Options for Storing Large JSON Documents in Autonomous Database

Introduction
Many sources provide data in the form of JSON documents that are exchanged via Kafka, messaging middleware, or files. As the source JSON documents may be quite complex, it is a usual practice to store them in the staging area of the data warehouse, before they can be transformed and analyzed within the data processing pipeline. Most data warehouses support storage and processing of JSON documents alongside the relational data.
Using JSON to extend relational schemas is also a great approach for improving agility and flexibility of data warehouse models. The idea is simple - instead of creating complex relational model that covers all required attributes, we design a “minimal” relational model and put all the volatile and sparse attributes into a JSON column. Data from JSON column may be easily analyzed by SQL and if the structure is extended or changed, the relational model remains the same.
In this post I focus on storing, loading, and querying complex JSON documents in the Autonomous Data Warehouse (ADW), Oracle’s managed cloud database tuned and optimized for data warehouse workloads.
Specifically, I would like to find out if there is any difference in storage efficiency and load and query performance when using different storage options for complex JSON documents.
Test Configuration
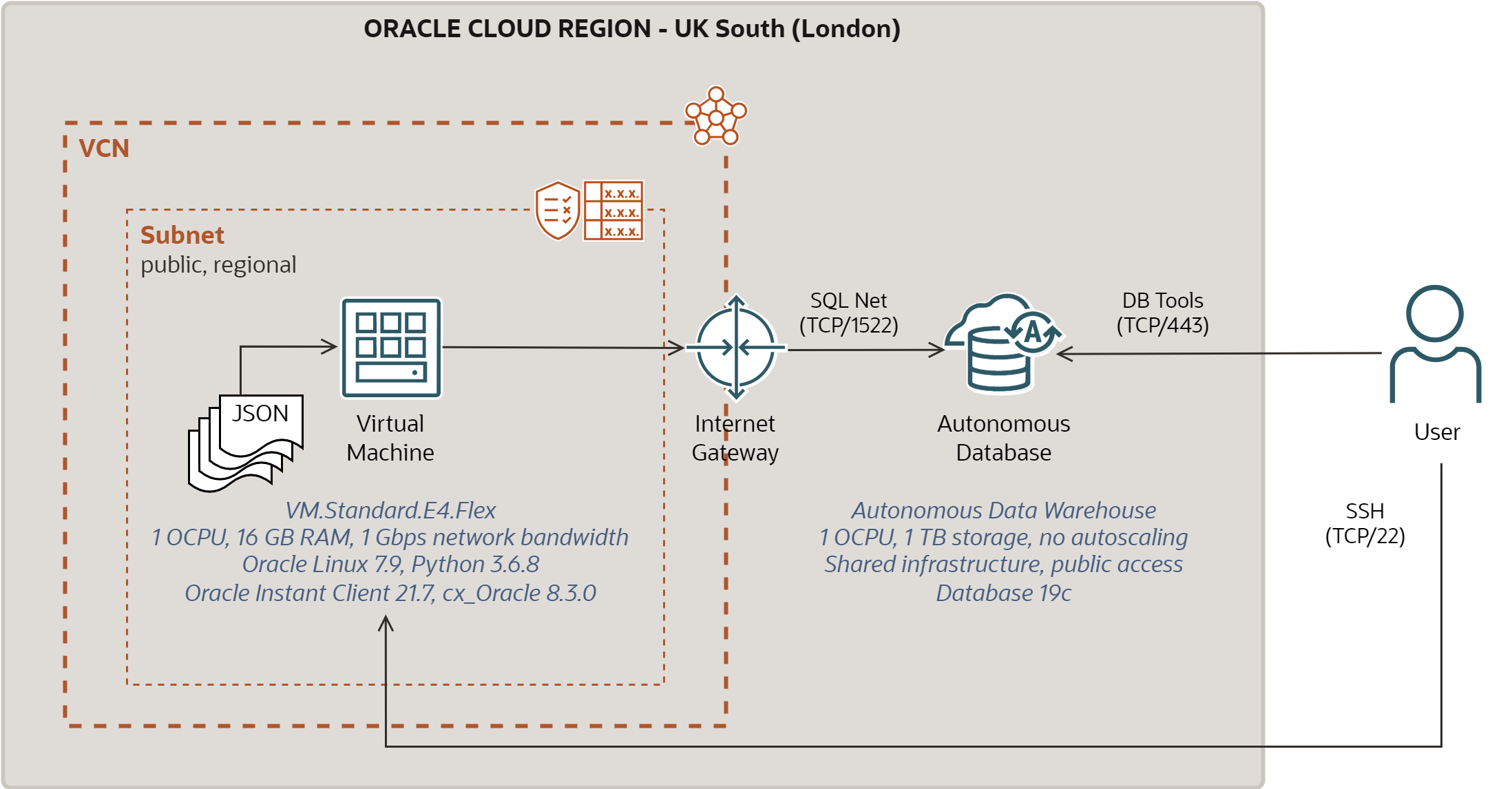
The Oracle Cloud configuration I used for this post is depicted below.
