Transforming JSON documents with OCI Data Integration

Introduction
JSON is widely used for communication between web based clients and backends. JSON is also frequently used as preferred format in messaging and streaming platforms such as Apache Kafka. It is human readable, self-described, easy to understand, and supported by all languages and development and integration tools.
Although JSON is ubiquitous format in the application development and integration world, it is less than ideal for high performance, high volume data analytics. The main reason is that anytime you run analytics against JSON data, the JSON documents have to be parsed, structures unnested and/or flattened, and data transformed to required types. And, being a descriptive, text format, JSON consumes much more storage than alternative formats.
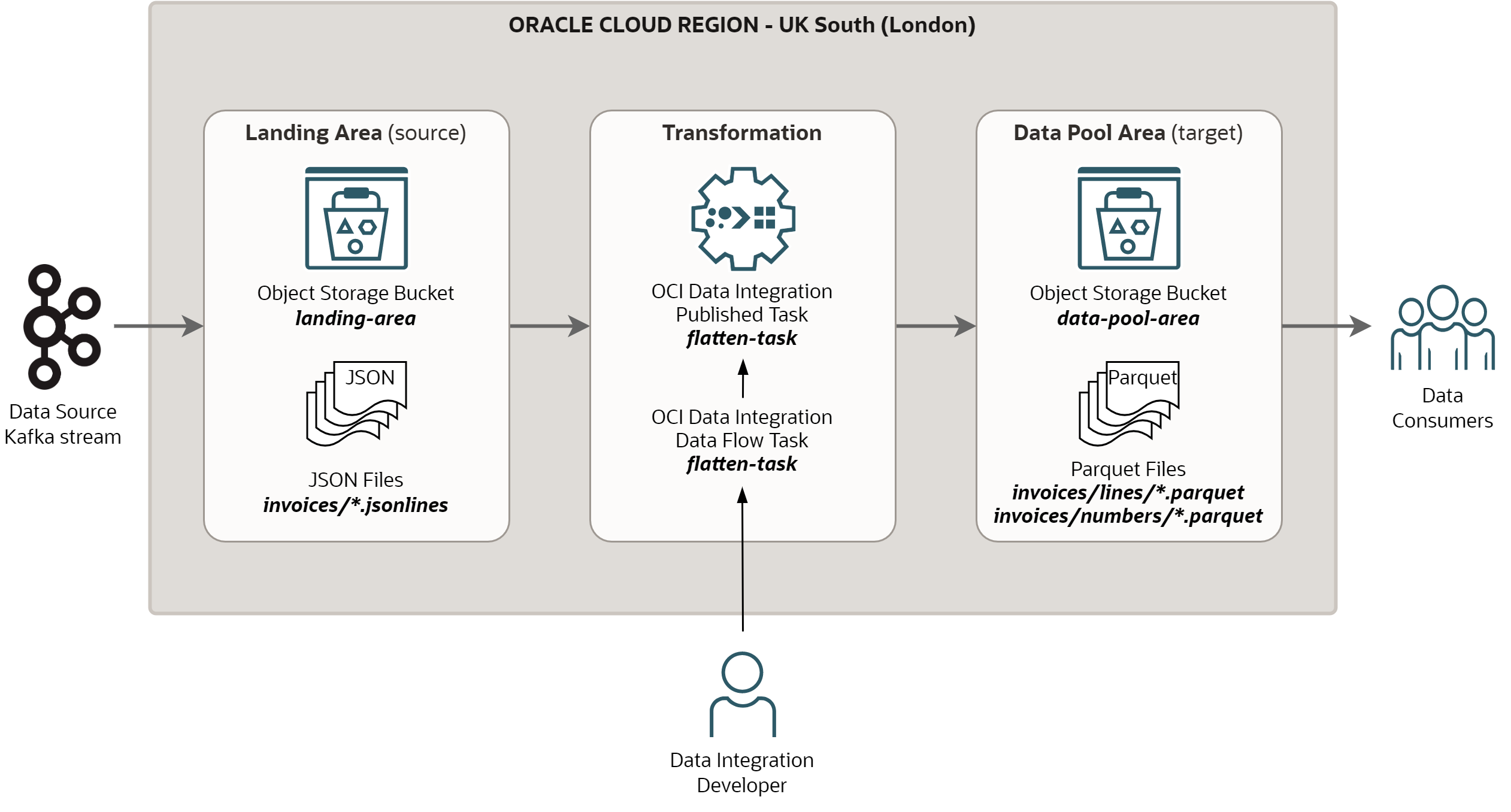
To resolve this issue, many Data Lakes adopt a layering strategy. JSON data is ingested into a Landing Area where it is stored in the original format. From the Landing Area, JSON data is transformed into formats suitable for analytics, such as Parquet or ORC, and stored in a Data Pool Area. The transformations typically include unnesting of JSON records, flattening of JSON arrays, and transforming strings to target data types such as dates or timestamps.
OCI Data Integration is a managed service that can be used to develop and schedule ETL tasks such as ingesting data from sources; cleansing, transforming, and reshaping that data; and loading data to target data assets. Recently, OCI Data Integration added Flatten operator to its portfolio to simplify processing of JSON documents.
This post shows how you can use Oracle Cloud Infrastructure (OCI) Data Integration service to transform large and complex JSON documents to data format suitable for analytics.
Transformation Scenario
-
Source data lands in the Landing Area on OCI Object Storage, in the bucket
landing-area. The name of files in the Landing Area follows the patterninvoices/*.jsonlines. The files are in JSON Lines format, i.e., single file contains many JSON documents separated by newlines. -
Transformation is implemented in OCI Data Integration. There is a single Data Flow task
flatten-task, which reads file from Landing Area, applies required transformations, and writes results into the Data Pool Area. In our scenario, the Data Flow task processes one file in a time. -
The processed data are saved in the Data Pool Area on OCI Object Storage, in the bucket
data-pool-area. The trasformation produces two entities from JSON documents, one entity stored ininvoices/lines/*.jsonlinesfiles, the second stored in ininvoices/numbers/*.jsonlinesfiles. The output files are in Parquet format.
