there is no need to specify table columns and data types - this information is automatically extracted from the Parquet schema. Parquet byte arrays (strings) are stored as VARCHAR2(4000). Parquet logical types for date and timestamp are mapped to DATE and TIMESTAMP respectively.
It is also not necessary to define partitions. Partitions are automatically derived from the object names, as Autonomous Database understands Hive conventions for partition names. Note that the partitioning strategy is LIST partitioning by all the partition keys.
The only part of the external table definition that must be defined manually is data type of partition keys. Partition keys and their values are stored in object name only and it is therefore necessary to specify the data type.
Synchronization of External Tables
Partitions and schema of external tables may be synced with the OCI Object Storage by
running the procedure DBMS_CLOUD.SYNC_EXTERNAL_PART_TABLE. This procedure should be
periodically executed to ensure the external table definition is aligned with the data
available in the bucket.
SQL> begin
2 dbms_cloud.sync_external_part_table(
3 table_name => 'USAGE_DATA'
4 );
5 end;
6* /
PL/SQL procedure successfully completed.
Summary
In this post I show how logical structure of Data Lake domains, data products, and entities may be easily mapped to OCI Object Storage buckets and objects. I show simple patterns for naming objects belonging to partitioned and non-partitioned entities. The partitioning scheme uses Hive convention for naming files.
With OCI CLI/SDK/API you can use prefix to list, bulk download, or bulk delete all
objects for the whole entity or selected partition of the entity. In OCI Console, you can
also use prefix to list objects for a single partition; or you can use the drill-down
capability to explore the entities, partitions, and objects.
In OCI Data Catalog, Data Products are mapped to data assets, and Entities to logical entities in the catalog. Filename patterns are regular expressions that specify how object names are parsed and mapped to entity names and partition keys. Harvesting process retrieves information from objects in the Data Product’s bucket and it uses pattern to create assets, entities, and attributes. Harvesting process may be scheduled to automatically refresh data assets from the current content of the Data Lake.
In Autonomous Data Warehouse, Data Products are mapped to schemas, and Entities to external tables. With Hive partitioning scheme, partitions are automatically detected and created from the available data. For data formats that include schema (such as Parquet) columns of the external table are automatically defined with the correct data types. External tables may be regularly synced with Object Storage to refresh partitions (and optionally schema) from the current content of the Data Lake.
And finally, there are several related, important topics which I did not manage to fit into this post. I will return to them in some of the following posts, so stay tuned!
- How to create external tables in Autonomous Database from OCI Data Catalog.
- How OCI Data Integration and OCI Data Flow services support Data Lake.
- Using OCI Data Catalog Metastore with Data Lake.
- Support for Delta Lake on OCI Object Storage.
Resources
- OCI Object Storage CLI commands: Object Storage CLI Commands.
- Overview of OCI Data Catalog: Data Catalog Overview.
- Autonomous Database DBMS_CLOUD procedures: DBMS_CLOUD Subprograms and REST APIs.
- Blog post on working with Parquet files in Oracle Database from Alexey Filanovskiy: Working with Parquet files with Oracle Database.
- Blog post on working with Object Storage from Autonomous Database from Alexey Filanovskiy: Working with Object Store data from Autonomous Database now became easier.