-
Oracle Compute instance is used as a client to load and query JSON data. The instance runs OL7 on E4-based AMD shape with 1 OCPU, 16 GB of RAM, and Block Storage based boot volume. The instance is in the public subnet and it may be accessed directly via ssh client from Internet. JSON documents are stored on the boot volume of the instance.
-
Autonomous Data Warehouse instance stores and queries JSON data. The instance is configured with 1 OCPU and 1 TB of storage (i.e., the minimal sizing). It runs 19c version of Oracle Database. Autoscaling is disabled. ADW instance is provisioned with the public access, so that it may be accessed directly via SQL Net client or Web Browser.
-
Both Compute and ADW instances were used only by the JSON testing; no other workloads were running on them.
Test Data
To compare JSON performance, I used artificially created JSON documents from a travel booking application. These are complex documents, with 5 levels of nesting and many objects and arrays. One document includes all information about a booking - contact information, passenger information, payment, destination, travel segments etc. A single JSON document is stored in a single file.
| Document type | Number of JSON Documents | Number of Files | Average document size | Largest document size | Total size |
|---|---|---|---|---|---|
| Booking record | 1 M | 1 M | 23 kB | 62 kB | 23 GB |
JSON Storage Options
Oracle Autonomous Database 19c supports the following storage formats for JSON columns:
-
VARCHAR2(4000) - recommended for small JSON documents not exceeding 4000 characters. These values are stored inline, with the rest of the row, and queries will benefit from Exadata pushdown processing.
-
VARCHAR2(32767) - recommended for JSON documents not exceeding 32767 characters. This option will also benefit from Exadata pushdown processing, as values smaller or equal 4000 characters will be stored inline.
-
CLOB - not recommended for JSON documents because with AL32UTF8 character set (default), the characters in CLOB require 2 bytes, even if they can be represented by single byte only.
-
BLOB - recommended for JSON documents that may exceed 32767 characters. BLOB may be stored either uncompressed or compressed with varying degree of compression (low, medium, high).
-
BLOB with optimized binary format OSON - this is new binary JSON format that was introduced in Oracle Database 21c and backported to Autonomous Database. It should provide the fastest query and update performance.
All these options require that table contains a check constraint IS JSON checking that
content is a valid JSON document. Note the default constraint applies a “lax” (i.e., less
strict) validation of JSON, however it is possible to define stricter validation in the
check constraint.
Additionally, Oracle Autonomous Database supports Simple Oracle Document Access (SODA), which allows applications to work with JSON documents using NoSQL-style API. With SODA, JSON documents are stored in Collections, with one Collection corresponding to one table. Collections use BLOB datatype with OSON format for storing of JSON documents.
Given the above constraints on storing JSON data and the test documents I am working with, I decided to test the following storage options:
1. JSON in BLOB column
create table json1 (
doc_id number not null,
doc_body blob,
constraint json1_pk primary key (doc_id),
constraint json1_check check (doc_body is json)
)
2. JSON in BLOB column with OSON format
create table json2 (
doc_id number not null,
doc_body blob,
constraint json2_pk primary key (doc_id),
constraint json2_check check (doc_body is json format oson)
)
3. JSON in BLOB column with OSON format and medium compression
create table json3 (
doc_id number not null,
doc_body blob,
constraint json3_pk primary key (doc_id),
constraint json3_check check (doc_body is json format oson)
)
lob(doc_body) store as (compress medium)
JSON Loading Approach
To load JSON documents into Autonomous Database, I used simple Python program utilizing
cx_Oracle library to communicate with Oracle Database. The program loads documents from
files into JSON tables one by one, committing work after every 100 records. It also allows
to run multiple instances of the program to test performance with multiple parallel
threads. Note that cx_Oracle supports both SQL and SODA interfaces.