The scenario is depicted on the diagram below:
Source Data
The source data are invoices such as may be produced by Telco operators. A single JSON document contains all the information from an invoice:
invoice_details- JSON object with invoice level attributesinvoice_lines- JSON array with amounts invoiced for individual servicespayment_details- JSON object with payment attributesphone_numbers- JSON array with phone numbers under the same customer account. Note that for every phone number there is a nested array with break-down of services the phone number consumed.
Example of the JSON document with artificially generated data is below.
{
"invoice_details": {
"invoice_number": "518493667924",
"customer_number": "967587977",
"invoice_date": "2022-08-12",
"period_start_date": "2022-07-11",
"period_end_date": "2022-08-11"
},
"invoice_lines": [
{ "line_code": "Tariff", "line_amount": 5857.82 },
{ "line_code": "Data", "line_amount": 1381.02 },
{ "line_code": "Voice", "line_amount": 85.68 },
{ "line_code": "SMS", "line_amount": 1764.08 },
{ "line_code": "Other Fees", "line_amount": 1215.65 },
{ "line_code": "3rd Party Services", "line_amount": 1550.35 },
{ "line_code": "VAT Amount", "line_amount": 1973.77 },
{ "line_code": "Total Amount", "line_amount": 4570.85 }
],
"payment_details": {
"due_date": "2022-08-27",
"bank_account_number": "72XCCQ8I4GD36EP4OJ6XOIT69DUMVZVVW8ODMJS",
"bank_code": "Q8NVKDP0",
"payment_amount": 4556.84,
"payment_currency": "EUR"
},
"phone_numbers": [
{
"number_name": "Gfmrcr",
"country_code": "6",
"phone_number": "306688955",
"phone_consumption": [
{ "line_code": "Tariff", "line_amount": 1284.35 },
{ "line_code": "Data", "line_amount": 1770.69 },
{ "line_code": "Voice", "line_amount": 3684.39 },
{ "line_code": "SMS", "line_amount": 443.42 },
{ "line_code": "Other Fees", "line_amount": 1184.42 },
{ "line_code": "3rd Party Services", "line_amount": 288.61 },
{ "line_code": "VAT Amount", "line_amount": 1434.2 },
{ "line_code": "Total Amount", "line_amount": 3693.26 }
]
},
{
"number_name": "Oezmxswcx",
"country_code": "423",
"phone_number": "214026435",
"phone_consumption": [
{ "line_code": "Tariff", "line_amount": 7685.44 },
{ "line_code": "Data", "line_amount": 2019.0 },
{ "line_code": "Voice", "line_amount": 1530.31 },
{ "line_code": "SMS", "line_amount": 248.29 },
{ "line_code": "Other Fees", "line_amount": 1805.55 },
{ "line_code": "3rd Party Services", "line_amount": 5109.0 },
{ "line_code": "VAT Amount", "line_amount": 1167.16 },
{ "line_code": "Total Amount", "line_amount": 8141.92 }
]
}
]
}
Required Transformation
The transformation should produce two entities:
-
Invoice Lines entity, with attributes from
invoice_detailsandpayment_detailsobjects, and flattenedinvoice_linesarray. For the JSON document above, this data set consist of 8 rows (number of elements in the array). -
Phone Numbers entity, with attributes from
invoice_detailsandpayment_detailsobjects, and flattenedphone_numbersarray and flattenedphone_consumptionsub-array. For the JSON document above, this data set will consist of 16 rows (number of elements in the sub-array).
Mapping for Invoice Lines entity is as follows:
| Target Column | Data Type | Mapping from JSON |
|---|---|---|
| INVOICE_NUMBER | VARCHAR(40) | invoice_details.invoice_number |
| CUSTOMER_NUMBER | VARCHAR(40) | invoice_details.customer_number |
| INVOICE_DATE | DATE | invoice_details.invoice_date |
| INVOICE_PERIOD_START_DATE | DATE | invoice_details.period_start_date |
| INVOICE_PERIOD_END_DATE | DATE | invoice_details.period_end_date |
| PAYMENT_DUE_DATE | DATE | payment_details.due_date |
| PAYMENT_CURRENCY | VARCHAR(10) | payment_details.payment_currency |
| PAYMENT_AMOUNT | DECIMAL(12,2) | payment_details.payment_amount |
| INVOICE_LINE_CODE | VARCHAR2(80) | invoice_lines[].line_code |
| INVOICE_LINE_AMOUNT | DECIMAL(12,2) | invoice_lines[].line_amount |
And mapping for Phone Numbers entity is as follows:
| Target Column | Data Type | Mapping from JSON |
|---|---|---|
| INVOICE_NUMBER | VARCHAR(40) | invoice_details.invoice_number |
| CUSTOMER_NUMBER | VARCHAR(40) | invoice_details.customer_number |
| INVOICE_DATE | DATE | invoice_details.invoice_date |
| INVOICE_PERIOD_START_DATE | DATE | invoice_details.period_start_date |
| INVOICE_PERIOD_END_DATE | DATE | invoice_details.period_end_date |
| PAYMENT_DUE_DATE | DATE | payment_details.due_date |
| PAYMENT_CURRENCY | VARCHAR(10) | payment_details.payment_currency |
| PAYMENT_AMOUNT | DECIMAL(12,2) | payment_details.payment_amount |
| PHONE_NUMBER_NAME | VARCHAR(80) | phone_numbers[].number_name |
| PHONE_NUMBER_COUNTRY_CODE | VARCHAR(10) | phone_numbers[].country_code |
| PHONE_NUMBER | VARCHAR(40) | phone_numbers[].phone_number |
| PHONE_LINE_CODE | VARCHAR(40) | phone_numbers[].phone_consumption[].line_code |
| PHONE_LINE_AMOUNT | DECIMAL(12,2) | phone_numbers[].phone_consumption[].line_amount |
Transformation Walk-Through
Data Flow
The transformation is implemented as Data Flow flatten. It reads a single source but
produces two outputs. One output contains Invoice Lines (corresponding to the JSON node
invoice_lines), the other output contains Phone Numbers (corresponding to the JSON node
phone_numbers).
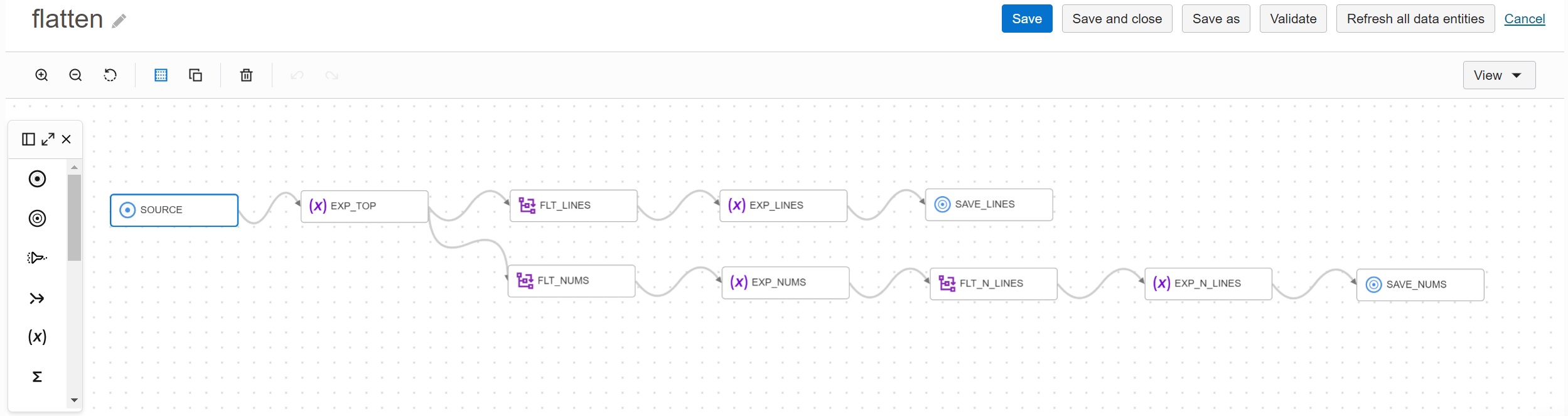
The first flow consists of these steps:
SOURCE- Data source is JSON file in Object Storage.EXP_TOP- Expression operator is required to extract attributes from top level JSON object.FLT_LINES- Flatten operator transforms JSON array from nodeinvoice_linesto rows.EXP_LINES- Expression is used to transform the columns to required data types.SAVE_LINES- Writes target asset as Parquet file in Object Storage.
The second flow is similar to the first one, but it needs two Flatten operators - one for
the node phone_numbers, the second for the nested node phone_consumption.
SOURCE- Data source is JSON file in Object Storage.EXP_TOP- Expression operator is required to extract attributes from top level JSON object.FLT_NUMS- Flatten operator transforms JSON array from nodephone_numbersto rows.EXP_NUMS- Expression is used to transform the columns to required data types.FLT_N_LINES- Flatten operator transforms JSON array from nodephone_consumptionto rows.EXP_N_LINES- Expression is used to transform the columns to required data types.SAVE_LINES- Writes target asset as Parquet file in Object Storage.
Parameters
The Data Flow is parameterized, so that it can be run with any JSON file that arrives in the Landing Area.
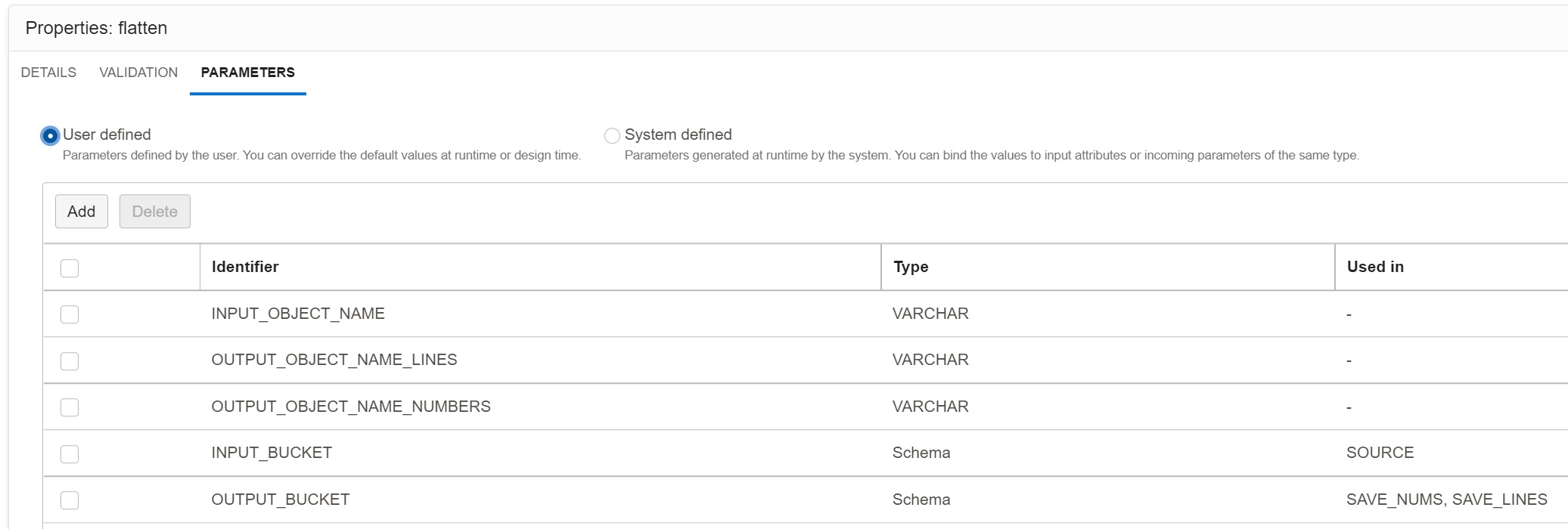
INPUT_BUCKET- Object Storage bucket containing the source file.INPUT_OBJECT_NAME- Name of the source JSON file (including the prefix).OUTPUT_BUCKET- Object Storage bucket where the target files will be written.OUTPUT_OBJECT_NAME_LINES- Name of the target file withinvoice_lines(including the prefix).OUTPUT_OBJECT_NAME_NUMBERS- Name of the target file withphone_numbers(including the prefix).