Here is the code snippet to load JSON documents:
doc_id = 0
for entry in os.scandir(directory):
if entry.is_file() and entry.name.endswith('.json'):
with open(entry.path, 'r') as file:
doc_id = doc_id+1
doc_body = file.read()
cursor.execute( 'insert into {0} values (:1, :2)'.format(target), (doc_id, doc_body) )
connection.commit()
Sample Analytical Query
To test performance of accessing JSON documents in the Autonomous Database, I used a simple query that counts number of documents by two first level attributes. It queries all 1 million documents in a JSON table.
select /*+NO_RESULT_CACHE*/
to_char(created_date,'YYYY/MM/DD') as created_date, doc_status, count(*) as doc_count
from (
select jt.doc_status, to_date(jt.created_date,'YYYY-MM-DD"T"HH24:MI:SS') as created_date
from {0} j,
json_table(j.doc_body,'$' columns(
created_date path '$.createdDate',
doc_status path '$.docStatus'
) ) jt
)
group by to_char(created_date,'YYYY/MM/DD'), doc_status
order by to_char(created_date,'YYYY/MM/DD'), doc_status
Note I disabled Result Cache to have consistent results across multiple executions of the same query.
Test 1 - Storage Efficiency
The first test compares how much storage is required by different storage options.
| Scenario | Number of JSON documents | Size of source data | Size of TABLE segments | Size of LOB segments | Compression ratio |
|---|---|---|---|---|---|
| 1. JSON in BLOB column | 1 M | 23 GB | 59 MB | 29 GB | 0.79 x |
| 2. JSON in BLOB column with OSON format | 1 M | 23 GB | 59 MB | 20 GB | 1.15 x |
| 3. JSON in BLOB column with OSON format and medium compression | 1 M | 23 GB | 78 MB | 12 GB | 1.87 x |
And the graphical representation of JSON storage requirements is here, with the black line showing size of source documents.
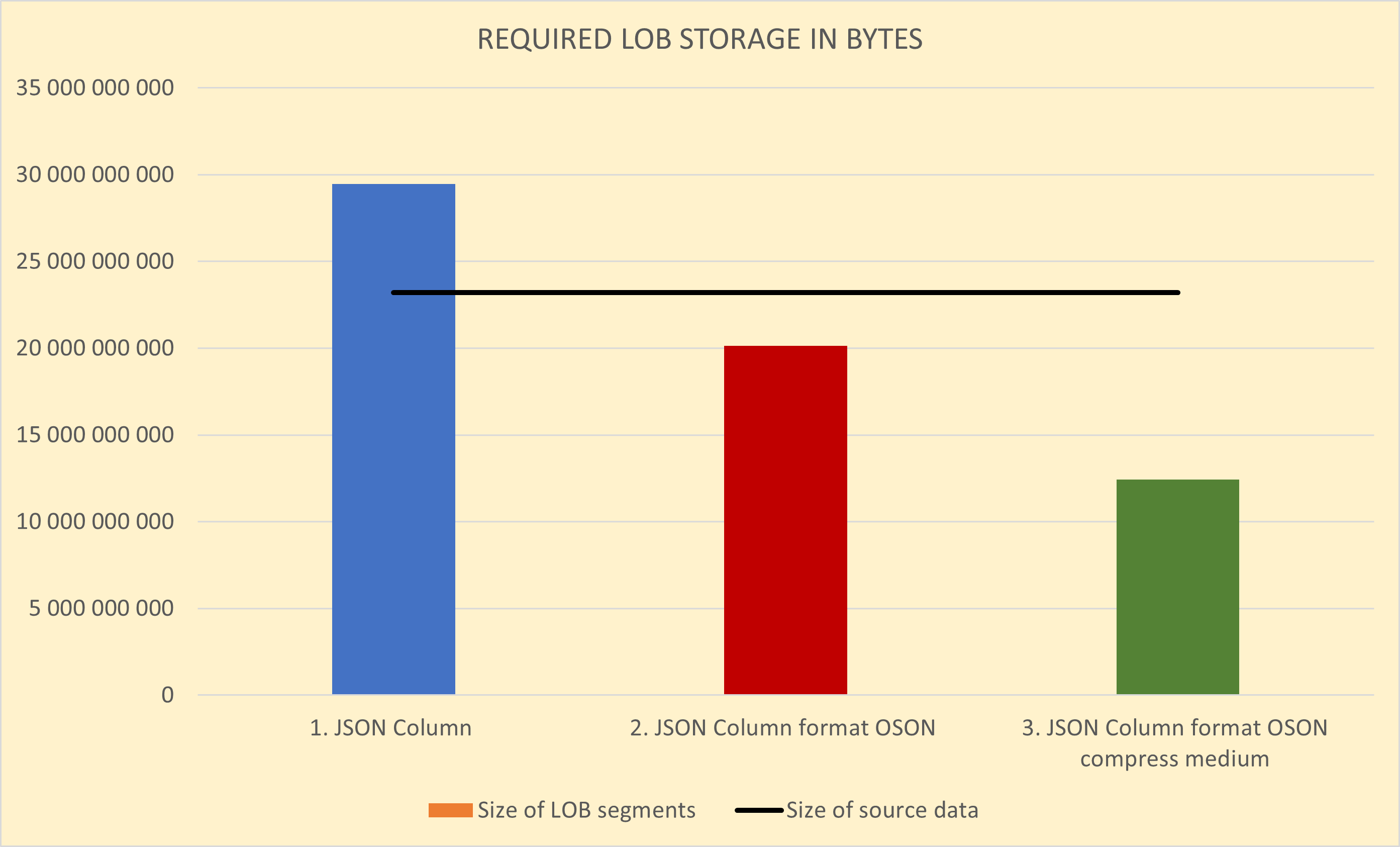
As you can see, the 2nd scenario with the new binary JSON format (OSON) is more than 30% efficient than storing JSON as text in BLOB columns. And when applying medium compression to BLOB columns in the 3rd scenario, we can furthermore decrease the storage to almost 50% of the size of source data.