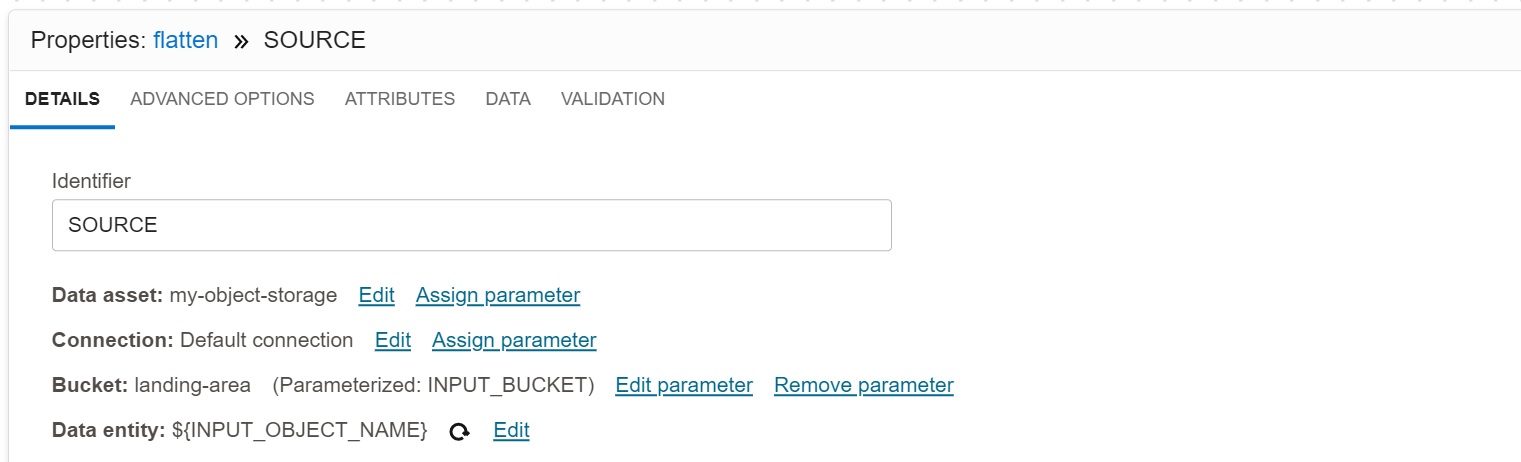
Data Source
The Source operator SOURCE maps Object Storage asset, using parameters for Bucket and
Data entity (i.e., object name). It also specifies the source type as JSON Lines, though
this is not visible on the picture.
Mapping of Attributes from JSON Objects
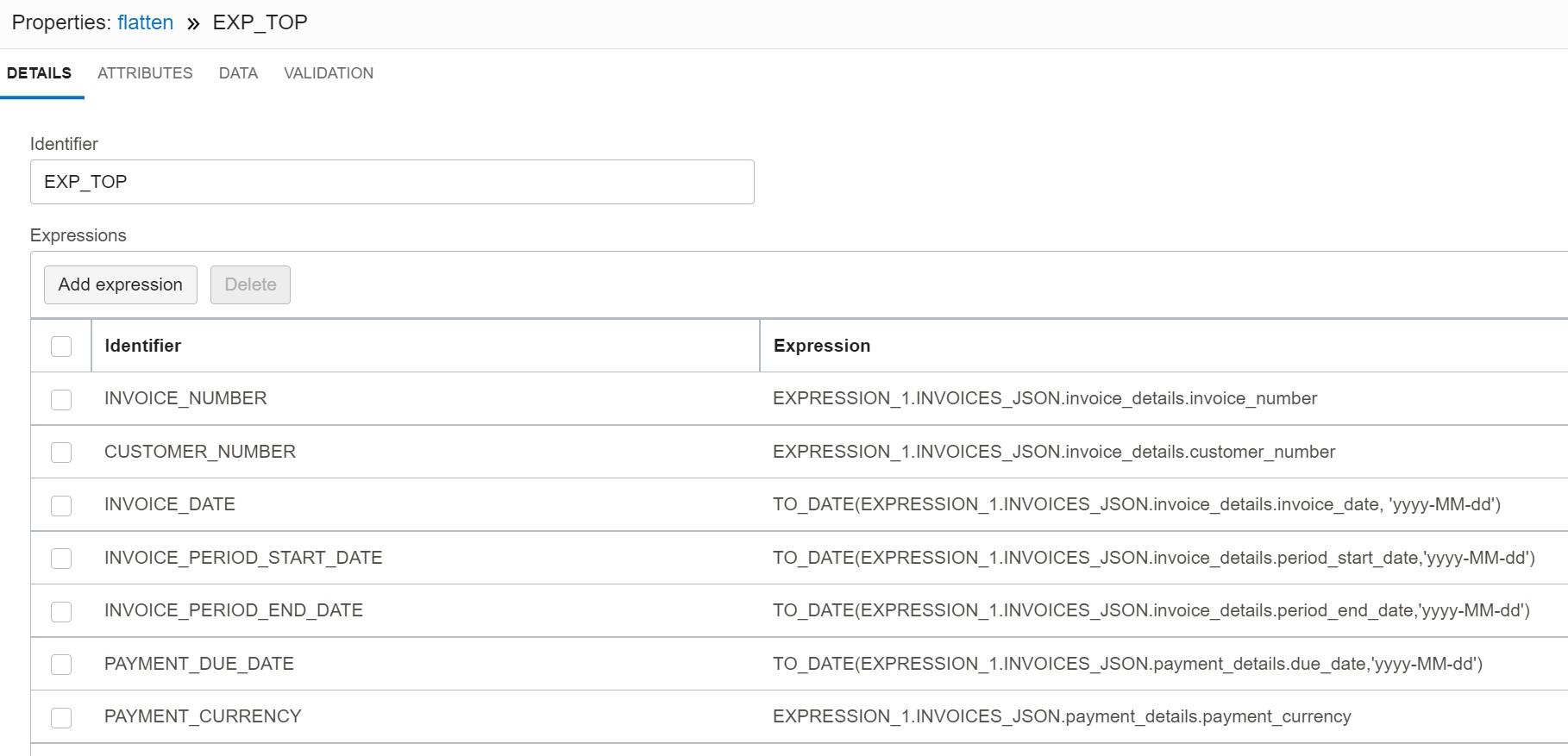
Top level attributes from JSON objects (not arrays) are selected with Expression operator
EXP_TOP. JSON attributes are mapped using a simple dot notation. Note we can select
attributes from multiple JSON objects (e.g., invoice_details and payment_details) in a
single operator. Attributes are also converted to required data types. This includes
specifying length of string atributes, precision of numerical attributes, and conversion
of date and timestamp attributes.
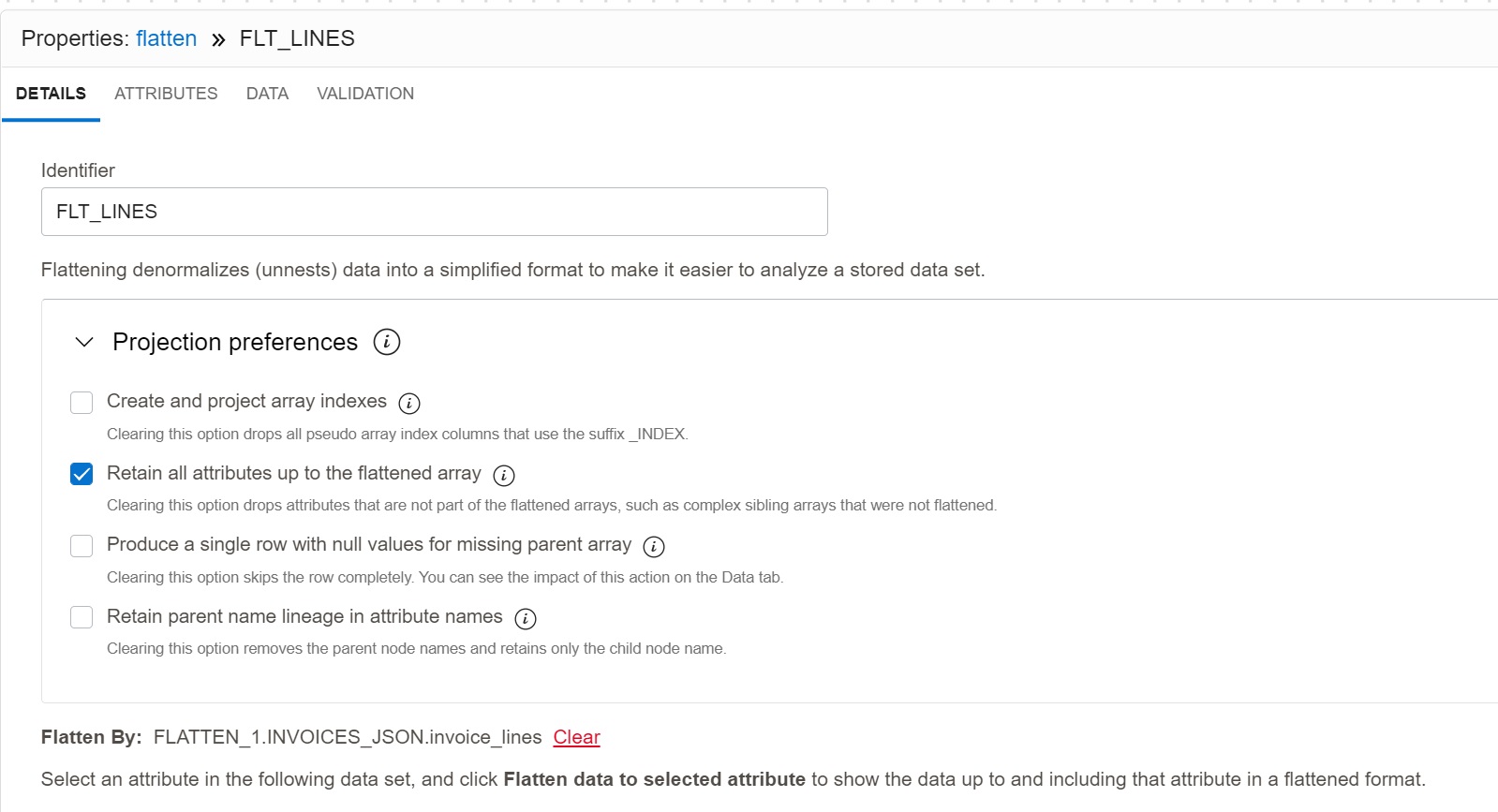
Flattening of JSON Arrays
JSON arrays have to transformed into rows using the Flatten operator FLT_LINES. In the
Flatten operator, it is necessary to specify the node from which the flattening happens
(in our case node invoice_lines), and the operator transforms the array for this node
into rows. The Flatten operator does not support mapping of data types for output
attributes; for this we need another Expression operator EXP_LINES.