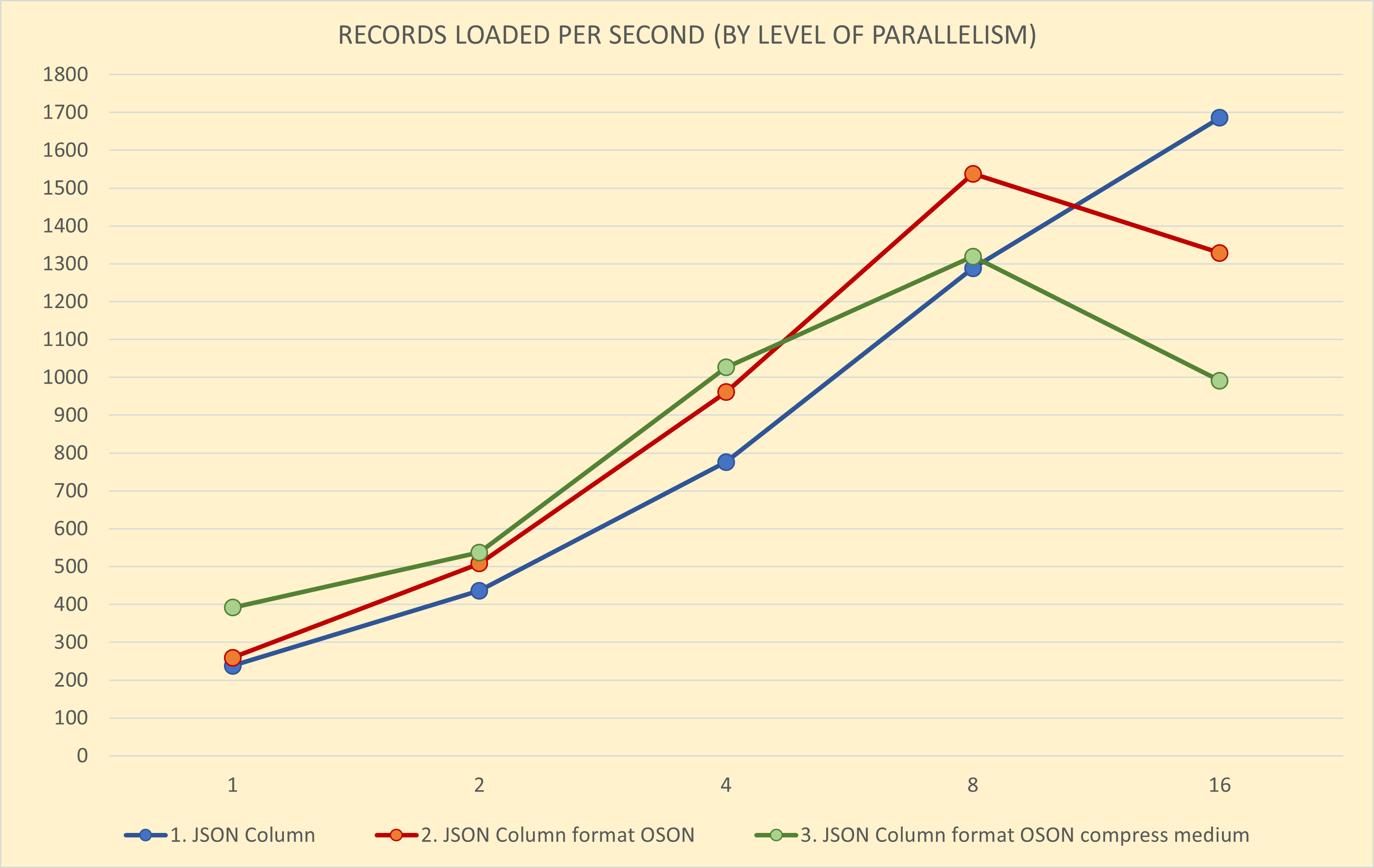
Test 2 - Load Performance
The second test compares load performance of different scenarios. For every combination of scenarios and levels of parallelism I loaded 1 million of JSON documents (23 GB in total) 5 times. The presented numbers are averages across the 5 executions.