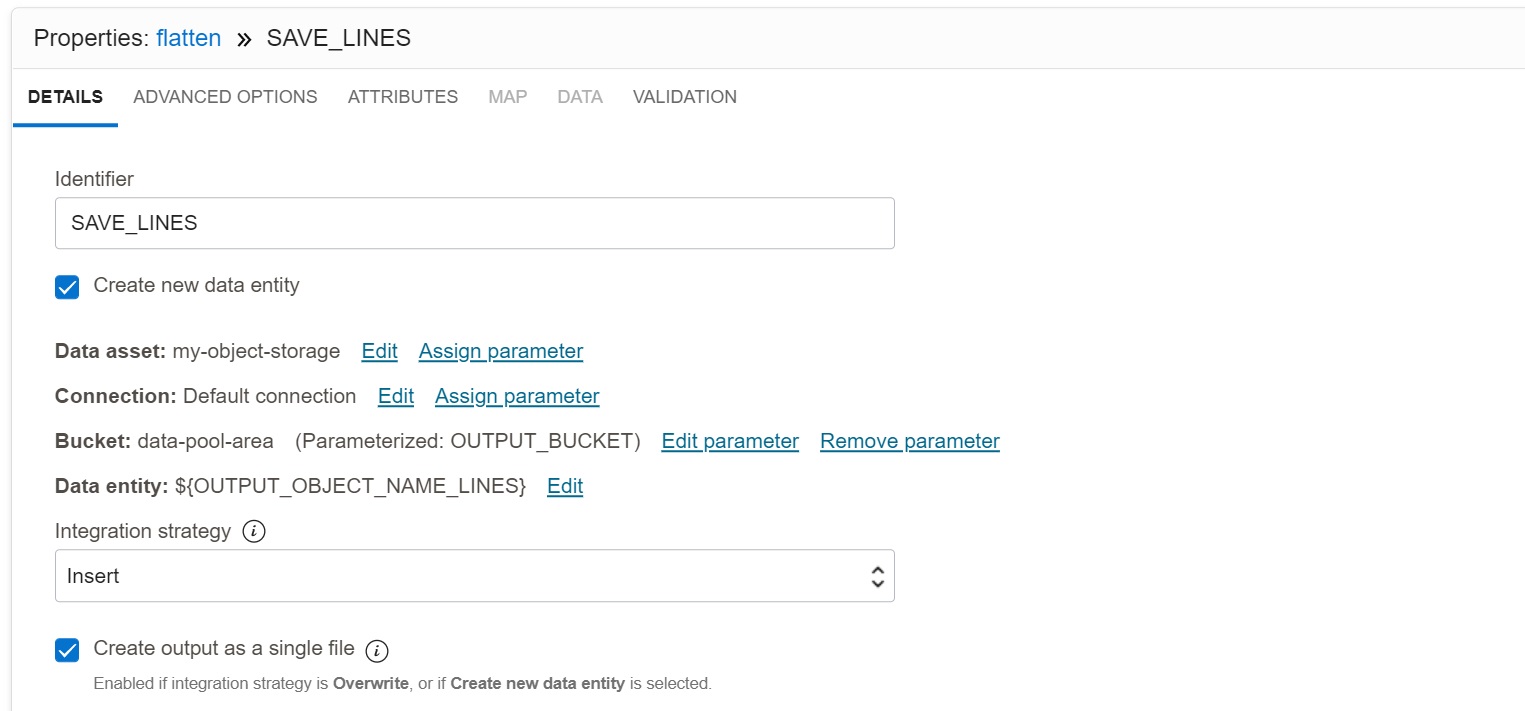
Data Target
The last step is writing the output file via Target operator SAVE_LINES. The target data
asset is Object Storage, with parameters specifying Bucket and Data entity. The target
format is Parquet with Snappy compression (not shown on the picture). I have also
specified that the output should be created as a single file. This is slower than creating
multiple files, but perfectly acceptable for my scenario.