| Scenario | Threads | Elapsed time | Records per second | Bytes per second | ADW CPU Utilization |
|---|---|---|---|---|---|
| 1. JSON in BLOB Column | 1 | 70 min | 238 | 6 MB | 12% |
| 2 | 38 min | 436 | 10 MB | 24% | |
| 4 | 21 min | 776 | 18 MB | 38% | |
| 8 | 13 min | 1288 | 30 MB | 64% | |
| 16 | 10 min | 1686 | 39 MB | 94% | |
| 2. JSON in BLOB column with OSON format | 1 | 64 min | 259 | 6 MB | 14% |
| 2 | 33 min | 508 | 12 MB | 37% | |
| 4 | 18 min | 961 | 22 MB | 52% | |
| 8 | 11 min | 1538 | 36 MB | 85% | |
| 16 | 13 min | 1329 | 31 MB | 99% | |
| 3. JSON in BLOB column with OSON format and medium compression | 1 | 43 min | 392 | 9 MB | 25% |
| 2 | 31 min | 537 | 12 MB | 36% | |
| 4 | 16 min | 1026 | 24 MB | 68% | |
| 8 | 13 min | 1319 | 31 MB | 95% | |
| 16 | 17 min | 991 | 23 MB | 98% |
And here you can see the load performance as a chart, with Records per second on the Y-axis and Threads (Level of Parallelism) on Y-axis.
And on this chart you can see average ADW CPU Utilization during the load. Compute CPU Utilization is not shown as it never reached more than 40% and the load was clearly not constraint by the Compute.
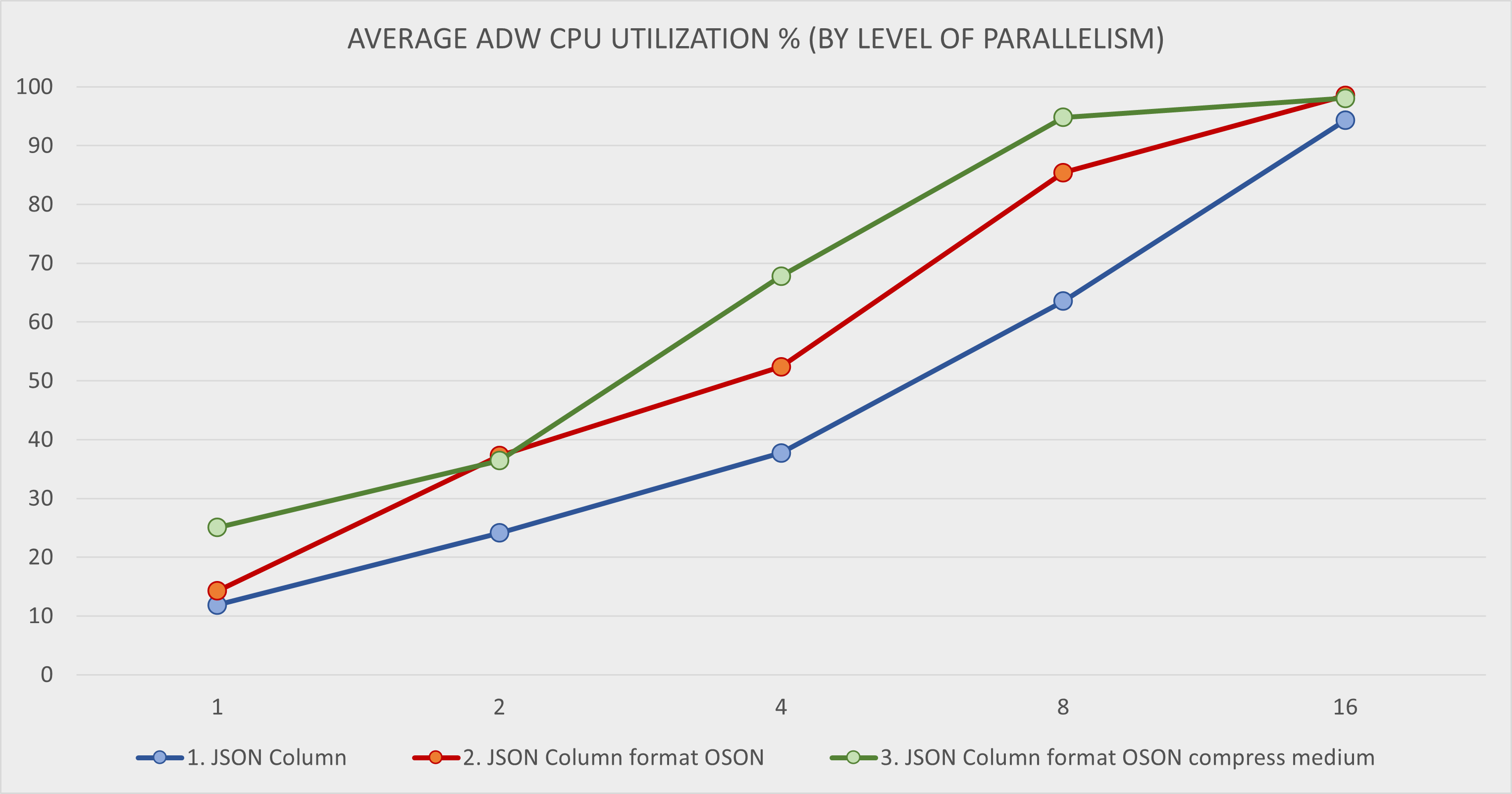
The 3rd scenario with JSON data in OSON format and medium compression provides the best load performance which scales well up to 8 parallel threads on 1 OCPU ADW instance. For more than 8 threads the performance deteriorates as the ADW instance becomes overloaded.
The 2nd scenario with JSON data in OSON format (uncompressed) provides slightly worse performance than 3rd scenario for 1 thread. However, for 2 and 4 threads it scales similarly as 3rd scenario, and it provides superior performance for 8 threads. For more than 8 threads, the performance also degrades.