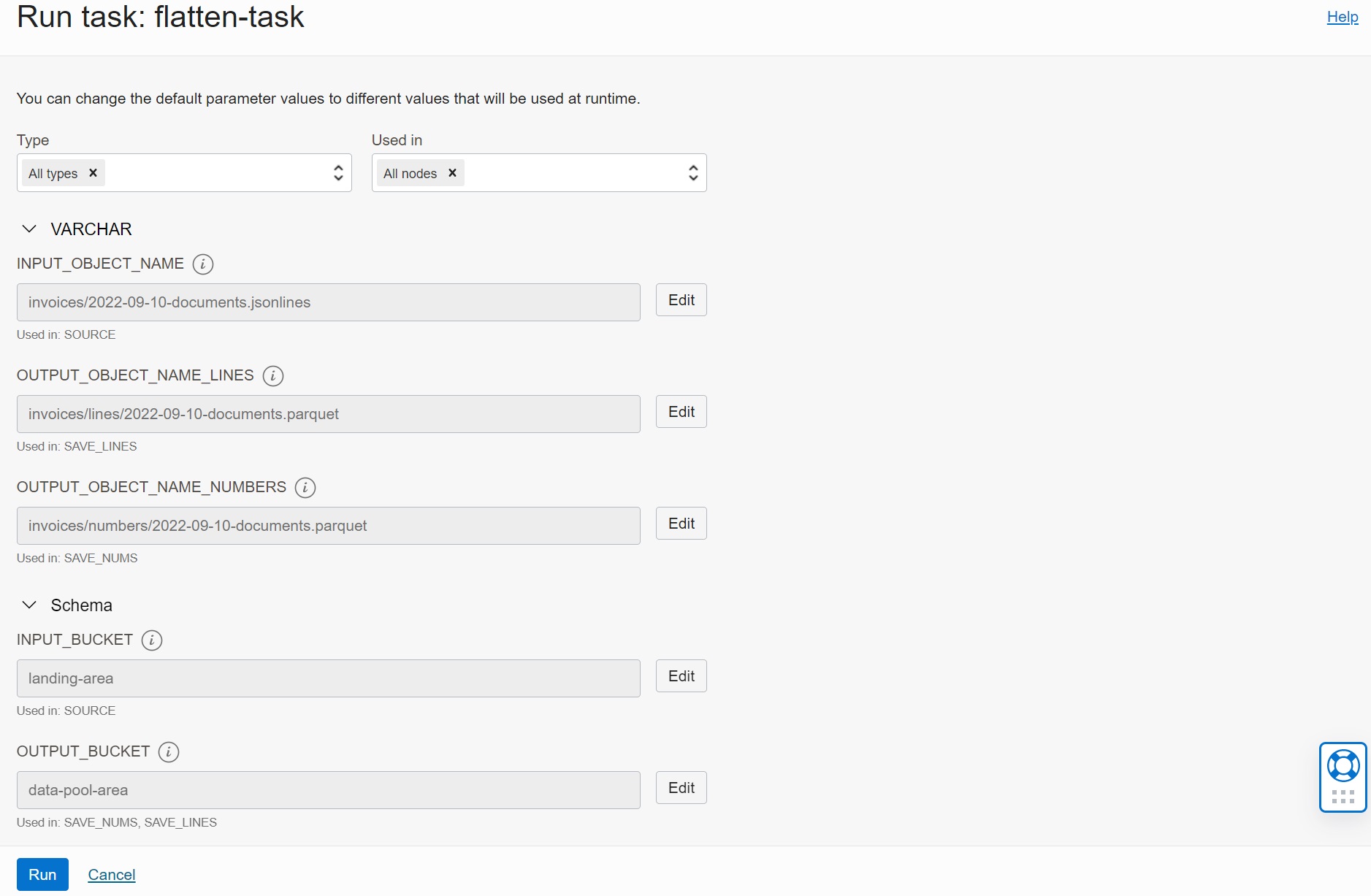
Running Transformation
Runtime Parameters
When running the transformation task flatten-task, we have an option to override the
default values of task parameters.
In our case, I specified both input and output file names. The input file
invoices/2022-09-10-documents.jsonlines consists of 100000 JSON documents, with the
total size of 377 MB (377278881 bytes, to be precise), with 3772 bytes per JSON document
on average.
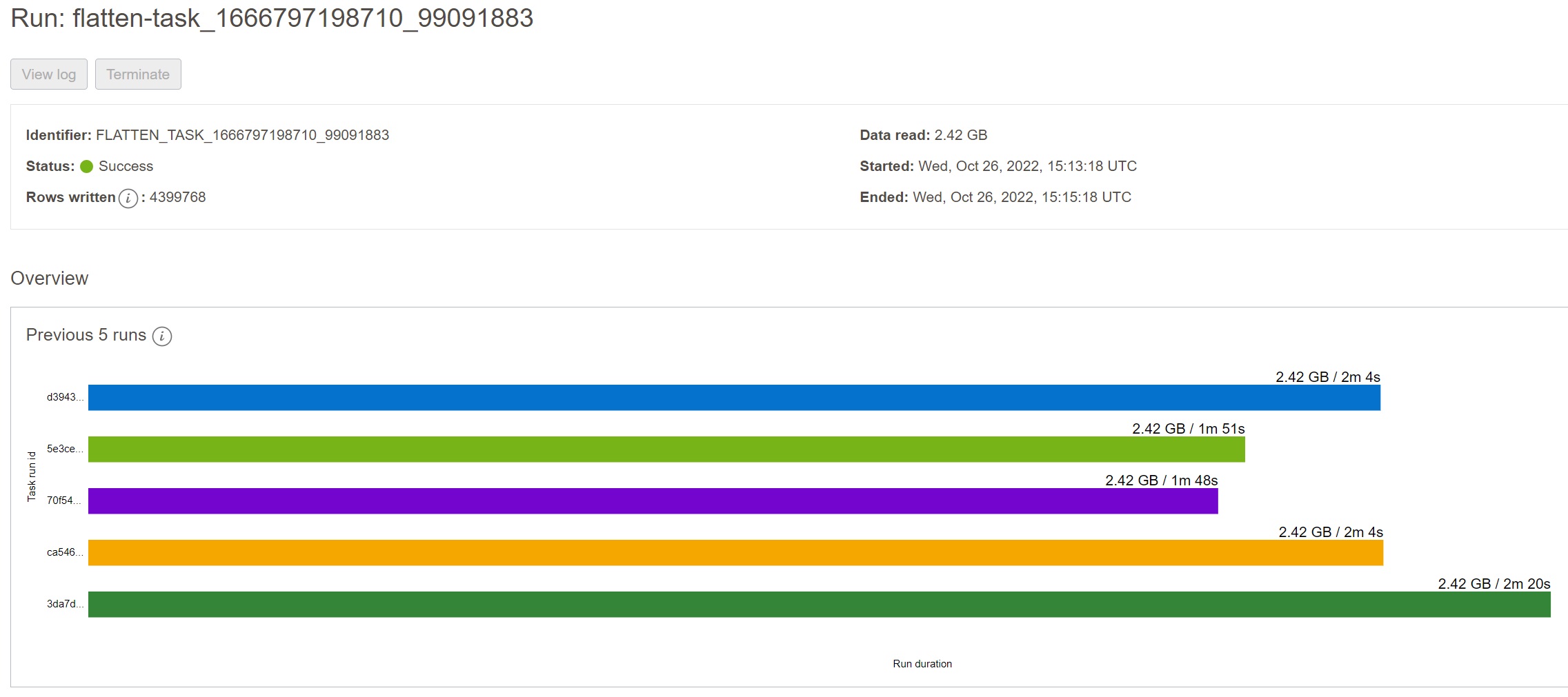
Runtime Results
And finally, when the transformation task is completed, we can check the results. As you can see, the task required about 2 minutes, writing 4399768 rows (splitted between the two targets) and processing 2.42 GB of data.
We can verify the structure of generated files for example by loading the files into Pandas dataframe.
>>> import pandas
>>> df = pandas.read_parquet('invoices/lines/2022-09-10-documents.parquet')
>>> df
INVOICE_NUMBER CUSTOMER_NUMBER INVOICE_DATE INVOICE_PERIOD_START_DATE ... PAYMENT_CURRENCY PAYMENT_AMOUNT INVOICE_LINE_CODE INVOICE_LINE_AMOUNT
0 448031334588 948010335 2022-09-10 2022-08-09 ... EUR 4414.06 Tariff 1974.54
1 448031334588 948010335 2022-09-10 2022-08-09 ... EUR 4414.06 Data 5203.04
2 448031334588 948010335 2022-09-10 2022-08-09 ... EUR 4414.06 Voice 2997.73
3 448031334588 948010335 2022-09-10 2022-08-09 ... EUR 4414.06 SMS 72.98
4 448031334588 948010335 2022-09-10 2022-08-09 ... EUR 4414.06 Other Fees 1997.31
... ... ... ... ... ... ... ... ... ...
799995 505213149067 403966656 2022-09-10 2022-08-09 ... EUR 6215.25 SMS 1674.42
799996 505213149067 403966656 2022-09-10 2022-08-09 ... EUR 6215.25 Other Fees 1309.07
799997 505213149067 403966656 2022-09-10 2022-08-09 ... EUR 6215.25 3rd Party Services 4261.38
799998 505213149067 403966656 2022-09-10 2022-08-09 ... EUR 6215.25 VAT Amount 1726.00
799999 505213149067 403966656 2022-09-10 2022-08-09 ... EUR 6215.25 Total Amount 8642.42
[800000 rows x 10 columns]
>>> df = pandas.read_parquet('invoices/numbers/2022-09-10-documents.parquet')
>>> df
INVOICE_NUMBER CUSTOMER_NUMBER INVOICE_DATE INVOICE_PERIOD_START_DATE ... PHONE_NUMBER_COUNTRY_CODE PHONE_NUMBER PHONE_LINE_CODE PHONE_LINE_AMOUNT
0 448031334588 948010335 2022-09-10 2022-08-09 ... 2 079861078 Tariff 6158.09
1 448031334588 948010335 2022-09-10 2022-08-09 ... 2 079861078 Data 2127.76
2 448031334588 948010335 2022-09-10 2022-08-09 ... 2 079861078 Voice 703.96
3 448031334588 948010335 2022-09-10 2022-08-09 ... 2 079861078 SMS 1159.15
4 448031334588 948010335 2022-09-10 2022-08-09 ... 2 079861078 Other Fees 140.69
... ... ... ... ... ... ... ... ... ...
3599763 505213149067 403966656 2022-09-10 2022-08-09 ... 0 733778861 SMS 1369.35
3599764 505213149067 403966656 2022-09-10 2022-08-09 ... 0 733778861 Other Fees 924.14
3599765 505213149067 403966656 2022-09-10 2022-08-09 ... 0 733778861 3rd Party Services 5353.98
3599766 505213149067 403966656 2022-09-10 2022-08-09 ... 0 733778861 VAT Amount 881.20
3599767 505213149067 403966656 2022-09-10 2022-08-09 ... 0 733778861 Total Amount 5995.91
[3599768 rows x 13 columns]
Final Notes
As you have seen OCI Data Integration is a great service for transforming complex JSON documents in Object Storage into flattened, normalized files in Parquet or ORC format. The transformation explained in this post can be easily included into an automated data processing pipeline and used in production processing of raw JSON files in a Data Lake.
In the post I have shown unnesting and projection of attributes from JSON objects and JSON arrays into flat structure, using Flatten and Expression operators. I could easily use other operators for more complex transformations, e.g., enriching the data set by joining reference data, aggregating metrics, or pivoting results. Also, the target could be database table instead of file in Object Storage.
Currently, the support for nested JSON documents is limited to source files in an Object Storage. JSON documents stored in a database such as Oracle Autonomous JSON Database are not supported. I hope this limitation will be removed in the future and the JSON processing will be applicable to all kind of data assets supported by OCI Data Integration.
Resources
- OCI Data Integration documentation is available here: OCI Data Integration Overview.
- Blog announcing the availability of Flatten operator is here: New Oracle Cloud Infrastructure Data Integration release