The 1st scenario with JSON data in text format delivers worse load performance for 1, 2, and 4 threads than 2nd and 3rd scenarios with OSON format. Unlike them, it scales linearly up to 16 threads as it utilizes the ADW instance less than the previous scenarios.
Test 3 - Query Performance
The third test compares performance of simple analytical query against JSON data. It measures how long a query takes for different scenarios and levels of parallelism. For every thread the query was executed 8 times. Note the query has to read and parse all 1 million JSON documents to get the required results.
| Scenario | Threads | Elapsed time | Query duration | Number of queries | Queries per 10 minutes | ADW CPU Utilization |
|---|---|---|---|---|---|---|
| 1. JSON in BLOB Column | 1 | 76 min | 10 min | 8 | 1.05 | 26% |
| 2 | 74 min | 9 min | 16 | 2.17 | 49% | |
| 4 | 79 min | 10 min | 32 | 4.05 | 89% | |
| 8 | 151 min | 19 min | 64 | 4.24 | 99% | |
| 2. JSON in BLOB column with OSON format | 1 | 63 min | 8 min | 8 | 1.26 | 24% |
| 2 | 61 min | 8 min | 16 | 2.62 | 42% | |
| 4 | 73 min | 9 min | 32 | 4.40 | 72% | |
| 8 | 108 min | 13 min | 64 | 5.93 | 98% | |
| 3. JSON in BLOB column with OSON format and medium compression | 1 | 66 min | 8 min | 8 | 1.22 | 27% |
| 2 | 58 min | 7 min | 16 | 2.75 | 51% | |
| 4 | 62 min | 8 min | 32 | 5.19 | 90% | |
| 8 | 132 min | 16 min | 64 | 4.85 | 98% |
And here you can see the query performance as a chart, with Queries per 10 minutes on the Y-axis and Threads (Level of Parallelism) on Y-axis.
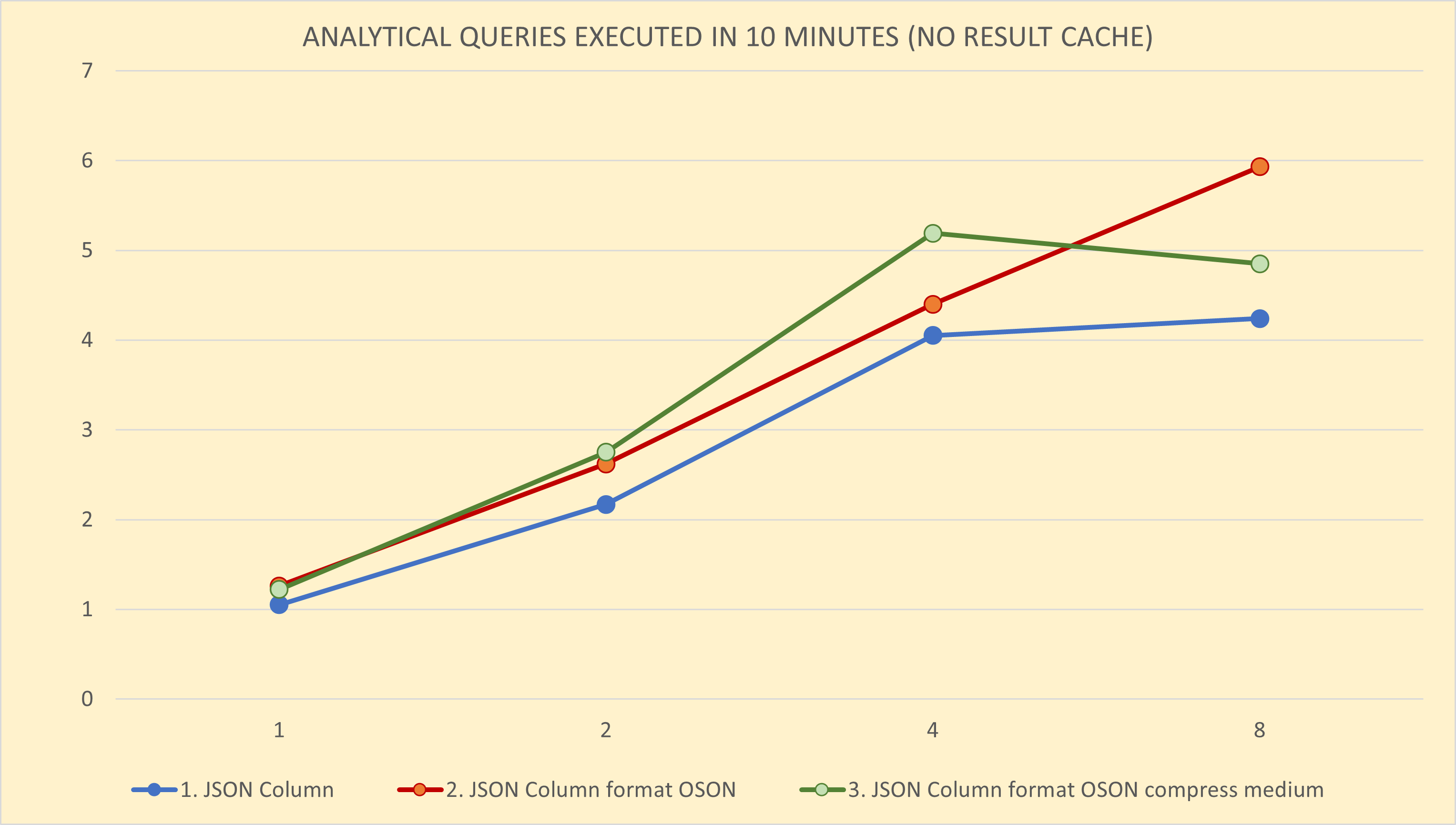
Average ADW CPU Utilization during the query testing is on the next chart. Single query requires approximately 25% of the ADW OCPU. Compute CPU Utilization is not shown as it was negligible (about 1%) - all the query processing was done by ADW.
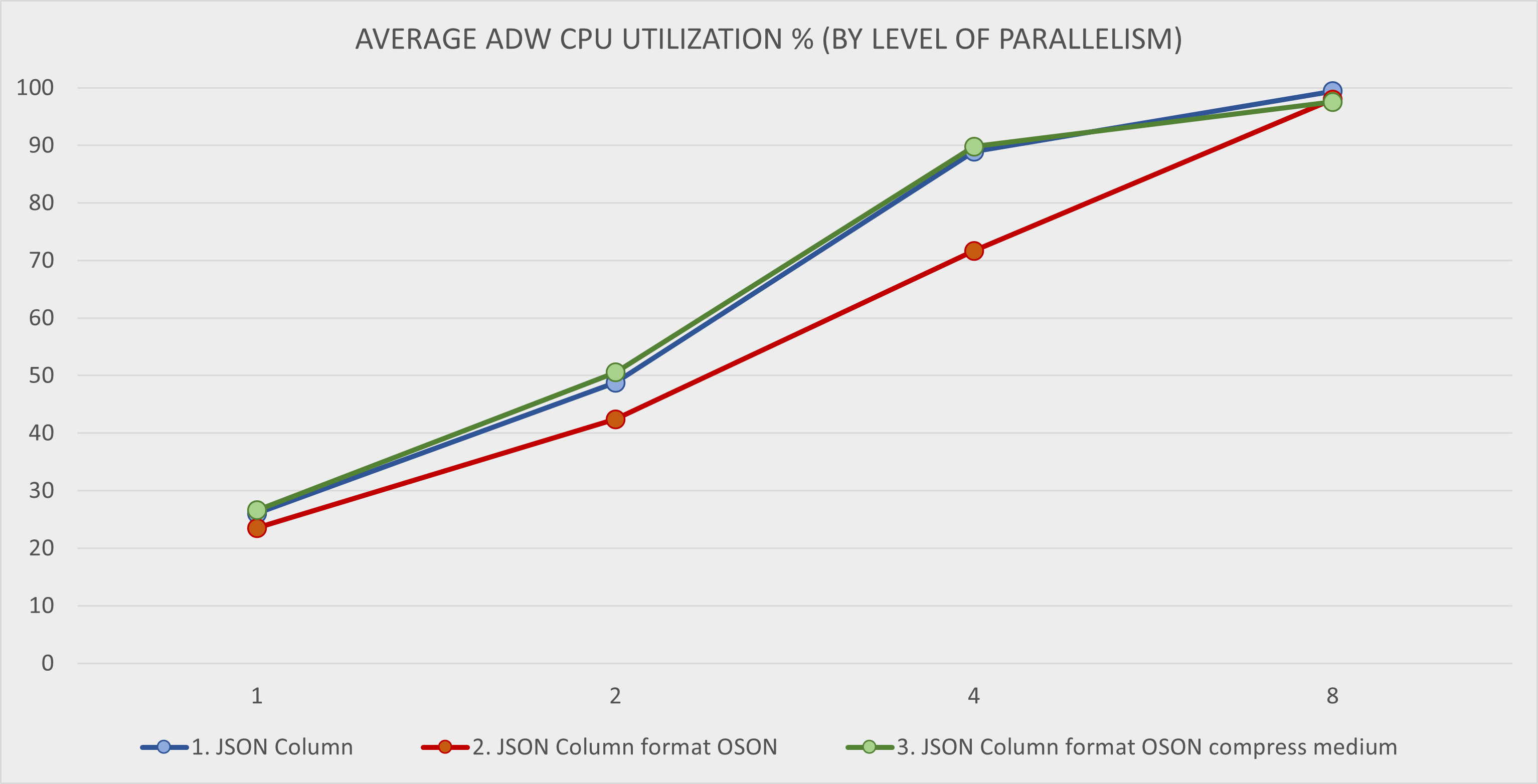
The 3rd scenario with JSON data in OSON format and medium compression provides the best query performance which scales well up to 4 parallel threads on 1 OCPU ADW instance. For more than 4 threads the performance deteriorates as the ADW instance is fully saturated.
The 2nd scenario with JSON data in OSON format (uncompressed) provides slightly worse performance than 3rd scenario for 2 and 4 threads. Furthermore, it scales up to 8 threads, unlike the 3rd scenario with medium compression.
The 1st scenario with JSON documents using text format delivers significantly lower query performace than the other scenarios. This is probably caused by the need to parse and process JSON documents for every query, while the binary OSON format provides optimized access path for fields within JSON.
Key Takeaways
-
A. Consider the new binary JSON format (OSON) instead of text format. The OSON format provides better query and load performance. It is also more storage efficient. Therefore I do not see any reason why not to start using OSON format for all large JSON documents.
-
B. Consider compression for JSON documents in BLOB columns. JSON documents in compressed BLOB column provide better or comparable load and query performance to uncompressed BLOB column while significantly reducing storage requirements. The only catch seems to be higher sensitivity to highly utilized systems, when the performance degrades faster then with the uncompressed storage.
-
C. Single ADW OCPU can support up to 4-8 sessions loading JSON documents. Depending on the storage format, single OCPU of ADW can support maximum of 4 to 8 concurrent sessions inserting large and complex JSON documents. More concurrent sessions will lead to degraded performance as the ADW instance becomes overutilized.
Note these messages are valid for the scenario presented in this post; i.e., for large, complex JSON documents which must be stored in BLOB columns. I strongly recommend testing the storage scenarios and measure the load and query throughput on your data as the results might differ.
Not Tested Scenarios
I did not test the following scenarios:
- Load and query performance of smaller JSON documents that can fit into VARCHAR2 columns.
- Comparing performance of queries against JSON field with queries against flattened relational tables.
- Performance of more complex queries requiring unnesting and flattening of JSON documents.
- Performance of OLTP queries with where conditions on JSON fields.
- Storage requirements and load performance with indexed JSON columns.
- Load and query performance with ADW instance using 2 and more OCPUs or with Autoscaling enabled.
- Load performance of JSON Collection.
- Load performance of mix of Insert and Update operations.
I hope to return to these scenarios in some of the following posts.